Linux I/O體系是Linux內核的重要組成部分,主要包含網絡IO、磁盤IO等。基本所有的技術棧都需要與IO打交道,分布式存儲系統更是如此。本文主要簡單分析一下磁盤IO,看看一個IO請求從發起到完成到底經歷了哪些流程。
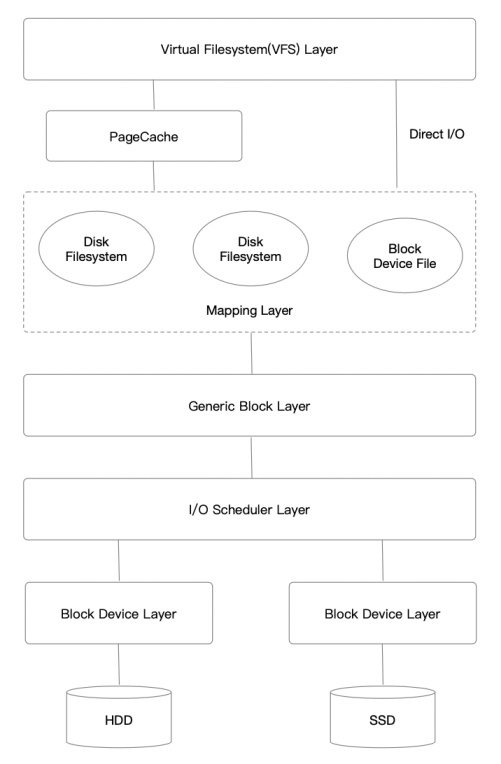
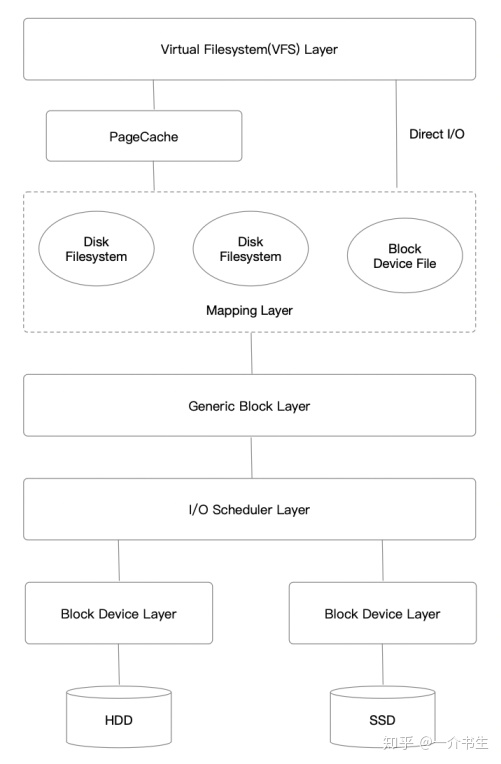
Buffered I/O:緩存IO又叫標準IO,是大多數文件系統的默認IO操作,經過PageCache。Direct I/O:直接IO,By Pass PageCache。offset、length需對齊到block_size。Sync I/O:同步IO,即發起IO請求后會阻塞直到完成。緩存IO和直接IO都屬于同步IO。Async I/O:異步IO,即發起IO請求后不阻塞,內核完成后回調。通常用內核提供的Libaio。Write Back:Buffered IO時,僅僅寫入PageCache便返回,不等數據落盤。Write Through:Buffered IO時,不僅僅寫入PageCache,而且同步等待數據落盤。我們先看一張總的Linux內核存儲棧圖片:
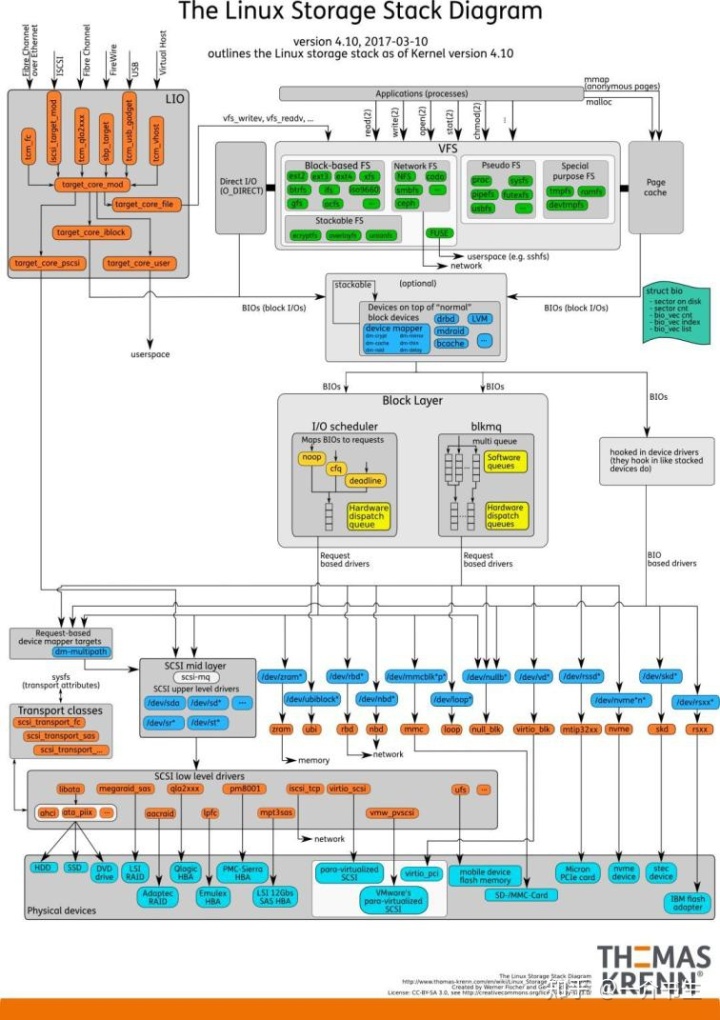
Linux IO存儲棧主要有以下7層:
UNIX/LINUX。
我們通常使用open、read、write等函數來編寫Linux下的IO程序。接下來我們看看這些函數的IO棧是怎樣的。在此之前我們先簡單分析一下VFS層的4個對象,有助于我們深刻的理解IO棧。
VFS層的作用是屏蔽了底層不同的文件系統的差異性,為用戶程序提供一個統一的、抽象的、虛擬的文件系統,提供統一的對外API,使用戶程序調用時無需感知底層的文件系統,只有在真正執行讀寫操作的時候才調用之前注冊的文件系統的相應函數。
VFS支持的文件系統主要有三種類型:
VFS主要有四個對象類型(不同的文件系統都要實現):
struct super_operations。struct inode_operations。struct dentry_operations。struct file_operations。關于VFS相關結構體的定義都在include/linux/fs.h里面。
linux內核最早是由誰開發的?superblock結構體定義了整個文件系統的元信息,以及相應的操作。
https://github.com/torvalds/linux/blob/v4.16/fs/xfs/xfs_super.c#L1789
static const struct super_operations xfs_super_operations = {......
};static struct file_system_type xfs_fs_type = {.name = "xfs",......
};
inode結構體定義了文件的元數據,比如大小、最后修改時間、權限等,除此之外還有一系列的函數指針,指向具體文件系統對文件操作的函數,包括常見的open、read、write等,由i_fop函數指針提供。
文件系統最核心的功能全部由inode的函數指針提供。主要是inode的i_op、i_fop字段。
struct inode {......// inode 文件元數據的函數操作const struct inode_operations *i_op;// 文件數據的函數操作,open、write、read等const struct file_operations *i_fop;......
}
在設置inode的i_fop時候,會根據不同的inode類型設置不同的i_fop。我們以xfs為例:
https://github.com/torvalds/linux/blob/v4.16/fs/xfs/xfs_iops.c#L1266
linux最新內核版本是多少,https://github.com/torvalds/linux/blob/v4.16/fs/inode.c#L1980
如果inode類型為普通文件的話,那么設置XFS提供的xfs_file_operations。
如果inode類型為塊設備文件的話,那么設置塊設備默認提供的def_blk_fops。
void xfs_setup_iops(struct xfs_inode *ip)
{struct inode *inode = &ip->i_vnode;switch (inode->i_mode & S_IFMT) {case S_IFREG:inode->i_op = &xfs_inode_operations;// 在IO棧章節會分析一下xfs_file_operationsinode->i_fop = &xfs_file_operations;inode->i_mapping->a_ops = &xfs_address_space_operations;break;......default:inode->i_op = &xfs_inode_operations;init_special_inode(inode, inode->i_mode, inode->i_rdev);break;}
}void init_special_inode(struct inode *inode, umode_t mode, dev_t rdev)
{inode->i_mode = mode;......if (S_ISBLK(mode)) {// 塊設備相應的系列函數inode->i_fop = &def_blk_fops;inode->i_rdev = rdev;}......
}
dentry是目錄項,由于每一個文件必定存在于某個目錄內,我們通過路徑查找一個文件時,最終肯定找到某個目錄項。在Linux中,目錄和普通文件一樣,都是存放在磁盤的數據塊中,在查找目錄的時候就讀出該目錄所在的數據塊,然后去尋找其中的某個目錄項。
struct dentry {......const struct dentry_operations *d_op;......
};
在我們使用Linux的過程中,根據目錄查找文件的例子無處不在,而目錄項的數據又都是存儲在磁盤上的,如果每一級路徑都要讀取磁盤,那么性能會十分低下。所以需要目錄項緩存,把dentry放在緩存中加速。
VFS把所有的dentry放在dentry_hashtable哈希表里面,使用LRU淘汰算法。
linux內核多大。用戶程序能接觸的VFS對象只有file,由進程管理。我們常用的打開一個文件就是創建一個file對象,并返回一個文件描述符。出于隔離性的考慮,內核不會把file的地址返回,而是返回一個整形的fd。
struct file {// 操作文件的函數指針,和inode里面的i_fop一樣,在open的時候賦值為i_fop。const struct file_operations *f_op;// 指向對應inode對象struct inode *f_inode;// 每個文件都有自己的一個偏移量loff_t f_pos;......
}
file對象是由內核進程直接管理的。每個進程都有當前打開的文件列表,放在files_struct結構體中。
struct files_struct {......struct file __rcu * fd_array[NR_OPEN_DEFAULT];......
};
fd_array數組存儲了所有打開的file對象,用戶程序拿到的文件描述符(fd)實際上是這個數組的索引。
https://github.com/torvalds/linux/blob/v4.16/fs/read_write.c#L566
SYSCALL_DEFINE3(read, unsigned int, fd, char __user *, buf, size_t, count)
{......ret = vfs_read(f.file, buf, count, &pos);......return ret;
}
SYSCALL_DEFINE3(write, unsigned int, fd, char __user *, buf, size_t, count)
{......ret = vfs_write(f.file, buf, count, &pos);......return ret;
}
由此可見,我們經常使用的read、write系統調用實際上是對vfs_read、vfs_write的一個封裝。
size_t vfs_read(struct file *file, char __user *buf, size_t count, loff_t *pos)
{......if (file->f_op->read) ret = file->f_op->read(file, buf, count, pos);elseret = do_sync_read(file, buf, count, pos);......
}
ssize_t vfs_write(struct file *file, const char __user *buf, size_t count, loff_t *pos)
{......if (file->f_op->write)ret = file->f_op->write(file, buf, count, pos); elseret = do_sync_write(file, buf, count, pos);......
}
我們發現,VFS會調用具體的文件系統的實現:file->f_op->read、file->f_op->write。
如何查看linux內核版本、對于通用的文件系統,Linux封裝了很多基本的函數,很多文件系統的核心功能都是以這些基本的函數為基礎,再封裝一層。接下來我們以XFS為例,簡單分析一下XFS的read、write都做了什么操作。
https://github.com/torvalds/linux/blob/v4.16/fs/xfs/xfs_file.c#L1137
const struct file_operations xfs_file_operations = {.......llseek = xfs_file_llseek,.read = do_sync_read,.write = do_sync_write,// 異步IO,在之后的版本中名字為read_iter、write_iter。.aio_read = xfs_file_aio_read,.aio_write = xfs_file_aio_write,.mmap = xfs_file_mmap,.open = xfs_file_open,.fsync = xfs_file_fsync,......
};
這是XFS的f_op函數指針表,我們可以看到read、write函數直接使用了內核提供的do_sync_read、do_sync_write函數。
ssize_t do_sync_read(struct file *filp, char __user *buf, size_t len, loff_t *ppos)
{......ret = filp->f_op->aio_read(&kiocb, &iov, 1, kiocb.ki_pos);......
}
ssize_t do_sync_write(struct file *filp, const char __user *buf, size_t len, loff_t *ppos)
{......ret = filp->f_op->aio_write(&kiocb, &iov, 1, kiocb.ki_pos);......
}
這兩個函數最終也是調用了具體文件系統的aio_read和aio_write函數,對應XFS的函數為xfs_file_aio_read和xfs_file_aio_write。
xfs_file_aio_read和xfs_file_aio_write雖然有很多xfs自己的實現細節,但其核心功能都是建立在內核提供的通用函數上的:xfs_file_aio_read最終會調用generic_file_aio_read函數,xfs_file_aio_write最終會調用generic_perform_write函數,這些通用函數是基本上所有文件系統的核心邏輯。
接下來便要進入PageCache層的相關邏輯了,我們先簡單概括一下讀寫多了哪些事情。
linux內核源碼詳解、generic_file_aio_read:
generic_perform_write:
使用Buffered IO時,VFS層的讀寫很大程度上是依賴于PageCache的,只有當Cache-Miss,Cache過滿等才會涉及到磁盤的操作。
我們在使用Direct IO時,通常搭配Libaio使用,避免同步IO阻塞程序。而往往Direct IO + Libaio應用于裸設備的場景,盡量不要應用于文件系統中的文件,這時仍然會有文件系統的種種開銷。
通常Direct IO + Libaio使用的場景有幾種:
上面基本都是普通文件的讀寫,我們通常的使用場景中還有一種特殊的文件即塊設備文件(/dev/sdx),這些塊設備文件仍然由VFS層管理,相當于一個特殊的文件系統。當進程訪問塊設備文件時,直接調用設備驅動程序提供的相應函數,默認的塊設備函數列表如下:
const struct file_operations def_blk_fops = {.......open = blkdev_open,.llseek = block_llseek,.read = do_sync_read,.write = do_sync_write,.aio_read = blkdev_aio_read,.aio_write = blkdev_aio_write,.mmap = generic_file_mmap,.fsync = blkdev_fsync,......
};
Linux 內核、使用Direct IO + Libaio + 裸設備時,VFS層的函數指針會指向裸設備的def_blk_fops。因為我們通常使用DIO+Libaio+裸設備,所以我們簡單分析一下Libaio的IO流程。
Libaio提供了5個基本的方法,只能以DIO的方式打開,否則可能會進行Buffered IO。
io_setup, io_cancal, io_destroy, io_getevents, io_submit
Linux內核AIO的實現在https://github.com/torvalds/linux/blob/v4.16/fs/aio.c,我們簡單分析一下io_submit的操作。
SYSCALL_DEFINE3(io_submit, aio_context_t, ctx_id, long, nr,struct iocb __user * __user *, iocbpp)
{return do_io_submit(ctx_id, nr, iocbpp, 0);
}
long do_io_submit(aio_context_t ctx_id, long nr,struct iocb __user *__user *iocbpp, bool compat){...for (i=0; i<nr; i++) {ret = io_submit_one(ctx, user_iocb, &tmp, compat);}...
}
static int io_submit_one(struct kioctx *ctx, struct iocb __user *user_iocb,struct iocb *iocb, bool compat){...ret = aio_run_iocb(req, compat);...
}
static ssize_t aio_run_iocb(struct kiocb *req, bool compat){...case IOCB_CMD_PREADV:rw_op = file->f_op->aio_read;case IOCB_CMD_PWRITEV:rw_op = file->f_op->aio_write;...
}
可以發現,最終也是調用f_op的aio_read函數,對應于文件系統的文件就是xfs_file_aio_read函數,對應于塊設備文件就是blkdev_aio_read函數,然后進入通用塊層,放入IO隊列,進行IO調度。由此可見Libaio的隊列也就是通用塊層之下的IO調度層中的隊列。
在HDD時代,由于內核和磁盤速度的巨大差異,Linux內核引入了頁高速緩存(PageCache),把磁盤抽象成一個個固定大小的連續Page,通常為4K。對于VFS來說,只需要與PageCache交互,無需關注磁盤的空間分配以及是如何讀寫的。
當我們使用Buffered IO的時候便會用到PageCache層,與Direct IO相比,用戶程序無需offset、length對齊。是因為通用塊層處理IO都必須是塊大小對齊的。
shell逐行讀取文件、Buffered IO中PageCache幫我們做了對齊的工作:如果我們修改文件的offset、length不是頁大小對齊的,那么PageCache會執行RMW的操作,先把該頁對應的磁盤的數據全部讀上來,再和內存中的數據做Modify,最后再把修改后的數據寫回磁盤。雖然是寫操作,但是非對齊的寫仍然會有讀操作。
Direct IO由于跳過了PageCache,直達通用塊層,所以需要用戶程序處理對齊的問題。
如果發生機器宕機,位于PageCache中的數據就會丟失;所以僅僅寫入PageCache是不可靠的,需要有一定的策略將數據刷入磁盤。通常有幾種策略:
Linux內核目前的做法是為每個磁盤都建立一個線程,負責每個磁盤的刷盤。
從VFS層我們知道寫是異步的,寫完PageCache便直接返回了;但是讀是同步的,如果PageCache沒有命中,需要從磁盤讀取,很影響性能。如果是順序讀的話PageCache便可以進行預讀策略,異步讀取該Page之后的Page,等到用戶程序再次發起讀請求,數據已經在PageCache里,大幅度減少IO的次數,不用阻塞讀系統調用,提升讀的性能。
映射層是在PageCache之下的一層,由多個文件系統(Ext系列、XFS等,打開文件系統的文件)以及塊設備文件(直接打開裸設備文件)組成,主要完成兩個工作:
linux最新內核、由于通用塊層以及之后的的IO都必須是塊大小對齊的,我們通過DIO打開文件時,略過了PageCache,所以必須要自己將IO數據的offset、length對齊到塊大小。
我們使用的DIO+Libaio直接打開裸設備時,跳過了文件系統,少了文件系統的種種開銷,然后進入通用塊層,繼續之后的處理。
通用塊層存在的意義也和VFS一樣,屏蔽底層不同設備驅動的差異性,提供統一的、抽象的通用塊層API。
通用塊層最核心的數據結構便是bio,描述了從上層提交的一次IO請求。
https://github.com/torvalds/linux/blob/v4.16/include/linux/blk_types.h#L96
struct bio {......// 要提交到磁盤的多段數據struct bio_vec *bi_io_vec;// 有多少段數據unsigned short bi_vcnt;......
}
struct bio_vec {struct page *bv_page;unsigned int bv_len;unsigned int bv_offset;
};
所有到通用塊層的IO,都要把數據封裝成bio_vec的形式,放到bio結構體內。
合理內核是、在VFS層的讀請求,是以Page為單位讀取的,如果改Page不在PageCache內,那么便要調用文件系統定義的read_page函數從磁盤上讀取數據。
const struct address_space_operations xfs_address_space_operations = {.......readpage = xfs_vm_readpage,.readpages = xfs_vm_readpages,.writepage = xfs_vm_writepage,.writepages = xfs_vm_writepages,......
};
Linux調度層是Linux IO體系中的一個重要組件,介于通用塊層和塊設備驅動層之間。IO調度層主要是為了減少磁盤IO的次數,增大磁盤整體的吞吐量,會隊列中的多個bio進行排序和合并,并且提供了多種IO調度算法,適應不同的場景。
Linux內核為每一個塊設備維護了一個IO隊列,item是struct request結構體,用來排隊上層提交的IO請求。一個request包含了多個bio,一個IO隊列queue了多個request。
struct request {......// total data lenunsigned int __data_len;// sector cursorsector_t __sector;// first biostruct bio *bio;// last biostruct bio *biotail;......
}
上層提交的bio有可能分配一個新的request結構體去存放,也有可能合并到現有的request中。
Linux內核目前提供了以下幾種調度策略:
每一類設備都有其驅動程序,負責設備的讀寫。IO調度層的請求也會交給相應的設備驅動程序去進行讀寫。大部分的磁盤驅動程序都采用DMA的方式去進行數據傳輸,DMA控制器自行在內存和IO設備間進行數據傳送,當數據傳送完成再通過中斷通知CPU。
fread循環讀取一個文件、通常塊設備的驅動程序都已經集成在了kernel里面,也即就算我們直接調用塊設備驅動驅動層的代碼還是要經過內核。
spdk實現了用戶態、異步、無鎖、輪詢方式NVME驅動程序。塊存儲是延遲非常敏感的服務,使用NVME做后端存儲磁盤時,便可以使用spdk提供的NVME驅動,縮短IO流程,降低IO延遲,提升IO性能。
物理設備層便是我們經常使用的HDD、SSD、NVME等磁盤設備了。
Buffered IO:write返回數據僅僅是寫入了PageCache,還沒有落盤。
Direct IO:write返回數據僅僅是到了通用塊層放入IO隊列,依舊沒有落盤。
此時設備斷電、宕機仍然會發生數據丟失。需要調用fsync或者fdatasync把數據刷到磁盤上,調用命令時,磁盤本身緩存(DiskCache)的內容也會持久化到磁盤上。
fread判斷讀到文件尾、write系統調用不是原子的,如果有多線程同時調用,數據可能會發生錯亂。可以使用O_APPEND標志打開文件,只能追加寫,這樣多線程寫入就不會發生數據錯亂。
mmap直接把PageCache映射到用戶態,少了一次系統調用,也少了一次數據在用戶態和內核態的拷貝。
mmap通常和read搭配使用:寫入使用write+sync,讀取使用mmap。
DIO跳過了PageCache,直接到通用塊層,而通用塊層的IO都必須是塊大小對齊的,所以需要用戶程序自行對齊offset、length。
write()--->sys_write()--->vfs_write()--->通用塊層--->IO調度層--->塊設備驅動層--->塊設備
當應用程序不滿Linux內核的Cache策略,有更適合自己的Cache策略時可以使用Direct IO跳過PageCache。例如Mysql。
當應用程序對延遲極度敏感時,由于Linux內核IO棧有7層,IO路徑比較長,為了縮短IO路徑,降低IO延遲,可以by pass kernel,直接使用用戶態的塊設備驅動程序。例如spdk的nvme,阿里云的ESSD。
linux內核開發,當應用程序僅僅使用了基本的read、write,用不到文件系統的大而全的功能,此時文件系統的開銷對于應用程序來說是一種累贅,此時需要跳過文件系統,接管裸設備,自己實現磁盤分配、緩存等功能,通常使用DIO+Libaio+裸設備。例如Ceph FileStore的Journal、Ceph BlueStore。
版权声明:本站所有资料均为网友推荐收集整理而来,仅供学习和研究交流使用。

工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态