本文是吳恩達深度學習第三課:如何構建你的機器學習項目,也就是機器學習策略。從這次課程中可以學到如何診斷在機器學習系統中的錯誤、知道如何最有效的減少錯誤、懂得復雜的機器學習設置,比如錯開的訓練/測試集和如何和人類水平的表現進行比較、知道如何應用端到端學習,遷移學習和多任務學習。
第三課有以下兩個部分,本文是第一部分。

假設你正在調試你的貓分類器,經過一段時間的調試,你的系統有90%的準確率,但是對你的應用還不夠好,你可能有很多改善系統的想法。
比如說,
你可能想嘗試很多想法,但是如果嘗試的方向不對,完全有可能白白浪費時間往錯誤的方向推進。
如果有快速有效的方法能判斷哪些想法是靠譜的,甚至提出新的想法。本文就來告訴大家一些分析機器學習問題的方法,可以指引大家朝著最有希望的方向前進。
從上面可以看到,我們可以嘗試的東西太多了,有時候選擇太多了也不好,不知道從何下手。
本節告訴大家如何清晰的知道要調整什么。

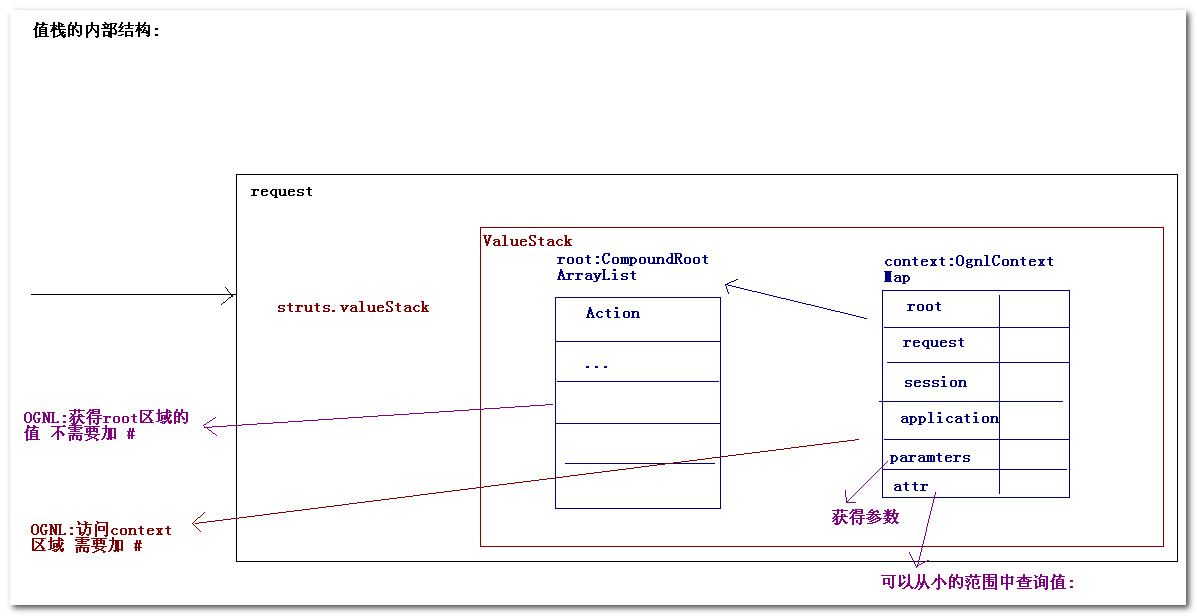
這里用老式電視和小車為例,老式電視會有一些按鈕來調節電視的畫面。比如一個按鈕調整寬度,另一個按鈕調整高度,還有其他按鈕可以旋轉屏幕。
相比之下,如果有一個按鈕調整的是0.1×0.1 \times0.1×圖像高度 $ + 0.3 \times$圖像寬度 $ - 1.7 \times$梯形角度等。即用一個按鈕能微調所有的功能,如果有這樣的按鈕,幾乎無法把電視調好,比如為了調高度,不得不影響其他屬性。
在這種情況下,正交化指的是上面設計的按鈕,使得旋轉每個按鈕只能調整一個屬性。
小車的例子說一輛車的移動由方向盤、油門和剎車控制,它們一次也只能調整一個屬性,也是正交化的。
所以正交化指的是,一個方向只能改變一個性質。

比如你不能同時改變方向盤的角度和汽車的速度,這樣很難讓汽車以你想要的速度和角度前進。這里正交意味著互為90°。
這和機器學習有什么關系呢,要弄好一個監督學習系統,通常需要確保四件事情。

和電視例子一樣,如果你的算法不能很好的擬合訓練集,你可能想要一個(組)按鈕來調整你的算法,讓它能很好地擬合訓練集。
來調整的按鈕可能是訓練更大的網絡、切換到更好的優化算法等等。
相比之下,如果發現算法對驗證集的擬合很差,那么也應該有一組獨立的按鈕來改善這種情況。
此時,假設算法已經在訓練集上表現很好了,這是你的按鈕可能是正則化、增大訓練集(可以更好的歸納驗證集的規律)。
像電視例子一樣,假設現在調好了電視圖像的高度和寬度,如果系統在驗證集上做的很好,但在測試集上做得不好呢? 那么需要的按鈕可能是更大的驗證集(因為此時可能對驗證集過擬合了)。
最后,如果在測試集上做得很好,但是在現實世界里的表現不行,比如一旦用戶上傳了自己的貓照片,你的分類器就無法準確識別出來。
這意味著你需要回去改變驗證集或成本函數,因為如果根據某個成本函數,系統在驗證集上做的很好,但無法反映算法在現實世界中的表現,這意味著要么驗證集分布設置的不正確,可能驗證集設置的是網絡抓取的精美圖片,而現實世界上用戶拿自己的手機任意拍攝的圖像。要么是成本函數策略的指標不對,可能測量的是圖像的亮度。
現在我們應該清楚了如果機器學習算法出了問題,到底是上面四個問題中的哪一個,知道如何去調整。
值得指出的是,早停法(early stopping)這里沒用到,因為早停法會同時影響(一般是抑制)對訓練集的擬合和改善對開發集的表現。
它違背了我們說的正交化。
無論是調整超參數,或者是嘗試不同的算法,你會發現如果有一個單實數評估指標,你的進展會快得多。
下面來看一個例子,假設對于之前的貓分類器,實現了兩個不同的模型(可能是同一個算法,但是參數不同;或者是兩個不同的算法)。
評估你分類器的一個合理方式是使用查準率(準確率-Precision)和查全率(召回率-Recall)。
| 真實情況↓\模型預測→ | True | False |
|---|---|---|
True | TP | FN |
False | FP | TN |
其中,查準率:
P=TPTP+FPP= \frac{TP}{TP +FP} P=TP+FPTP?
查全率:
R=TPTP+FNR= \frac{TP}{TP +FN} R=TP+FNTP?
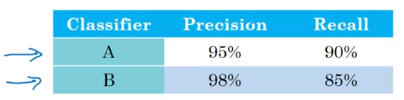
查準率說的是分類器標記為貓的例子中有多少是真的是貓。
所以分類器A有95%的查準率意味著分類器A說某張圖片里有貓的時候,有95%的機會真的是貓。
查全率就是對于所有真貓圖片,你的分類器正確識別出了多少。
所以分類器A查全率是90%,意味著對于所有的貓圖片,分類器A準確地分辨出了其中的90%。
事實證明,查準率和查全率之間往往需要折衷。如果你考慮兩者的話,你希望當你的分類器說某張圖中有貓的時候,有很大的概率里面真的有一只貓。
但是對于所有的貓圖片,你也希望系統能夠將大部分都識別出來。
現在有個問題是,分類器A在查全率是表現得更好;而分類器B在查準率上表現的更好。
此時你無法判斷哪個分類器更好,所以需要一個新的評估指標能結合查準率和查全率。
就是F1值(F1 score),是查準率和查全率的調和均值,
F1=21P+1RF_1 = \frac{2}{\frac{1}{P} + \frac{1}{R}} F1?=P1?+R1?2?

在這個例子中,我們可以看到分類器A的F1值更高。
所以有一個明確的驗證集加上一個單實數評估指標 就能快速的判斷哪個分類器更好。
下面來看另一個例子,假設開發一個應用,用戶是四個地址大區的愛貓人士。

假設上面是不同的分類器在不同的大區上得到的誤差率。我們很難直接根據上面的數字判斷出哪個分類器更好。

如果分類器更多的話,就更難了。

所以建議除了計算每個區的錯誤率外,還額外計算一下平均值。
這里假設平均值是一個合理的單實數評估指標,這樣我們就能快速知道哪個分類器更好。
這里分類器C的平均誤差率最低。
此時我們就可以繼續優化分類器C。
有時要把所有的東西組合成單實數評估指標并不容易。在這種情況中,有時設立滿足和優化指標是很有用的。
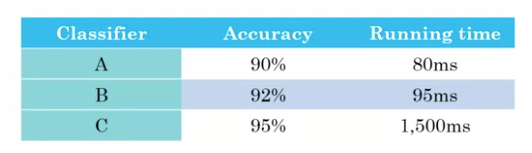
假設在這個例子中你關注的是貓分類器的準確率(可以是F1值或其他精確度量)和運行時間。
這里分類器A需要80毫秒來識別一副圖像,B需要95毫秒,而C需要1.5秒。
你當然可以將它們組合成線性關系來作為整體評價指標。
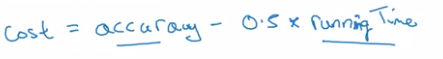
假設對運行時間有硬性要求,還可以這樣:

比如說運行時間必須小于100毫秒,在這個條件下你希望準確率越高越好。
這里運行時間就是我們說的滿足指標(Satisficing), 優化(Optimizing) 是準確率越高越好。
這種方式是對準確率和運行時間進行合理的通盤考慮。
通過定義優化以及滿足指標,我們就有了挑選最優分類器的明確方向。
這上面的例子中最優的是分類器B。
更一般的說,如果你有N個關心的指標,有時候選擇其中一個加以優化是個合理的策略,剩下的N-1個就是滿足指標,意味著它們只要達到某個閾值就可以了。
下面舉另一個例子,假設你要做喚醒詞系統。
就是你好小度,HI siri。
這就是你喚醒某個聲控設備所用的語句。
因此你可能關心喚醒詞系統的準確率,就是某人說了某個喚醒詞,實際上能喚醒你的設備的可能性有多大。
也有可能會關心FP的次數,就是沒人說這個喚醒詞,設備卻被喚醒的概率有多大。
所以這種情況下,組合這兩個評估指標的一個合理做法可能就是最大化準確率(優化),同時要確保24小時內只有一次不是被喚醒詞觸發喚醒(滿足指標)。
這些驗證集必須在訓練集/驗證集/測試集上評估計算,所以還有一件要做的事情就是建立訓練集/開發集/測試集。
在本節中主要介紹如何設置驗證集(development set,或者叫開發集)和測試集。
機器學習的工作流程是,嘗試了很多思路,在訓練集上訓練不同的模型,然后用驗證集來評估不同的思路,從中選擇一個。然后不斷迭代取改善驗證集的性能,直到最后得到一個讓你滿意的成品。 然后再用測試集去評估。
以上面的貓分類器為例,假設你開發了一個貓分類器,然后在下面這些地區運營:

那如何設置驗證集合測試集呢
一種不好的做法是選擇其中4個地區的數據構成驗證集,然后剩下的四個地區數據構成測試集。

為什么說不好呢,因為這個例子中驗證集和測試集來自不同的分布。通常在一個分布中表現好的分類器,在另一個分布中表現不會很好。
所以讓你的驗證集和測試集來自同一分布很重要,記住一個很重要的點,設定驗證集和你的評估方法就像設定你的目標。

因為你一旦確定了驗證集合評估方法,你就可以快速地嘗試各種不同的方法,進行試驗,很快利用驗證集和評估方法來選擇最好的一個。
所以讓測試集和驗證集來自不同的分布,就像你用很長的時間瞄準一個目標,但是過了很久,瞄準好了以后,在測試集測試的時候變成要打另一個目標。
所以上面的例子中,推薦把所有的數據隨機打亂(類似洗牌操作)然后分為驗證集和測試
集。讓驗證集和測試集都擁有八個地區的數據,這樣它們的分布就是一樣的了。
下面是以真實情況改編的例子。
某個機器學習團隊花費了幾個月來優化一個驗證集,其中包括中產地區貸款審批信息。這個機器學習的任務是對某一貸款申請的輸入XXX,預測該申請是否應該通過,以及為什么。
開發集來自中產地區的貸款申請,做了幾個月的努力后,團隊突然決定在低收入地區測試這個模型。因為中產地區的數據和低產地區的數據分布很不一樣,因此這個它們花費了很大精力的分類器在低產地區表現的很糟糕。以至他們不得不重新花時間訓練一個新的模型。
所以,選擇同分布的驗證集和測試集要能反映出將來預計得到的數據和你認為重要的數據。

在機器學習早期,數據量少的時候,按照上面的比例劃分訓練集/驗證集/測試集的大小是合適的。
在現代機器學習中,通常都會操作規模大得多的數據集,比如有100萬個樣本。
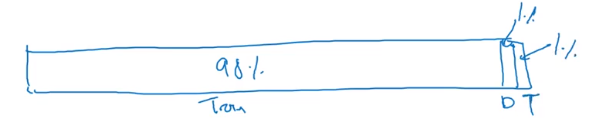
此時訓練集/驗證集/測試集 按照98%/1%/1%的比例分就可以了。
因為你有100萬份數據,1萬份數據對于驗證集和測試集來說已經足夠了。
那測試集大小呢,記住測試集的目的是完成系統開發后來評估投產系統的性能,讓你的訓練集足夠大,能以高置信度評估系統整體性能就可以了。通常有1萬個樣本就有足夠的置信度來給出性能指標了。
也有些應用不需要對系統性能有置信度很高的評估,也許只要訓練集合驗證集(也有人說是一個訓練集合一個測試集)就可以了。
這里建議還是不要省略測試集,有個單獨的測試集會讓你比較安心。
假設你決定構建一個貓分類器,試圖找到很多貓的照片,并展示給愛貓人士看。你決定使用分類誤差作為評估指標。

此時算法A和B的表現如上。看起來A的表現更好,但是當你實際測試這些算法時,發現算法A由于某種原因,會將很多色情圖片也分類為貓!
如果使用A算法,確實識別準確率會高一些,但也會向用戶推送黃圖。相比之下,算法B的錯誤率雖然高一點,但是不會有黃圖。顯然這種情況下算法B更好。
但是如果根據你設定的評估指標,會更傾向于選擇算法A,而實際上你應該選擇算法B。
所以在這種情況下,當你的評估指標無法正確地對算法進行優劣排序時,這時就應該修改評估指標,可能也要修改驗證集或測試集。
假設你的評估指標是這樣的:
1mdev∑i=1mdevI(ypred(i)≠y(i))\frac{1}{m_{dev}} \sum_{i=1}^{m_{dev}} I(y_{pred}^{(i)} \neq y^{(i)}) mdev?1?i=1∑mdev??I(ypred(i)??=y(i))
mdevm_{dev}mdev?是驗證集,I(?)I(\cdot)I(?)是指示函數。
這個指標的問題在于將黃圖和非黃圖一視同仁,改良這個評估指標的一種方法是在這里加入一個權重項w(i)w^{(i)}w(i):
1mdev∑i=1mdevw(i)I(ypred(i)≠y(i))\frac{1}{m_{dev}} \sum_{i=1}^{m_{dev}} w^{(i)} I(y_{pred}^{(i)} \neq y^{(i)}) mdev?1?i=1∑mdev??w(i)I(ypred(i)??=y(i))
當x(i)x^{(i)}x(i)不是黃圖時令w(i)=1w^{(i)}=1w(i)=1,否則為更大的數值101010或100100100。
所以當算法錯誤地將黃圖分類為貓時,會得到更大的誤差值。
如果需要歸一化,還要對w(i)w^{(i)}w(i)進行求和:
1∑iw(i)∑i=1mdevw(i)I(ypred(i)≠y(i))\frac{1}{\sum_i w^{(i)}} \sum_{i=1}^{m_{dev}} w^{(i)} I(y_{pred}^{(i)} \neq y^{(i)}) ∑i?w(i)1?i=1∑mdev??w(i)I(ypred(i)??=y(i))
這里關于如何定義新的指標不是重點,而是當你發現你的指標無法勝任時,就要考慮更換指標。

我們要把機器學習任務看成兩個獨立的步驟,用打靶作比喻,第一步是設定目標,即定義評估指標;
如何精確瞄準,如何命中目標是第二步,即如何是算法在評估指標上表現最好。
下面舉另一個指標和驗證集/測試集出問題的例子。

假設你的兩個貓分類器A和B在以網上精美的照片作為測試集的表現分別為3%和5%的錯誤率。
但也許你在部署算法時發現算法B看起來表現更好,你發現你一直用從網上下載的高質量圖片訓練,但當你部署到線上后,算法應用到用戶上傳的圖片時,這些圖片取景不專業,可能還很模糊

這時你發現算法B在用戶的圖片上表現得更好,這是另一個指標和驗證集/測試集出問題的例子。
所以方針是,如果你在指標+當前的驗證集/測試集上表現的很好,但是實際應用時表現不好,那么就應該修改指標或驗證集/測試集。
此時應該取用戶上傳的圖片作為驗證/測試集。
如何比較機器學習系統和人類的表現這個問題越來越受到重視。
因為現在有些機器學習模型的表現變得很好了,甚至比人類的表現還要好。

隨著時間的推移,機器學習算法的表現越來越好,甚至超過了人類的表現,但是隨后增長的越來越慢,但是無法超過理論上最好的表現,這是理論上最好的表現就是貝葉斯最優錯誤率,一般認為是理論上可能達到的最優錯誤率。
比如對于貓分類器來說,有些圖片非常模糊,不管是人類還是機器都無法判斷該圖片中是否有貓。所以完美的準確度可能不是100%。
這里為什么當機器學習算法超過人類的表現后進展會慢下來,一個原因是人類水平在很多任務中離貝葉斯最優錯誤率已經不遠了,比如人類非常擅長識別圖片。
第二個原因是,只要機器學習算法的表現比人類的表現更差,那么實際上可以使用某些工具來提高性能,而一旦超過了人類的表現,這些工具就沒那么好用了。
人類確實擅長做很多任務,只要機器學習比人類表現差,你就可以:
而一旦你的算法比人類表現還好了,上面三種策略就不好用了。
什么是可避免偏差呢,舉個例子說明

以貓分類器為例,假設人類有幾乎完美的準確度,人類水平的錯誤率是1%。
此時,你的學習算法有8%的訓練錯誤率和10%的驗證錯誤率。
假設你想在訓練集上得到更好的效果,因為你的算法此時和人類表現還有很大的察覺,說明你的算法擬合的不好。
所以從減少偏差和方差這個角度來看,此時我們需要減少偏差。
此時可以訓練更大的神經網絡,或者讓梯度下降迭代更多。
但現在我們看看同樣的訓練錯誤率和驗證錯誤率的情況下,假設人類的表現不是1%,而是7.5%。

也許因為數據集中的圖片非常模糊,哪怕人類也很難準確判斷。
此時你會覺得系統在訓練集上的表現還可以,它只比人類的表現差一點點,此時你可能想減少方差,那么可以試試正則化。
用人類水平的表現代貝葉斯最優錯誤率,在計算機視覺領域中是非常合理的,因為人類十分擅長計算機視覺任務的,根據定義,人類的誤差率會比貝葉斯錯誤率要高一點,因為貝葉斯錯誤率是理論上的上限。
所以這里比較意外的是取決于人類水平錯誤率是多少,具有同樣的訓練錯誤率和驗證錯誤率的情況下,左邊的例子中我們認為要減少偏差,而右邊的例子要減少方差。
左邊的例子中,你認為8%的錯誤率很高,你覺得可以降到1%;而在右邊的例子中,你認為貝葉斯錯誤率是7.5%,你覺得沒有太多的改善空間了,此時你決定去改善驗證集的錯誤率。

這里把貝葉斯錯誤率和訓練錯誤率之間的差值稱為可避免偏差,你希望能一直提高訓練集表現。
而訓練錯誤率和驗證錯誤率之間的差值說明你的算法在方差問題上還有很多改善空間。
可避免偏差這個詞說明有一些別的偏差或錯誤率有個無法超越的最低水平,比如
紅框的這個例子,你不能說你算法的訓練錯誤率是8%,而應該說可避免偏差可能在0.5%左右。此時驗證集和訓練集的差值有2%,因此你要改善驗證集上的表現,降低方差。
而左邊的例子中,可避免偏差為7%,此時需要專注于減少偏差。
只要我們理解了人類水平表現,就可以在不同的場景中專注于不同的策略。
下一節中我們深入了解人類水平表現的真正意義。
我們用人類的表現來估計貝葉斯錯誤率。
下面來看看醫學圖像分類例子,
同樣是人類水平的表現,但是因為術業有專攻,有些人會更擅長某個方面,這里比如是醫學圖像分類。

假設普通人經過簡單的學習能達到3%的錯誤率;而專業的醫生能達到1%的錯誤率;資深專家級醫生能達到0.7%的錯誤率;假設有個團隊有很多專家級醫生,他們通過討論作出判斷,能達到0.5%的錯誤率。
那么應該如何界定人類水平錯誤率呢?
如果你想要估計貝葉斯錯誤率,那么專家級醫生團隊經過討論后可以達到0.5%的錯誤率,根據定義,最優錯誤率必須在0.5%以下。
雖然可能有另外一個團隊能做得更好,但是我們知道最優錯誤率不能高于0.5%。
因此,這里我們可以用0.5%來估計貝葉斯錯誤率,所以將人類水平定義為0.5%。

為了部署系統,也許人類水平錯誤率的定義可以不一樣,只要你的系統能超過專業醫生的表現,那么你的系統就有部署的價值了。
要點是在定義人類水平錯誤率時要清楚你的目標所在,如果要表明你可以超越單個人類,那么就有理由在某些場合部署你的系統。
但是如果你的目標是估計貝葉斯錯誤率,那么應該選上面最小的值。
下面來看一個錯誤率分析的例子。

在醫學圖像識別中,假設你的算法的訓練誤差是5%,驗證誤差是6%,而人類水平的表現取決于你如何定義,可以是1%、0.7%或0.5%。

在這個例子中,不管你人類水平表現如何定義,可避免偏差都在4%到4.5%之間,大于方差錯誤率1%。
所以這種情況下,你應該專注于減少偏差的技術。
現在來look第二例子。

假設你的算法的訓練誤差是1%,驗證誤差是5%,而人類水平的表現取決于你如何定義,可以是1%、0.7%或0.5%。
此時不管你如何定義人類水平表現,你的可避免偏差都在0%到0.5%之間,遠小于方差錯誤率的4%。
所以此時應該專注于減少方差的技術。
上面說的兩個例子中如何定義人類水平表現似乎都關系不大,真正關系大的是下面這個例子:

此時假設你的算法的訓練誤差是0.7%,驗證誤差是0.8%。
此時如果你定義人類水平表現為0.7,那么可避免偏差就是0%,就可以忽略可避免偏差了,此時應該試試能否在驗證集上做得更好; 而如果定義人類水平表現為0.5%,此時可避免偏差就是0.2%,是你測量到的方差問題0.1%的兩倍,此時就要考慮減少偏差。
從這些例子中,希望大家能看到為什么當你的算法接近了人類水平的表現后進展會越來越難。
如果你只知道單個專業醫生能達到1%錯誤率,在第三個例子中就很難知道該去減少訓練集的偏差還是驗證集的方差了。
這種問題只會出現在你的算法已經做得很好的時候,所以機器學習項目的進展在已經做得很好的時候,很難更進一步。

今天這節內容和之前的不同之處在于,之前我們比較的是訓練錯誤率和0%,直接用它們的差值來估計偏差,因為有時候貝葉斯錯誤率是不可能為0%的,因此比較訓練錯誤率和貝葉斯錯誤率更加合理。這樣可以幫助我們更好的做出決策,正確選擇減少偏差的策略或減少方差的策略。
有些特定的任務中,機器學習模型能超過人類的表現。
我們知道機器的表現在接近人類水平的時候進展會變得越來越慢。

還是以醫學圖像識別為例,假設專家組的誤差率是0.5%,單個醫生的誤差率是1%,而你的算法訓練誤差率是0.6%,驗證誤差率是0.8%。
此時可避免偏差是多少呢,

此時應該定義人類水平表現為0.5%的誤差率,因此可避免偏差和方差分別為0.1%和0.2%。
下面看另一組數據,

假設現在你的算法訓練誤差率為0.3%,驗證誤差率為0.4%,那此時可避免偏差是多少呢?
因為你的訓練誤差率為0.3%,可能意味著你過擬合了0.2%,還是因為貝葉斯錯率率實際上是0.1%呢。
基于本例給出的信息,實際上沒有足夠的信息來判斷你的算法應該減少偏差還是方差。
并且在這種情況下,你的算法已經超過了專家團隊的結果,此時通過人類直覺去判斷算法還能在什么方向優化就很難了。
現在有機器學習有很多任務可以超越人類水平了,比如:
這四個例子都是從結構化數據中學習得來的,這里你可能有個數據庫來記錄用戶點擊網頁的歷史、用戶的購物數據庫、從A地到B地需要多久的數據庫、歷史貸款申請及結果數據庫。
這些并不是自然感知問題(計算機視覺、語音識別、自然語音處理等),人類在自然感知任務中往往表現非常好,對機器來說,在自然感知任務的表現要超越人類要更難一些。
并且上面的四個例子都有大量的數據,可能機器能看到的數據量比人類能看到的都多,這樣能容易超越人類的水平。
我們已經學習了正交化、如何設立開發集和測試集、用人類水平來估計貝葉斯誤差以及如何估計可避免偏差和方差。
本節就把它們組合起來,寫成一套指導方針。
想讓一個監督學習算法達到實用,基本上希望能夠完成兩件事情。

根據正交化的思想,有兩組技巧可以修正可避免偏差問題,比如訓練更大的神經網絡、訓練更久;
還有一套獨立的技巧可以用來處理方差問題,比如正則化或收集更多訓練數據。
版权声明:本站所有资料均为网友推荐收集整理而来,仅供学习和研究交流使用。

工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态