簡單來說互聯網是由一個個站點和網絡設備組成的大網,我們通過瀏覽器訪問站點,站點把HTML、JS、CSS代碼返回給瀏覽器,這些代碼經過瀏覽器解析、渲染,將豐富多彩的網頁呈現我們眼前。如果我們把互聯網比作一張大的蜘蛛網,數據便是存放于蜘蛛網的各個節點,而爬蟲就是一只小蜘蛛,沿著網絡抓取自己的獵物(數據)爬蟲指的是:向網站發起請求,獲取資源后分析并提取有用數據的程序;從技術層面來說就是 通過程序模擬瀏覽器請求站點的行為,把站點返回的HTML代碼/JSON數據/二進制數據(圖片、視頻) 爬到本地,進而提取自己需要的數據,存放起來使用。
本文主要內容,以最短的時間寫一個最簡單的爬蟲,可以抓取論壇的帖子標題和帖子內容。本文受眾,沒寫過爬蟲的萌新。
入門
python?0.準備工作
需要準備的東西: Python、scrapy、一個IDE或者隨便什么文本編輯工具。
1.技術部已經研究決定了,你來寫爬蟲。
隨便建一個工作目錄,然后用命令行建立一個工程,工程名為miao,可以替換為你喜歡的名字。
python編程入門。scrapy startproject miao
隨后你會得到如下的一個由scrapy創建的目錄結構
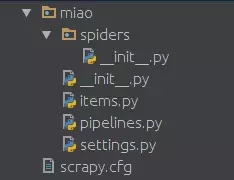
在spiders文件夾中創建一個python文件,比如miao.py,來作為爬蟲的腳本。
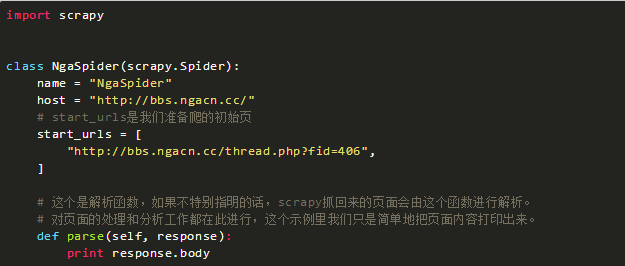
計算機語言python、內容如下:
2.跑一個試試?
如果用命令行的話就這樣:
python4。cd miaoscrapy crawl NgaSpider
你可以看到爬蟲君已經把你壇星際區第一頁打印出來了,當然由于沒有任何處理,所以混雜著html標簽和js腳本都一并打印出來了。
解析
接下來我們要把剛剛抓下來的頁面進行分析,從這坨html和js堆里把這一頁的帖子標題提煉出來。
python語言編程。其實解析頁面是個體力活,方法多的是,這里只介紹xpath。
0.為什么不試試神奇的xpath呢
看一下剛才抓下來的那坨東西,或者用chrome瀏覽器手動打開那個頁面然后按F12可以看到頁面結構。
每個標題其實都是由這么一個html標簽包裹著的。舉個例子:
python有什么用?[合作模式] 合作模式修改設想
可以看到href就是這個帖子的地址(當然前面要拼上論壇地址),而這個標簽包裹的內容就是帖子的標題了。
于是我們用xpath的絕對定位方法,把class='topic'的部分摘出來。
1.看看xpath的效果
python3?在最上面加上引用:
from scrapy import Selector
把parse函數改成:
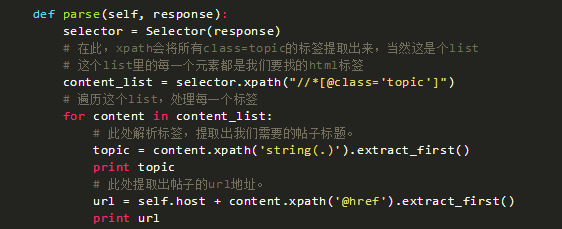
再次運行就可以看到輸出你壇星際區第一頁所有帖子的標題和url了。
遞歸
接下來我們要抓取每一個帖子的內容。
這里需要用到python的yield。
yield Request(url=url, callback=self.parse_topic)
此處會告訴scrapy去抓取這個url,然后把抓回來的頁面用指定的parse_topic函數進行解析。
至此我們需要定義一個新的函數來分析一個帖子里的內容。
完整的代碼如下:
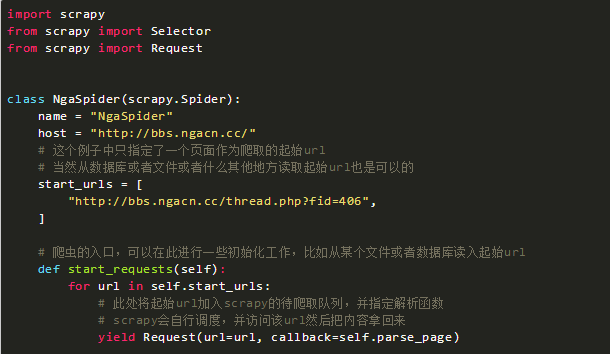
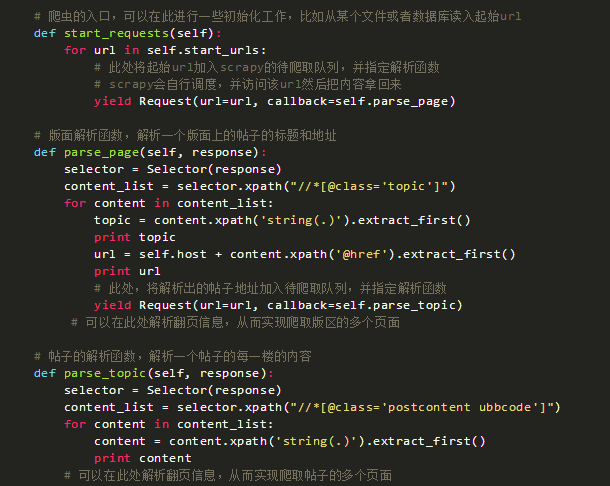
到此為止,這個爬蟲可以爬取你壇第一頁所有的帖子的標題,并爬取每個帖子里第一頁的每一層樓的內容。
爬取多個頁面的原理相同,注意解析翻頁的url地址、設定終止條件、指定好對應的頁面解析函數即可。
Pipelines——管道
此處是對已抓取、解析后的內容的處理,可以通過管道寫入本地文件、數據庫。
0.定義一個Item
在miao文件夾中創建一個items.py文件。
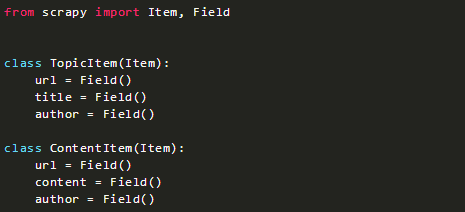
此處我們定義了兩個簡單的class來描述我們爬取的結果。
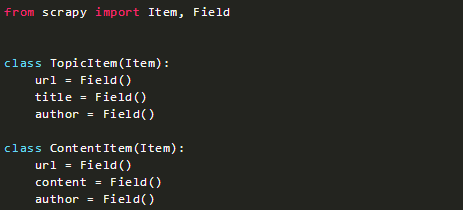
1. 寫一個處理方法
在miao文件夾下面找到那個pipelines.py文件,scrapy之前應該已經自動生成好了。
我們可以在此建一個處理方法。
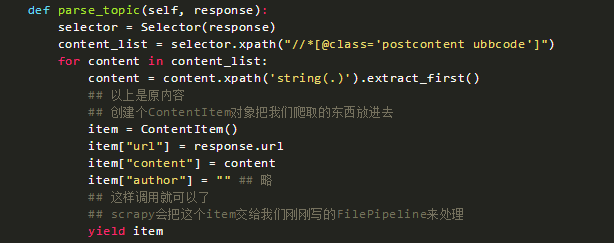
2.在爬蟲中調用這個處理方法。
要調用這個方法我們只需在爬蟲中調用即可,例如原先的內容處理函數可改為:
3.在配置文件里指定這個pipeline
找到settings.py文件,在里面加入

這樣在爬蟲里調用

的時候都會由經這個FilePipeline來處理。后面的數字400表示的是優先級。
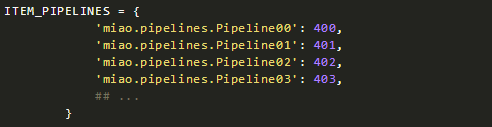
可以在此配置多個Pipeline,scrapy會根據優先級,把item依次交給各個item來處理,每個處理完的結果會傳遞給下一個pipeline來處理。
可以這樣配置多個pipeline:
Middleware——中間件
通過Middleware我們可以對請求信息作出一些修改,比如常用的設置UA、代理、登錄信息等等都可以通過Middleware來配置。
0.Middleware的配置
與pipeline的配置類似,在setting.py中加入Middleware的名字,例如

1.破網站查UA, 我要換UA
某些網站不帶UA是不讓訪問的。
在miao文件夾下面建立一個middleware.py
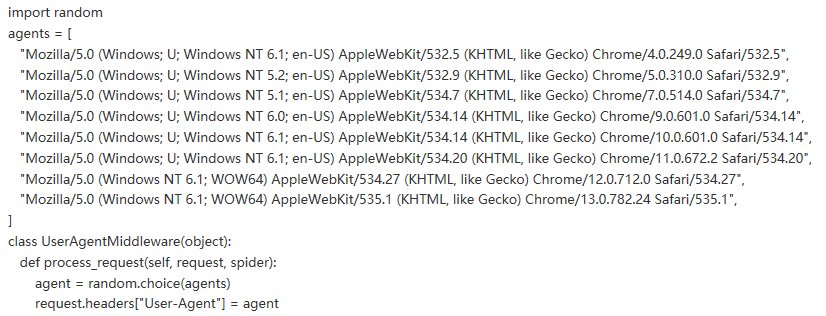
這里就是一個簡單的隨機更換UA的中間件,agents的內容可以自行擴充。
2.破網站封IP,我要用代理
比如本地127.0.0.1開啟了一個8123端口的代理,同樣可以通過中間件配置讓爬蟲通過這個代理來對目標網站進行爬取。
同樣在middleware.py中加入:
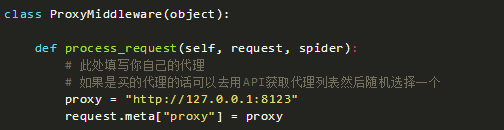
很多網站會對訪問次數進行限制,如果訪問頻率過高的話會臨時禁封IP。
如果需要的話可以從網上購買IP,一般服務商會提供一個API來獲取當前可用的IP池,選一個填到這里就好。
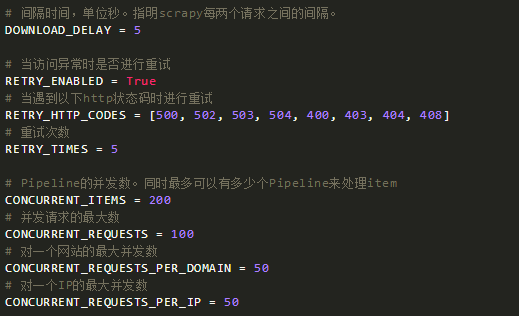
一些常用配置
在settings.py中的一些常用配置
我就是要用Pycharm
如果非要用Pycharm作為開發調試工具的話可以在運行配置里進行如下配置:
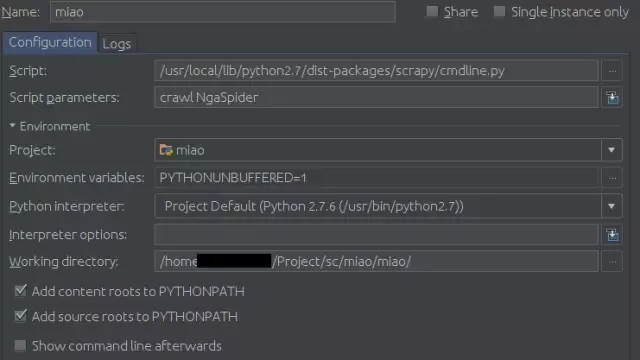
Configuration頁面:
Script填你的scrapy的cmdline.py路徑,比如我的是
/usr/local/lib/python2.7/dist-packages/scrapy/cmdline.py
然后在Scrpit parameters中填爬蟲的名字,本例中即為:
crawl NgaSpider
最后是Working diretory,找到你的settings.py文件,填這個文件所在的目錄。
示例:
按小綠箭頭就可以愉快地調試了。
參考
這里提供了對scrapy非常詳細的介紹。
http://scrapy-chs.readthedocs.io/zh_CN/0.24/
以下是幾個比較重要的地方:
scrapy的架構:
http://scrapy-chs.readthedocs.io/zh_CN/0.24/topics/architecture.html
xpath語法:
http://www.w3school.com.cn/xpath/xpath_syntax.asp
Pipeline管道配置:
http://scrapy-chs.readthedocs.io/zh_CN/0.24/topics/item-pipeline.html
Middleware中間件的配置:
http://scrapy-chs.readthedocs.io/zh_CN/0.24/topics/downloader-middleware.html
settings.py的配置:
http://scrapy-chs.readthedocs.io/zh_CN/0.24/topics/settings.html
版权声明:本站所有资料均为网友推荐收集整理而来,仅供学习和研究交流使用。

工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态








![Bzoj4822 [Cqoi2017]老C的任务](/upload/rand_pic/2-001.jpg)

