機器學習是從數據中自動分析獲得規律(模型),并利用規律對未知數據進行預測
1、解放生產力–智能客服
2.解決專業問題–ET醫療
3.提供社會便利–城市大腦
4.機器學習在各領域帶來的價值—醫療、航空、教育、物流、電商
讓機器學習程序代替手動步驟,減少企業的成本代替企業的效率
自然語言處理、無人駕駛、計算機視覺、推薦系統等
機器學習的數據:文件CSV
讀取工具是pandas
pandas:一個數據讀取非常方便以及基本處理數據格式的工具。如缺失值處理、數據轉換
numpy:釋放了GIL,真正的多線程
不采用mysql的原因
1.性能瓶頸。讀取速度慢
2.格式不符合機器學習要求的數據格式

網址:
Kaggle網址:https://www.kaggle.com/datasets
UCI數據集網址: http://archive.ics.uci.edu/ml/
scikit-learn網址:http://scikit-learn.org/stable/datasets/index.html
特征值+目標值

特征工程是將原始數據轉換為更好地代表預測模型的潛在問題的特征的過程,從而提高了對未知數據的模型準確性
直接影響預測結果
?Python語言的機器學習工具
?Scikit-learn包括許多知名的機器學習算法的實現
?Scikit-learn文檔完善,容易上手,豐富的API,使其在學術界頗受歡迎。
?特征抽取針對非連續型數據
?特征抽取對文本等進行特征值化,特征值化是為了讓計算機更好的理解數
sklearn特征抽取API:sklearn.feature_extraction
作用:對字典數據進行特征值化
類:sklearn.feature_extraction.DictVectorizerDictVectorizer語法DictVectorizer(sparse=True,…)
# 方法
DictVectorizer.fit_transform(X)
# X:字典或者包含字典的迭代器
# 返回值:返回sparse矩陣
DictVectorizer.inverse_transform(X)
# X:array數組或者sparse矩陣
# 返回值:轉換之前數據格式
DictVectorizer.get_feature_names()
# 返回類別名稱
DictVectorizer.transform(X)
# 按照原先的標準轉換
# 字典特征數據抽取
# 導入包
from sklearn.feature_extraction import DictVectorizerdef dictvec():'''字典特征抽取'''# 實例化,參數默認為sparse=True,此時返回sparse矩陣;參數為sparse=False,返回ndarray數組dict = DictVectorizer(sparse=False)# 調用fict_transfrom方法輸入數據并轉換data = dict.fit_transform([{'city': '北京','temperature':100},{'city': '上海','temperature':60},{'city': '深圳','temperature':30}])# 調用get_feature_names()方法返回類別名稱print(dict.get_feature_names())print(data)if __name__ == '__main__':dictvec()# 如果數據是數組形式,有類別的這些特征需要先轉換成字典數據
# 字典數據抽取:把字典中一些類別數據,分別進行轉換成特征(one-hot編碼)
# ['city=上海', 'city=北京', 'city=深圳', 'temperature']
# sparse=False,如下
# [[ 0. 1. 0. 100.]
# [ 1. 0. 0. 60.]
# [ 0. 0. 1. 30.]]
# one-hot編碼:為每個類別生成一個布爾列,這些列中每列只有一個可以為樣本取值1# sparse=True
# (0, 1) 1.0
# (0, 3) 100.0
# (1, 0) 1.0
# (1, 3) 60.0
# (2, 2) 1.0
# (2, 3) 30.0
作用:對文本數據進行特征值化
類:sklearn.feature_extraction.text.CountVectorizerCountVectorizer語法
CountVectorizer(max_df=1.0,min_df=1,…)
# 返回詞頻矩陣# 方法
CountVectorizer.fit_transform(X,y)
# X:文本或者包含文本字符串的可迭代對象
# 返回值:返回sparse矩陣
CountVectorizer.inverse_transform(X)
# X:array數組或者sparse矩陣
# 返回值:轉換之前數據格式
CountVectorizer.get_feature_names()
# 返回值:單詞列表
# 文本特征抽取---英文
# 導入包
from sklearn.feature_extraction.text import CountVectorizerdef countvec():'''對文本進行特征值化return None'''# 實例化cv = CountVectorizer()# 調用fit_transform方法輸入數據并轉換,返回sparse矩陣data = cv.fit_transform(["life is short,i like python","life is too long,i dislike python"])# 調用get_feature_names()方法,返回單詞列表print(cv.get_feature_names())# CountVectorizer()這個API沒有sparse參數,利用toarray()方法將sparse矩陣轉換array數組print(data.toarray())return Noneif __name__ == '__main__':countvec()# ['dislike', 'is', 'life', 'like', 'long', 'python', 'short', 'too']
# [[0 1 1 1 0 1 1 0]
# [1 1 1 0 1 1 0 1]]
'''1.統計所有文章當中所有的詞,重復的只看做一次-詞的列表2.對每篇文章在詞的列表里面進行統計每個詞出現的次數3.單個字母不統計-單個英文字母沒有分類依據'''
# 文本特征抽取-中文
from sklearn.feature_extraction.text import CountVectorizer
import jieba# 利用jieba包,利用jieba.cut進行分詞,返回值是詞語生成器
# 需要對中文進行分詞才能詳細的進行特征值化
def cutword():con1 = jieba.cut("今天很殘酷,明天更殘酷,后天很美好,但絕對大部分是死在明天晚上,所以每個人不要放棄今天。")con2 = jieba.cut("我們看到的從很遠星系來的光是在幾百萬年之前發出的,這樣當我們看到宇宙時,我們是在看它的過去。")con3 = jieba.cut("如果只用一種方式了解某樣事物,你就不會真正了解它。了解事物真正含義的秘密取決于如何將其與我們所了解的事物相聯系。")# 轉換成列表content1 = list(con1)content2 = list(con2)content3 = list(con3)# 把列表轉換成字符串,用空格隔開c1 = ' '.join(content1)c2 = ' '.join(content2)c3 = ' '.join(content3)return c1, c2, c3def hanzivec():"""中文特征值化:return: None"""c1, c2, c3 = cutword()print(c1, c2, c3)cv = CountVectorizer()data = cv.fit_transform([c1, c2, c3])print(cv.get_feature_names())print(data.toarray())return Noneif __name__ == '__main__':hanzivec()['一種', '不會', '不要', '之前', '了解', '事物', '今天', '光是在', '幾百萬年', '發出', '取決于', '只用', '后天', '含義', '大部分', '如何', '如果', '宇宙', '我們', '所以', '放棄', '方式', '明天', '星系', '晚上', '某樣', '殘酷', '每個', '看到', '真正', '秘密', '絕對', '美好', '聯系', '過去', '這樣']
[[0 0 1 0 0 0 2 0 0 0 0 0 1 0 1 0 0 0 0 1 1 0 2 0 1 0 2 1 0 0 0 1 1 0 0 0][0 0 0 1 0 0 0 1 1 1 0 0 0 0 0 0 0 1 3 0 0 0 0 1 0 0 0 0 2 0 0 0 0 0 1 1][1 1 0 0 4 3 0 0 0 0 1 1 0 1 0 1 1 0 1 0 0 1 0 0 0 1 0 0 0 2 1 0 0 1 0 0]]
TF-IDF的主要思想是:如果某個詞或短語在一篇文章中出現的概率高,
并且在其他文章中很少出現,則認為此詞或者短語具有很好的類別區分
能力,適合用來分類。tf*idf---重要性程度
tf:詞的頻率(term frequency) 出現的次數
idf:逆文檔頻率(inverse document frequency) log(總文檔數量/該詞出現的文檔數量)TF-IDF作用:用以評估一字詞對于一個文件集或一個語料庫中的其中一份文件的重要程度。類:sklearn.feature_extraction.text.TfidfVectorizer
TfidfVectorizer語法TfidfVectorizer(stop_words=None,…)
# 返回詞的權重矩陣
# 方法
TfidfVectorizer.fit_transform(X,y)
# X:文本或者包含文本字符串的可迭代對象
# 返回值:返回sparse矩陣
TfidfVectorizer.inverse_transform(X)
# X:array數組或者sparse矩陣
# 返回值:轉換之前數據格式
TfidfVectorizer.get_feature_names()
# 返回值:單詞列表
# tfidf文本特征抽取
from sklearn.feature_extraction.text import TfidfVectorizer
import jieba
def cutword():con1 = jieba.cut("今天很殘酷,明天更殘酷,后天很美好,但絕對大部分是死在明天晚上,所以每個人不要放棄今天。")con2 = jieba.cut("我們看到的從很遠星系來的光是在幾百萬年之前發出的,這樣當我們看到宇宙時,我們是在看它的過去。")con3 = jieba.cut("如果只用一種方式了解某樣事物,你就不會真正了解它。了解事物真正含義的秘密取決于如何將其與我們所了解的事物相聯系。")# 轉換成列表content1 = list(con1)content2 = list(con2)content3 = list(con3)# 把列表轉換成字符串c1 = ' '.join(content1)c2 = ' '.join(content2)c3 = ' '.join(content3)return c1, c2, c3def tfidfvec():"""中文特征值化:return: None"""c1, c2, c3 = cutword()print(c1, c2, c3)tf = TfidfVectorizer()data = tf.fit_transform([c1, c2, c3])print(tf.get_feature_names())print(data.toarray())return None
if __name__ == '__main__':tfidfvec()# ['一種', '不會', '不要', '之前', '了解', '事物', '今天', '光是在', '幾百萬年', '發出', '取決于', '只用', '后天', '含義', '大部分', '如何', '如果', '宇宙', '我們', '所以', '放棄', '方式', '明天', '星系', '晚上', '某樣', '殘酷', '每個', '看到', '真正', '秘密', '絕對', '美好', '聯系', '過去', '這樣']
# [[0. 0. 0.21821789 0. 0. 0.
# 0.43643578 0. 0. 0. 0. 0.
# 0.21821789 0. 0.21821789 0. 0. 0.
# 0. 0.21821789 0.21821789 0. 0.43643578 0.
# 0.21821789 0. 0.43643578 0.21821789 0. 0.
# 0. 0.21821789 0.21821789 0. 0. 0. ]
# [0. 0. 0. 0.2410822 0. 0.
# 0. 0.2410822 0.2410822 0.2410822 0. 0.
# 0. 0. 0. 0. 0. 0.2410822
# 0.55004769 0. 0. 0. 0. 0.2410822
# 0. 0. 0. 0. 0.48216441 0.
# 0. 0. 0. 0. 0.2410822 0.2410822 ]
# [0.15698297 0.15698297 0. 0. 0.62793188 0.47094891
# 0. 0. 0. 0. 0.15698297 0.15698297
# 0. 0.15698297 0. 0.15698297 0.15698297 0.
# 0.1193896 0. 0. 0.15698297 0. 0.
# 0. 0.15698297 0. 0. 0. 0.31396594
# 0.15698297 0. 0. 0.15698297 0. 0. ]]通過特定的統計方法(數學方法)將數據轉換成算法要求的數據
數值型數據:標準縮放:
1、歸一化
2、標準化
3、缺失值
類別型數據:one-hot編碼
時間類型:時間的切分
sklearn特征處理API:sklearn. preprocessing
特點:通過對原始數據進行變換把數據映射到(默認為[0,1])之間
使得某一特征對最終結果不會造成更大影響,需要進行歸一化
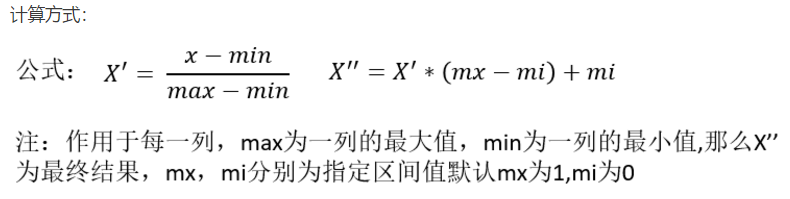
sklearn歸一化API: sklearn.preprocessing.MinMaxScalerMinMaxScaler語法
MinMaxScalar(feature_range=(0,1)…)
# 每個特征縮放到給定范圍(默認[0,1])
# 方法
MinMaxScalar.fit_transform(X)
# X:numpy array格式的數據[n_samples,n_features]
# 返回值:轉換后的形狀相同的array
# 歸一化
from sklearn.preprocessing import MinMaxScaler
def mm():"""歸一化處理:return: NOne"""# 修改feature_range參數來控制縮放范圍,默認(0,1)mm = MinMaxScaler(feature_range=(2, 3))data = mm.fit_transform([[90,2,10,40],[60,4,15,45],[75,3,13,46]])print(data)return Noneif __name__ == '__main__':mm()# [[3. 2. 2. 2. ]
# [2. 3. 3. 2.83333333]
# [2.5 2.5 2.6 3. ]]如果數據中異常點較多,會有什么影響?
如果數據中異常點較多,會有什么影響?
答:歸一化總結
注意在特定場景下最大值最小值是變化的,另外,最大值與最小值非常容易受異常點影響,
所以這種方法魯棒性較差,只適合傳統精確小數據場景。
特點:通過對原始數據進行變換把數據變換到均值為0,方差為1范圍內

結合歸一化來談標準化對于歸一化來說:如果出現異常點,影響了最大值和最小值,那么結果顯然會發生改變
對于標準化來說:如果出現異常點,由于具有一定數據量,少量的異常點對于平均值的影響并不大,從而方差改
變較小。
sklearn特征化API: scikit-learn.preprocessing.StandardScalerStandardScaler語法
StandardScaler(…)
# 處理之后每列來說所有數據都聚集在均值0附近方差為1
# 方法
StandardScaler.fit_transform(X,y)
# X:numpy array格式的數據[n_samples,n_features]
# 返回值:轉換后的形狀相同的arrayStandardScaler.mean_
# 原始數據中每列特征的平均值StandardScaler.std_
# 原始數據每列特征的方差
# 標準化
from sklearn.preprocessing import StandardScalerdef stand():"""標準化縮放:return:"""# 處理之后每列來說所有數據都聚集在均值0附近方差為1std = StandardScaler()data = std.fit_transform([[ 1., -1., 3.],[ 2., 4., 2.],[ 4., 6., -1.]])print(data)return Noneif __name__ == '__main__':stand()# [[-1.06904497 -1.35873244 0.98058068]
# [-0.26726124 0.33968311 0.39223227]
# [ 1.33630621 1.01904933 -1.37281295]]
標準化總結與缺失值處理
標準化總結:
在已有樣本足夠多的情況下比較穩定,適合現代嘈雜大數據場景。缺失值處理:
1.刪除-如果每列或者行數據缺失值達到一定的比例,建議放棄整行或者整列
2.插補-可以通過缺失值每行或者每列的平均值、中位數來填充sklearn缺失值API: sklearn.preprocessing.ImputerImputer語法
# 初始化Imputer,指定”缺失值”,指定填補策略,指定行或列
# 注:缺失值也可以是別的,missing_values指定要替換的值
Imputer(missing_values='NaN', strategy='mean', axis=0)
# 完成缺失值插補
# 方法
Imputer.fit_transform(X,y)
# X:numpy array格式的數據[n_samples,n_features]
# 返回值:轉換后的形狀相同的array# 關于np.nan
1、 numpy的數組中可以使用np.nan/np.NaN來代替缺失值,屬于float類型
2、如果是文件中的一些缺失值,可以替換成nan,通過np.array轉化成float型的數組即可
3.replace('?',np.nan)
# 缺失值處理-SimpleImputer
from sklearn.preprocessing import Imputer
import numpy as npdef im():"""缺失值處理:return:NOne"""# NaN, nanim = Imputer(missing_values='NaN', strategy='mean',axis=0)data = im.fit_transform([[1, 2], [np.nan, 3], [7, 6]])print(data)return None
if __name__ == '__main__':im()# [[1. 2.]
# [4. 3.]
# [7. 6.]]
特征選擇原因
冗余:部分特征的相關度高,容易消耗計算性能
噪聲:部分特征對預測結果有負影響
特征選擇是什么及主要方法
特征選擇就是單純地從提取到的所有特征中選擇部分特征作為訓練集特征,特征在選擇前和選擇后可以改變值、也不改變值,但是選擇后的特征維數肯定比選擇前小,畢竟我們只選擇了其中的一部分特征。
主要方法(三大武器):Filter(過濾式):VarianceThreshold
Embedded(嵌入式):正則化、決策樹
Wrapper(包裹式)
其他特征選擇方法-神經網絡
VarianceThreshold
sklearn特征選擇API:sklearn.feature_selection.VarianceThresholdVarianceThreshold語法# 初始化VarianceThreshold,指定閥值方差
VarianceThreshold(threshold = 0.0)
# 刪除所有低方差特征# 方法
Variance.fit_transform(X,y)
# X:numpy array格式的數據[n_samples,n_features]
# 返回值:訓練集差異低于threshold的特征將被刪除。
#默認值是保留所有非零方差特征,即刪除所有樣本中具有相同值的特征。
# 特征選擇
from sklearn.feature_selection import VarianceThresholddef var():'''特征選擇:刪除低方差的特征return None'''var = VarianceThreshold(threshold=0.0)data = var.fit_transform([[0, 2, 0, 3], [0, 1, 4, 3], [0, 1, 1, 3]])print(data)return Noneif __name__ == '__main__':var()# [[2 0]
# [1 4]
# [1 1]]
PCA是什么
本質:PCA是一種分析、簡化數據集的技術
目的:是數據維數壓縮,盡可能降低原數據的維數(復雜度),損失少量信息。特征數量達到上百個的時候,考慮數據簡化,此時,數據也會改變,特征數量也會減少
作用:可以削減回歸分析或者聚類分析中特征的數量
高維度數據容易出現的問題:特征之間通常是線性相關的,此時就需要PCA
PCA
sklearn降維API:sklearn. decompositionPCA語法
# n_components為小數(0-1)表示百分比,動態指定保留多少特征 90%~95%最佳
# n_components為整數時,減少到的特征數量,一般不使用
PCA(n_components=None)
# 將數據分解為較低維數空間# 方法
PCA.fit_transform(X)
# X:numpy array格式的數據[n_samples,n_features]
# 返回值:轉換后指定維度的array
# PCA降維
from sklearn.decomposition import PCAdef pca():'''主成分分析進行特征降維return None'''pca = PCA(n_components=0.9)data = pca.fit_transform([[2,8,4,5],[6,3,0,8],[5,4,9,1]])print(data)return Noneif __name__ == '__main__':pca()# [[ 1.22879107e-15 3.82970843e+00]
# [ 5.74456265e+00 -1.91485422e+00]
# [-5.74456265e+00 -1.91485422e+00]]
# 用戶對物品類別的喜好細分降維-應該使用juyper notebook# 導入模塊
import pandas as pd
from sklearn.decomposition import PCA# 讀取四張表數據
# 訂單與商品信息
prior = pd.read_csv('./data/instacart/order_products_prior.csv')
# 商品信息
products = pd.read_csv('./data/instacart/products.csv')
# 用戶的訂單信息
orders = pd.read_csv('./data/instacart/orders.csv')
# 商品所屬具體物品類別
aisles = pd.read_csv('./data/instacart/aisles.csv ')# 合并4張表到一張表 (用戶-物品類別)
_mg = pd.merge(prior,products,on=('product_id','product_id'))
_mg = pd.merge(_mg,orders,on=('order_id','order_id'))
_mg = pd.merge(_mg,aisles,on=('aisle_id','aisle_id'))# 查看合并表的前10行
_mg.head(10)# 建立行、列數據,行是用戶、列是物品類別
# 交叉表(特殊分組工具)
cross = pd.crosstab(_mg['use_id'],_mg['aisle'])
cross.head(10)# PCA主成分分析-列表中冗余信息較多
pca = PCA(n_components=0.9)
data = pca.fit_transform(cross)
print(data)
版权声明:本站所有资料均为网友推荐收集整理而来,仅供学习和研究交流使用。

工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态