Pandas的级联,这一节从如何在DataFrame中处理重复数据开始。DataFrame中查找不重复的数据Pandas之前,我个人对这类数据的处理是利用集合set的元素唯一性来实现,这样需要写不少的代码,但在Pandas中,只是一个函数即可搞定,下面我们来举例说明: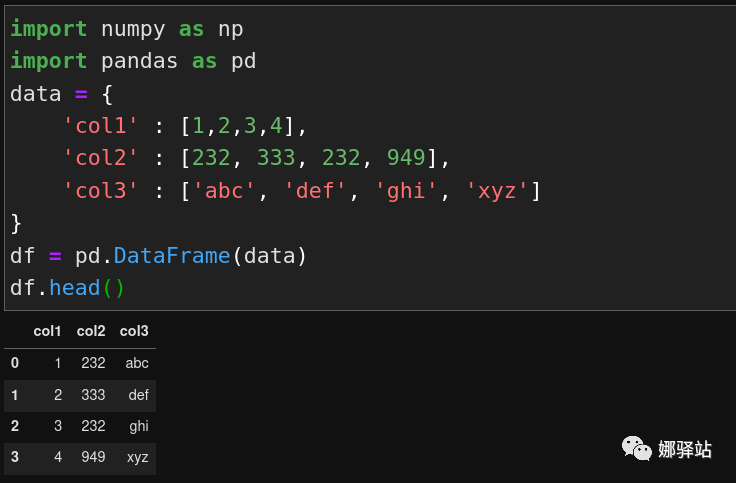
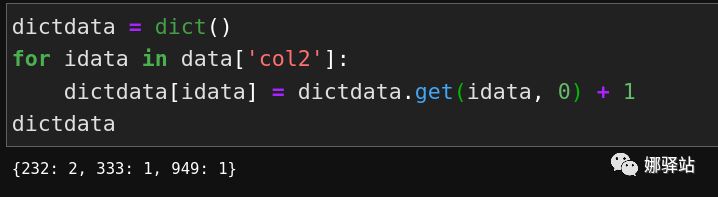
col2中的不重复数据,如果用set集合实现,我是这样子做的: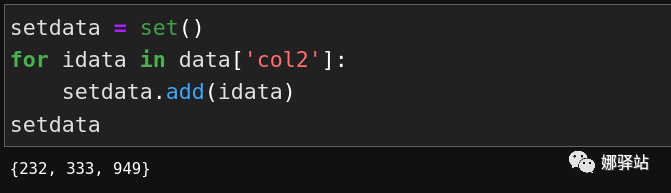
Pandas来完成上述功能,只用一句即可:

Pandas来处理,还是一条语句即可: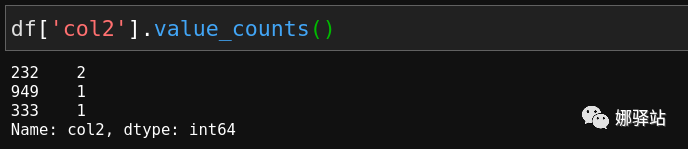
Pandas来对数据处理,可以用很简洁的方式代替原本需要组合语句才能实现的功能。下面我们再来看看对数据的批处理。apply方法apply、map等函数,在本公众号前面的文章中有介绍过,在Pandas中,也实现了apply函数,下面举例说明: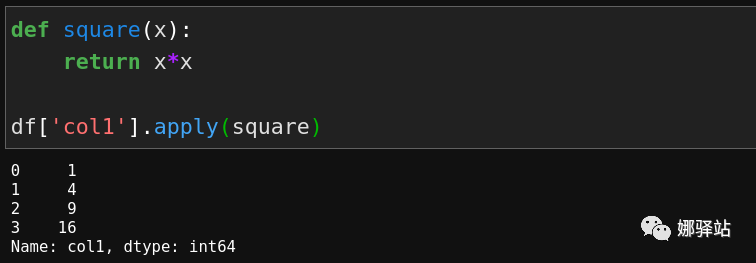
Python中内置的函数,比如对第3列数据求每个字符串的长度: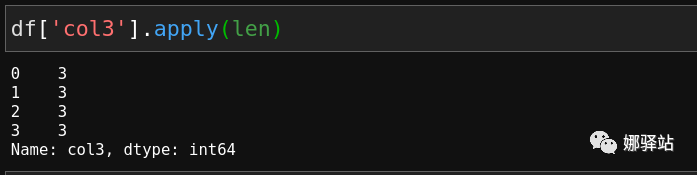
apply中直接嵌入lambda函数: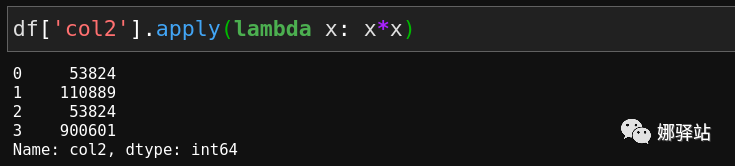
DataFrame属性有时候我们要得到DataFrame的列名和行名,这时就要用到获取其属性的方法,下面举例说明: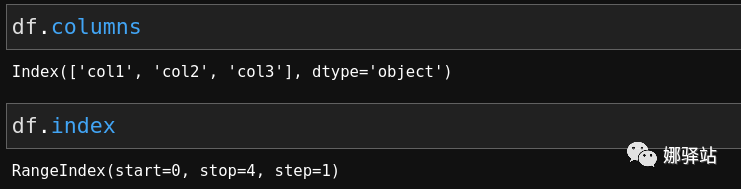
Index类型的数据,由于在定义DataFrame时,我们没有为其指定index选项,因此,它的Index采用的是Pandas默认的RangeIndex数字序列。Excel中可以以指定列对数据集排列,Pandas中也有类似的功能:
ascending=False即可,它的默认值是True,即默认从小到大,下面显示其逆序排列: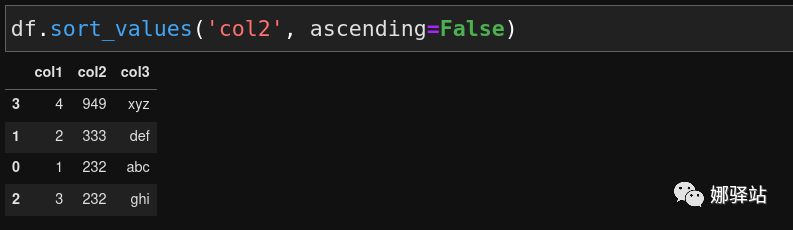
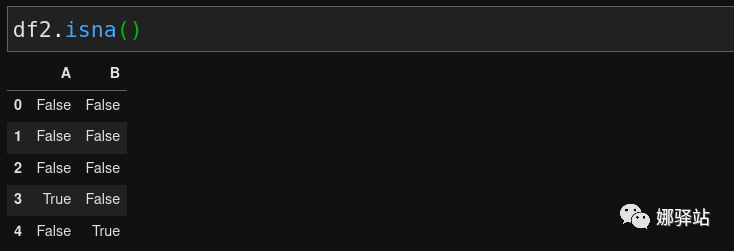
sort_values会生成新的数据框架,不会修改原数据,如果要修改原数据,则需要inplace=True,这个在之前的学习笔记中也提到有类似的函数也采用的是这种处理方式。恰好够用的Pandas子集的时候,我们介绍过在Pandas中,查找空值有两个函数,一是isna,一是isnull,由于在DataFrame中是用numpy中的nan来表示空值,因此我们推荐只用isna来查询空值,比如构建一个含空值的数据集如下: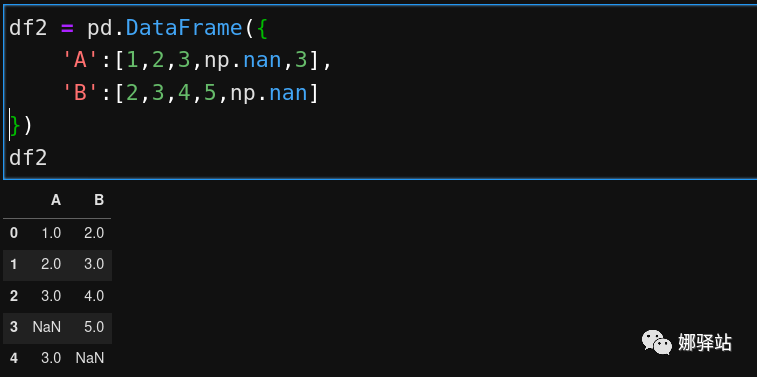
pivot table)熟悉Excel的同学一定对其中的数据透视表印象深刻,它可将原数据概述化(summarizes)为另一个表,在新的表中,可以很容易对进行分类、切片、过滤、排序、计数等等,下面我们来看一下Pandas中的透视表是如何创建的。先构建一个新的数据框架: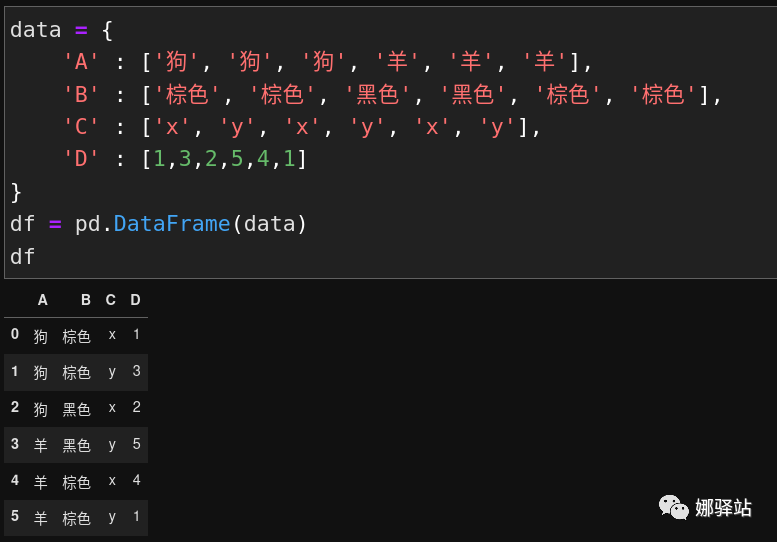
.pivot_table,下面我们将根据上面的DataFrame来创建一个透视表: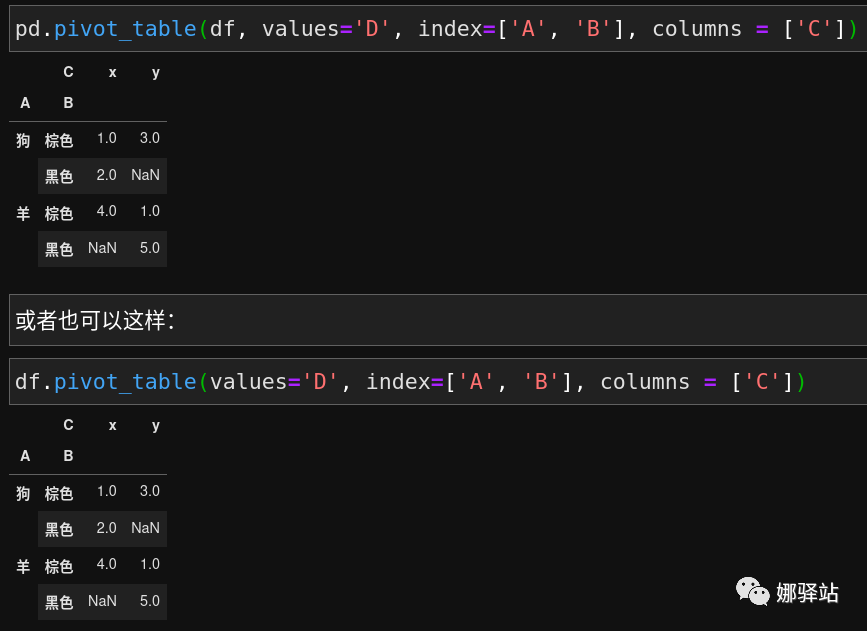
pivot_table的参数values是要透视的数据点,index是指定的关键列,columns代表应该被分析的列,比如上面生成的透视表第一行,即是棕色的狗对应的x按D列值来算是1,而对应的y按D列值来算是3。因为黑色的狗没有对应的y,因此第二行中y列下为NaN。其余类似。Pandas中的数据去重进行了分析,又探索了apply函数的应用,接着对于数据的排序进行了说明,在文章的最后,我们介绍了数据透视表的生成方法。版权声明:本站所有资料均为网友推荐收集整理而来,仅供学习和研究交流使用。

工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态


![[CentOS7] - CentOS7设置开机启动](https://www.oschina.net/img/hot3.png)