關于模擬瀏覽器登錄的header,可以在相應網站按F12調取出編輯器,點擊netwook,如下:
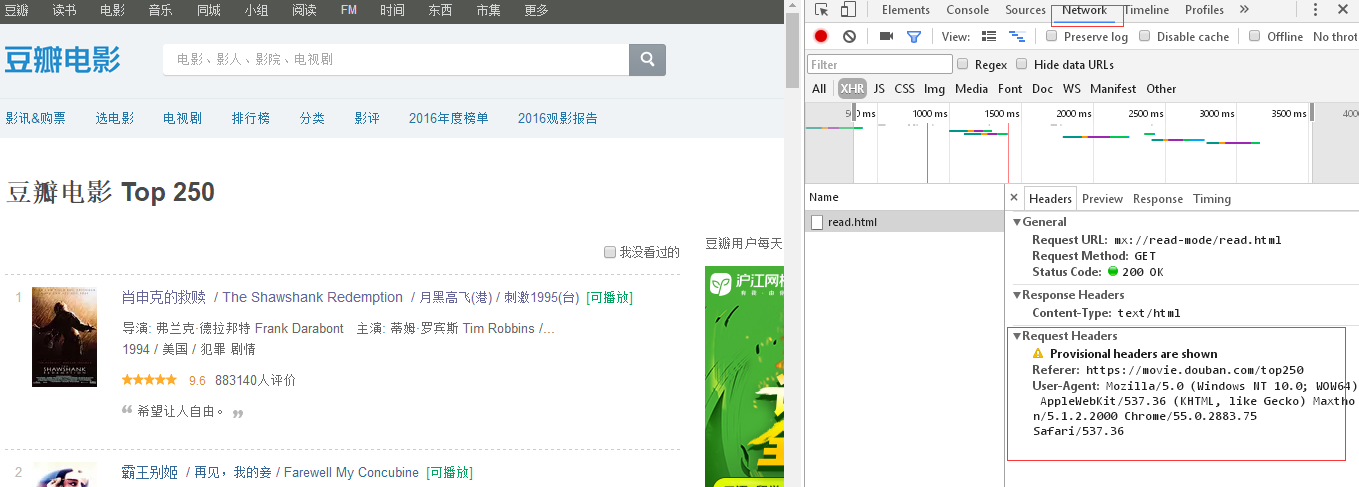
以便于不會被網站反爬蟲拒絕。
?
1 import requests 2 from bs4 import BeautifulSoup 5 def get_movies(): 6 headers = { 7 'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.82 Safari/537.36', 8 'Host': 'movie.douban.com' 9 } 10 movie_list = [] #定義序列 11 for i in range(0, 10): 12 link = 'https://movie.douban.com/top250?start=' + str(i * 25) #通過循環,下載第二頁,第三頁 13 r = requests.get(link, headers=headers, timeout=10) #timeout=10,響應時長 14 print(str(i + 1), "頁響應狀態碼:", r.status_code) #顯示狀態碼,返回200,請求成功 15 16 soup = BeautifulSoup(r.text, "lxml") 17 div_list = soup.find_all('div', class_='hd') #如下圖顯示,電影名字在div標簽之后 18 for each in div_list: 19 movie = each.a.span.text.strip() #span后的文本 20 movie_list.append(movie) #append(movie),在movie_list中添加movie序列
21 return movie_list
24 movies = get_movies()
25 print(movies)
python爬蟲有什么用?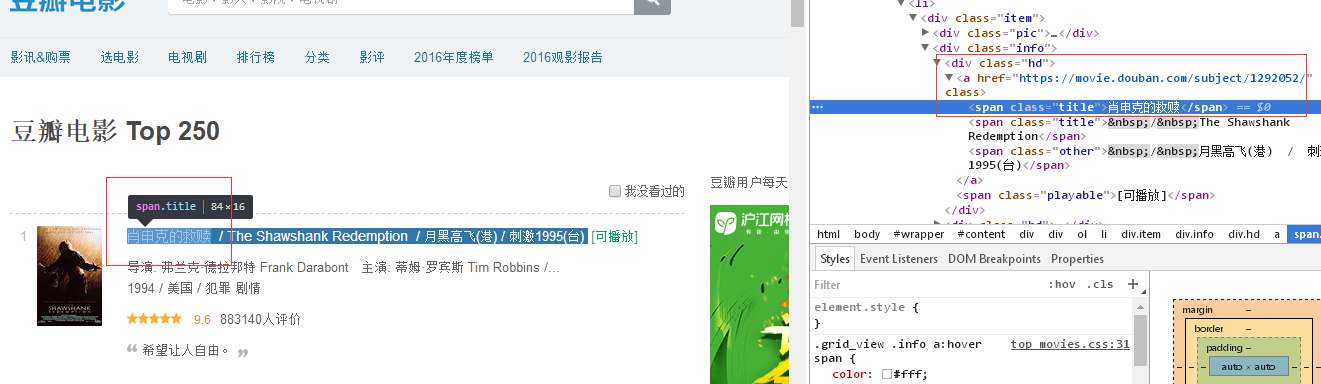
?


![Bzoj4822 [Cqoi2017]老C的任务](/upload/rand_pic/2-001.jpg)





![[高性能javascript笔记]1-加载和执行](https://www.oschina.net/img/hot3.png)


