上一篇我們使用pyomo對(啤酒混合策略、燃料設計策略、飲食營養策略)進行了建模求解,這一篇我們自己動手,把這三個問題改寫為用遺傳算法geatpy進行求解。其中飲食營養策略涉及比較復雜的數據結構,需要動手實踐下才能好好理解geatpy的使用語法。
特別指出的是,python里的高級數據類型:字典{},可以很方便地輔助我們進行多變量規劃問題的建模,life is short , i use python。
定義模型:
# -*- coding: utf-8 -*-
"""MyProblem.py"""
import numpy as np
import geatpy as ea
class MyProblem(ea.Problem): # 繼承Problem父類def __init__(self):name = 'MyProblem' # 初始化name(函數名稱,可以隨意設置)M = 1 # 初始化M(目標維數)maxormins = [1] # 初始化maxormins(目標最小最大化標記列表,1:最小化該目標;-1:最大化該目標)Dim = 3 # 初始化Dim(決策變量維數),這里就是啤酒混合中的三種原料varTypes = [0] * Dim # 初始化varTypes(決策變量的類型,元素為0表示對應的變量是連續的;1表示是離散的)lb = [0,0,0] # 決策變量下界ub = [100,100,100] # 決策變量上界,由于這個問題并沒有規定上界,因此我們可以自己給一個很大的值,比如100或者10000lbin = [1,1,1] # 決策變量下邊界(0表示不包含該變量的下邊界,1表示包含)ubin = [1,1,1] # 決策變量上邊界(0表示不包含該變量的上邊界,1表示包含)# 調用父類構造方法完成實例化ea.Problem.__init__(self, name, M, maxormins, Dim, varTypes, lb, ub, lbin, ubin)def aimFunc(self, pop): # 目標函數Vars = pop.Phen # 得到決策變量矩陣x1 = Vars[:, [0]]x2 = Vars[:, [1]]x3 = Vars[:, [2]]pop.ObjV = 0.32*x1 + 0.25*x2 + 0.05*x3 # 計算目標函數值,賦值給pop種群對象的ObjV屬性,這里就是啤酒混合的總cost# 采用可行性法則處理約束pop.CV = np.hstack([-x1 - x2 - x3 + 100, #體積約束,即x1+x2+x3>=100-0.005*x1 + 0.003*x2 + 0.04*x3 # 組成成分約束,即0.005*x1 - 0.003*x2 - 0.04*x3 >= 0.04]) python threadpool?模型求解:
if __name__ == '__main__':"""================================實例化問題對象==========================="""problem = MyProblem() # 生成問題對象"""==================================種群設置==============================="""Encoding = 'RI' # 編碼方式NIND = 100 # 種群規模Field = ea.crtfld(Encoding, problem.varTypes, problem.ranges, problem.borders) # 創建區域描述器population = ea.Population(Encoding, Field, NIND) # 實例化種群對象(此時種群還沒被初始化,僅僅是完成種群對象的實例化)"""================================算法參數設置============================="""myAlgorithm = ea.soea_DE_rand_1_L_templet(problem, population) # 實例化一個算法模板對象myAlgorithm.MAXGEN = 500 # 最大進化代數myAlgorithm.mutOper.F = 0.5 # 差分進化中的參數FmyAlgorithm.recOper.XOVR = 0.7 # 重組概率"""===========================調用算法模板進行種群進化======================="""[population, obj_trace, var_trace] = myAlgorithm.run() # 執行算法模板population.save() # 把最后一代種群的信息保存到文件中# 輸出結果best_gen = np.argmin(problem.maxormins * obj_trace[:, 1]) # 記錄最優種群個體是在哪一代best_ObjV = obj_trace[best_gen, 1]print('最優的目標函數值為:%s'%(best_ObjV))print('最優的決策變量值為:')for i in range(var_trace.shape[1]):print(var_trace[best_gen, i])print('有效進化代數:%s'%(obj_trace.shape[0]))print('最優的一代是第 %s 代'%(best_gen + 1))print('評價次數:%s'%(myAlgorithm.evalsNum))print('時間已過 %s 秒'%(myAlgorithm.passTime))模型結果:
種群信息導出完畢。
最優的目標函數值為:27.62500000320636
最優的決策變量值為:
37.500000042895515
62.49999995791917
0.0
有效進化代數:500
最優的一代是第 433 代
評價次數:50000
時間已過 0.5115456581115723 秒
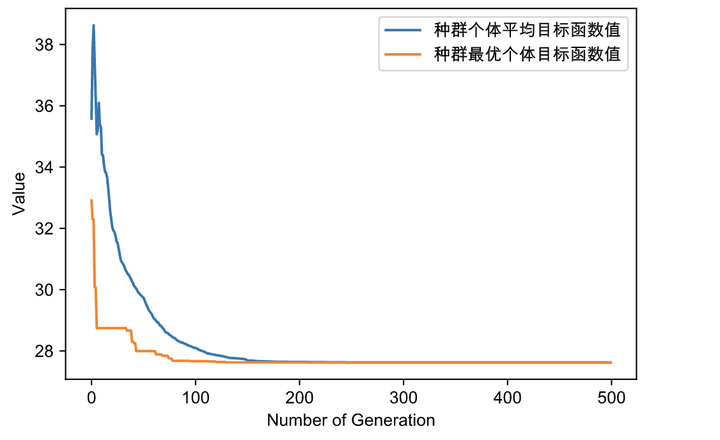
我們跟上一篇的pyomo多變量問題實踐使用python字典,這樣可以更方便地書寫geatpy代碼,更多變量的時候也更加易擴展,代碼如下:
定義模型:
data = {'A': {'abv': 0.045, 'cost': 0.32},'B': {'abv': 0.037, 'cost': 0.25},'W': {'abv': 0.000, 'cost': 0.05},
}vol = 100
abv = 0.040C = data.keys()# -*- coding: utf-8 -*-
"""MyProblem.py"""
import numpy as np
import geatpy as ea
class MyProblem(ea.Problem): # 繼承Problem父類def __init__(self):name = 'MyProblem' # 初始化name(函數名稱,可以隨意設置)M = 1 # 初始化M(目標維數)maxormins = [1] # 初始化maxormins(目標最小最大化標記列表,1:最小化該目標;-1:最大化該目標)Dim = 3 # 初始化Dim(決策變量維數)varTypes = [0] * Dim # 初始化varTypes(決策變量的類型,元素為0表示對應的變量是連續的;1表示是離散的)lb = [0,0,0] # 決策變量下界ub = [100,100,100] # 決策變量上界,由于這個問題并沒有規定上界,因此我們可以自己給一個很大的值,比如100或者10000lbin = [1,1,1] # 決策變量下邊界(0表示不包含該變量的下邊界,1表示包含),或者寫作【1】*3ubin = [1,1,1] # 決策變量上邊界(0表示不包含該變量的上邊界,1表示包含)# 調用父類構造方法完成實例化ea.Problem.__init__(self, name, M, maxormins, Dim, varTypes, lb, ub, lbin, ubin)def aimFunc(self, pop): # 目標函數Vars = pop.Phen # 得到決策變量矩陣x = {} # 用一個字典存儲決策變量for i,c in zip(range(len(C)),C):x[c] = Vars[:, [i]] # 怎么用字典得到決策變量矩陣pop.ObjV = sum(x[c]*data[c]['cost'] for c in C) # 計算目標函數值,賦值給pop種群對象的ObjV屬性# 采用可行性法則處理約束pop.CV = np.hstack([- sum(x[c] for c in C) + 100 , #體積約束,即x1+x2+x3>=100- sum(x[c]*(data[c]['abv'] - abv) for c in C) #組成成分約束,即0.005*x1 - 0.003*x2 - 0.04*x3 >= 0.04]) python性能?最終得到的結果和普通寫法是一樣的:

data = {'ethanol' : {'MW': 46.07, 'SG': 0.791, 'A': 8.04494, 'B': 1554.3, 'C': 222.65},'methanol' : {'MW': 32.04, 'SG': 0.791, 'A': 7.89750, 'B': 1474.08, 'C': 229.13},'isopropyl alcohol': {'MW': 60.10, 'SG': 0.785, 'A': 8.11778, 'B': 1580.92, 'C': 219.61},'acetone' : {'MW': 58.08, 'SG': 0.787, 'A': 7.02447, 'B': 1161.0, 'C': 224.0},'xylene' : {'MW': 106.16, 'SG': 0.870, 'A': 6.99052, 'B': 1453.43, 'C': 215.31},'toluene' : {'MW': 92.14, 'SG': 0.865, 'A': 6.95464, 'B': 1344.8, 'C': 219.48},
}
S = data.keys()def Pvap(T, s):return 10**(data[s]['A'] - data[s]['B']/(T + data[s]['C'])) # 單種組成成分s的Antoine蒸汽壓def Pvap_denatured(T):return 0.4*Pvap(T, 'ethanol') + 0.6*Pvap(T, 'methanol') # 假設變性酒精是乙醇和甲醇的40/60(摩爾分數)的混合物,那么它的蒸汽壓是多少def Pmix(T,x):return sum(x[s]*Pvap(T,s) for s in S) # 計算多種組成成分的蒸汽壓# -*- coding: utf-8 -*-
"""MyProblem.py"""
import numpy as np
import geatpy as ea
class MyProblem(ea.Problem): # 繼承Problem父類def __init__(self):name = 'MyProblem' # 初始化name(函數名稱,可以隨意設置)M = 1 # 初始化M(目標維數)maxormins = [-1] # 初始化maxormins,本問題是最大化蒸汽壓(目標最小最大化標記列表,1:最小化該目標;-1:最大化該目標)Dim = 6 # 初始化Dim(決策變量維數)varTypes = [0] * Dim # 初始化varTypes(決策變量的類型,元素為0表示對應的變量是連續的;1表示是離散的)lb = [0]* Dim # 決策變量下界ub = [10000] * Dim # 決策變量上界,由于這個問題并沒有規定上界,因此我們可以自己給一個很大的值,比如100或者10000lbin = [1] * Dim # 決策變量下邊界(0表示不包含該變量的下邊界,1表示包含),或者寫作【1】*3ubin = [1] * Dim # 決策變量上邊界(0表示不包含該變量的上邊界,1表示包含)# 調用父類構造方法完成實例化ea.Problem.__init__(self, name, M, maxormins, Dim, varTypes, lb, ub, lbin, ubin)def aimFunc(self, pop): # 目標函數Vars = pop.Phen # 得到決策變量矩陣x = {} # 用一個字典存儲決策變量for i,s in zip(range(len(S)),S):x[s] = Vars[:, [i]] # 怎么用字典得到決策變量矩陣pop.ObjV = Pmix(-10,x) # 計算目標函數值,最大化10攝氏度時的蒸汽壓# 采用可行性法則處理約束pop.CV = np.hstack([-sum(x[s] for s in S)+1, # 摩爾分數之和等于1Pmix(30,x) - Pvap_denatured(30) , #30°C時,混合燃料蒸汽壓小于或等于變性酒精蒸汽壓Pmix(40,x) - Pvap_denatured(40) #40°C時,混合燃料蒸汽壓小于或等于變性酒精蒸汽壓]) if __name__ == '__main__':"""================================實例化問題對象==========================="""problem = MyProblem() # 生成問題對象"""==================================種群設置==============================="""Encoding = 'RI' # 編碼方式NIND = 100 # 種群規模Field = ea.crtfld(Encoding, problem.varTypes, problem.ranges, problem.borders) # 創建區域描述器population = ea.Population(Encoding, Field, NIND) # 實例化種群對象(此時種群還沒被初始化,僅僅是完成種群對象的實例化)"""================================算法參數設置============================="""myAlgorithm = ea.soea_DE_rand_1_L_templet(problem, population) # 實例化一個算法模板對象myAlgorithm.MAXGEN = 500 # 最大進化代數myAlgorithm.mutOper.F = 0.5 # 差分進化中的參數FmyAlgorithm.recOper.XOVR = 0.7 # 重組概率"""===========================調用算法模板進行種群進化======================="""[population, obj_trace, var_trace] = myAlgorithm.run() # 執行算法模板population.save() # 把最后一代種群的信息保存到文件中# 輸出結果best_gen = np.argmin(problem.maxormins * obj_trace[:, 1]) # 記錄最優種群個體是在哪一代best_ObjV = obj_trace[best_gen, 1]print('最優的目標函數值為:%s'%(best_ObjV))print('最優的決策變量值為:')for i in range(var_trace.shape[1]):print(var_trace[best_gen, i])print('有效進化代數:%s'%(obj_trace.shape[0]))print('最優的一代是第 %s 代'%(best_gen + 1))print('評價次數:%s'%(myAlgorithm.evalsNum))print('時間已過 %s 秒'%(myAlgorithm.passTime))結果:
種群信息導出完畢。
最優的目標函數值為:17.481748736011284
最優的決策變量值為:
0.0
0.0
0.0
0.42816068078343505
0.5718119476118912
3.111782763846932e-05
有效進化代數:500
最優的一代是第 494 代
評價次數:52900
時間已過 0.56656813621521 秒
需要注意的是:
np.abs(sum(x[s] for s in S)-1), #當pop.CV中硬性規定摩爾分數之和等于1時,算法結果很差,這是進化算法的一個固有問題python性能優化,

這個問題寫起來是比較麻煩的,因為涉及的方面比較多所以寫起來也比較麻煩,下圖中各個字段具體含義可以回顧上節內容:

這個函數是我們進行約束條件pop.CV的時候用到的,因為這次我們的約束條件寫起來比較麻煩(約束條件涉及到i,j):

python多進程,因此我們需要先理解這個函數,它的功能是將兩個數組橫向合并:
a1=np.array([[1,2],[3,4],[5,6]])
a2=np.array([[7,8],[9,10],[11,12]])
a3= np.hstack([a1,a2])
print(a3)
F = {
"Cheeseburger" :{'c':1.84,'v':4.0},
"Ham Sandwich" : {'c':2.19,'v': 7.5},
"Hamburger":{'c':1.84,'v':3.5},
"Fish Sandwich" : {'c':1.44,'v':5.0},
"Chicken Sandwich":{'c':2.29,'v':7.3},
"Fries" :{'c':0.77,'v': 2.6 },
"Sausage Biscuit":{'c':1.29 , 'v':4.1},
"Lowfat Milk" : {'c':0.60,'v': 8.0},
"Orange Juice":{'c':0.72,'v':12.0}
}Vmax=75N = {
'Cal' :{'Nmin':2000, 'Nmax':10000},
'Carbo' :{'Nmin':350, 'Nmax':375},
'Protein' :{'Nmin':55, 'Nmax':10000},
'VitA' :{'Nmin':100, 'Nmax':10000},
'VitC' :{'Nmin':100, 'Nmax':10000},
'Calc' :{'Nmin':100, 'Nmax':10000},
'Iron' :{'Nmin':100, 'Nmax':10000},
}a = {
"Cheeseburger" : {'Cal':510,'Carbo':34,'Protein':28,'VitA':15,'VitC':6,'Calc':30,'Iron':20},
"Ham Sandwich" : {'Cal':370,'Carbo':35,'Protein':24,'VitA':15,'VitC':10,'Calc':20,'Iron':20} ,
"Hamburger" : {'Cal':500,'Carbo':42,'Protein':25,'VitA':6,'VitC':2,'Calc':25,'Iron':20} ,
"Fish Sandwich" : {'Cal':370,'Carbo':38,'Protein':14,'VitA':2,'VitC':0,'Calc':15,'Iron':10} ,
"Chicken Sandwich" : {'Cal':400,'Carbo':42,'Protein':31,'VitA':8,'VitC':15,'Calc':15,'Iron':8} ,
"Fries" : {'Cal':220,'Carbo':26,'Protein':3,'VitA':0,'VitC':15,'Calc':0,'Iron':2} ,
"Sausage Biscuit" : {'Cal':345,'Carbo':27,'Protein':15,'VitA':4,'VitC':0,'Calc':20,'Iron':15} ,
"Lowfat Milk" : {'Cal':110,'Carbo':12,'Protein':9,'VitA':10,'VitC':4,'Calc':30,'Iron':0} ,
"Orange Juice" : {'Cal':80,'Carbo':20,'Protein':1,'VitA':2,'VitC':120,'Calc':2,'Iron':2} ,
}# 食物名和營養名的列表
foods = F.keys()
nutrients = N.keys()
print(foods)
print(nutrients)'''
dict_keys(['Cheeseburger', 'Ham Sandwich', 'Hamburger', 'Fish Sandwich', 'Chicken Sandwich', 'Fries', 'Sausage Biscuit', 'Lowfat Milk', 'Orange Juice'])
dict_keys(['Cal', 'Carbo', 'Protein', 'VitA', 'VitC', 'Calc', 'Iron'])
'''# 通過F獲得cost食品價格
cost = {}
for i in foods:cost[i] = F[i]['c']
print(cost)# 通過F獲得volume食品體積
volume = {}
for i in foods:volume[i] = F[i]['v']
print(volume)'''
{'Cheeseburger': 1.84, 'Ham Sandwich': 2.19, 'Hamburger': 1.84, 'Fish Sandwich': 1.44, 'Chicken Sandwich': 2.29, 'Fries': 0.77, 'Sausage Biscuit': 1.29, 'Lowfat Milk': 0.6, 'Orange Juice': 0.72}
{'Cheeseburger': 4.0, 'Ham Sandwich': 7.5, 'Hamburger': 3.5, 'Fish Sandwich': 5.0, 'Chicken Sandwich': 7.3, 'Fries': 2.6, 'Sausage Biscuit': 4.1, 'Lowfat Milk': 8.0, 'Orange Juice': 12.0}
'''# 通過N獲得Nmin最低營養要求
Nmin = {}
for i in nutrients:Nmin[i] = N[i]['Nmin']
print(Nmin)# 通過N獲得Nax最低營養要求
Nmax = {}
for i in nutrients:Nmax[i] = N[i]['Nmax']
print(Nmax)
'''
{'Cal': 2000, 'Carbo': 350, 'Protein': 55, 'VitA': 100, 'VitC': 100, 'Calc': 100, 'Iron': 100}
{'Cal': 10000, 'Carbo': 375, 'Protein': 10000, 'VitA': 10000, 'VitC': 10000, 'Calc': 10000, 'Iron': 10000}
'''# 目標函數:Minimize the cost of food that is consumed
def cost_rule(cost,x):return sum(cost[i]*x[i] for i in foods)# 約束條件
# Limit nutrient consumption for each nutrient
def min_nutrient_rule(j,x):value = sum(a[i][j]*x[i] for i in foods)return Nmin[j] - valuedef max_nutrient_rule(j,x):value = sum(a[i][j]*x[i] for i in foods)return value - Nmax[j]# Limit the volume of food consumed
def volume_rule(volume,x):return sum(volume[i]*x[i] for i in foods) - Vmax# -*- coding: utf-8 -*-
"""MyProblem.py"""
import numpy as np
import geatpy as ea
class MyProblem(ea.Problem): # 繼承Problem父類def __init__(self):name = 'MyProblem' # 初始化name(函數名稱,可以隨意設置)M = 1 # 初始化M(目標維數)maxormins = [1] # 初始化maxormins,本問題是最小化cost(目標最小最大化標記列表,1:最小化該目標;-1:最大化該目標)Dim = 9 # 初始化Dim(決策變量維數),9種食物varTypes = [0] * Dim # 初始化varTypes(決策變量的類型,元素為0表示對應的變量是連續的;1表示是離散的)lb = [0]* Dim # 決策變量下界ub = [10000] * Dim # 決策變量上界,由于這個問題并沒有規定上界,因此我們可以自己給一個很大的值,比如100或者10000lbin = [1] * Dim # 決策變量下邊界(0表示不包含該變量的下邊界,1表示包含)ubin = [1] * Dim # 決策變量上邊界(0表示不包含該變量的上邊界,1表示包含)# 調用父類構造方法完成實例化ea.Problem.__init__(self, name, M, maxormins, Dim, varTypes, lb, ub, lbin, ubin)def aimFunc(self, pop): # 目標函數Vars = pop.Phen # 得到決策變量矩陣x = {} # 用一個字典存儲決策變量for i,f in zip(range(len(foods)),foods):x[f] = Vars[:, [i]] # 怎么用字典得到決策變量矩陣pop.ObjV = sum(cost[i]*x[i] for i in foods) # 計算目標函數值,最大化10攝氏度時的蒸汽壓# 采用可行性法則處理約束pop.CV = np.hstack([volume_rule(volume,x) # 最大體積限制])for j in nutrients:pop.CV = np.hstack( [pop.CV,min_nutrient_rule(j,x) ] ) # 最小營養限制pop.CV = np.hstack( [pop.CV,max_nutrient_rule(j,x) ] ) # 最大營養限制if __name__ == '__main__':"""================================實例化問題對象==========================="""problem = MyProblem() # 生成問題對象"""==================================種群設置==============================="""Encoding = 'RI' # 編碼方式NIND = 100 # 種群規模Field = ea.crtfld(Encoding, problem.varTypes, problem.ranges, problem.borders) # 創建區域描述器population = ea.Population(Encoding, Field, NIND) # 實例化種群對象(此時種群還沒被初始化,僅僅是完成種群對象的實例化)"""================================算法參數設置============================="""myAlgorithm = ea.soea_DE_rand_1_L_templet(problem, population) # 實例化一個算法模板對象myAlgorithm.MAXGEN = 500 # 最大進化代數myAlgorithm.mutOper.F = 0.5 # 差分進化中的參數FmyAlgorithm.recOper.XOVR = 0.7 # 重組概率"""===========================調用算法模板進行種群進化======================="""[population, obj_trace, var_trace] = myAlgorithm.run() # 執行算法模板population.save() # 把最后一代種群的信息保存到文件中# 輸出結果best_gen = np.argmin(problem.maxormins * obj_trace[:, 1]) # 記錄最優種群個體是在哪一代best_ObjV = obj_trace[best_gen, 1]print('最優的目標函數值為:%s'%(best_ObjV))print('最優的決策變量值為:')for i in range(var_trace.shape[1]):print(var_trace[best_gen, i])print('有效進化代數:%s'%(obj_trace.shape[0]))print('最優的一代是第 %s 代'%(best_gen + 1))print('評價次數:%s'%(myAlgorithm.evalsNum))print('時間已過 %s 秒'%(myAlgorithm.passTime))可以看到每天的最低消費是15美元,跟pyomo實踐里得到的結果一樣

種群信息導出完畢。
最優的目標函數值為:15.006541106717268
最優的決策變量值為:
4.170816605310961
0.0
0.1361945982215054
0.16754066745178284
0.0
5.947026835638826
0.06781133655392207
3.622824405817513
0.0
有效進化代數:500
最優的一代是第 438 代
評價次數:56800
時間已過 0.8515150547027588 秒【1】python運籌優化(五):多變量規劃問題pyomo實踐:https://zhuanlan.zhihu.com/p/134950216
版权声明:本站所有资料均为网友推荐收集整理而来,仅供学习和研究交流使用。

工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态