点击蓝字

关注我们
GaussDB(for MySQL)发布了计算下推框架。针对数据密集型查询,将提取列、条件过滤、聚合运算等操作向下推送给GaussDB(for MySQL)的分布式存储层的多个节点并行执行。通过计算下推,提升并行处理能力,减少网络流量和计算节点的压力,提升查询处理执行效率。
1
NDP介绍
NDP(Near Data Processing)
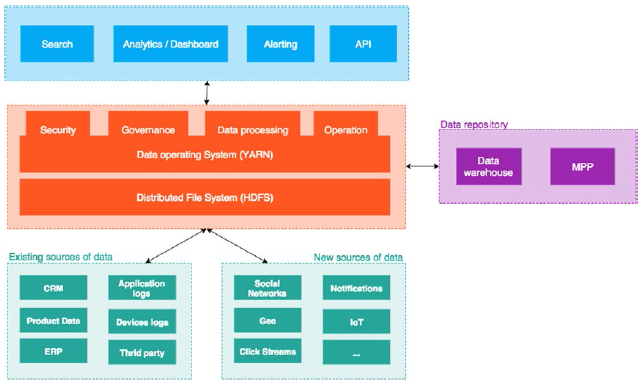
GaussDB(for MySQL)采用计算与存储分离的架构,减少网络流量是主要架构准则,NDP设计将该准则应用到查询操作。没有NDP之前,查询处理需要将原始数据全部传输到计算节点。通过NDP设计,查询中的I/O密集型和CPU密集型的大部分工作被下推到存储节点完成,仅将所需列及筛选后的行或聚合后的结果值回传给计算节点,使网络流量大幅减少。
同时跨存储节点并行处理,计算节点CPU使用率下降,最终带来查询效率性能提升。
NDP框架同GaussDB(for MySQL)并行查询进行融合,并进行了页面批量预取的设计,达成执行全流程并行,进一步提升查询执行效率。
官方架构图如下:
2
PQ(parallel query)
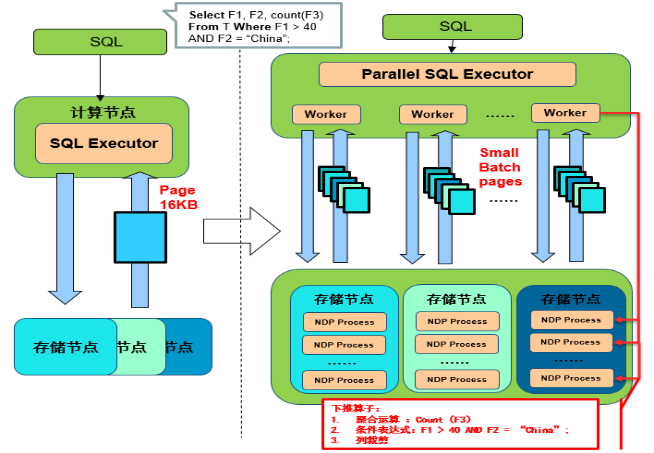
GaussDB(for MySQL)支持了并行执行的查询方式,用以降低分析型查询场景的处理时间,满足企业级应用对查询低时延的要求。并行查询的基本实现原理是将查询任务进行切分并分发到多个CPU核上进行计算,充利用CPU的多核计算资源来缩短查询时间。并行查询的性能提升倍数理论上与CPU的核数正相关,也就是说并行度越高能够使用的CPU核数就越多,性能提升的倍数也就越高。
下图为一个表count(*)的执行过程图:
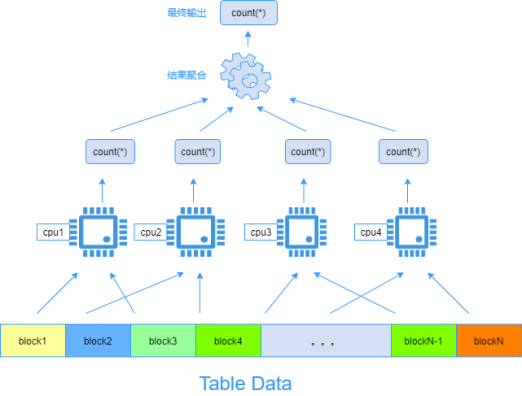
3
对比测试验证
测试服务器参数配置如下:
| 服务器类型 | ECS服务器 | GaussDB(for MySQL) |
|---|---|---|
| CPU | 32个CPU | 16个CPU |
| 内存 | 64G | 32G |
| mysql版本 | 官方社区版8.0.26 | 兼容mysql 8.0 |
| innodb_buffer_pool_size | 32G | 32G |
| 服务器节点 | 一个主节点 | 一个主节点+3个只读节点 |
GaussDB(for MySQL)查看NDP是否开启:
mysql> show variables like 'ndp_mode';+---------------+-------+| Variable_name | Value |
+---------------+-------+| ndp_mode | OFF |
+---------------+-------+1 row in set (0.00 sec)GaussDB(for MySQL)开启NDP查询:
mysql> set ndp_mode=on;Query OK, 0 rows affected (0.00 sec)mysql> explain select-> l_returnflag,-> l_linestatus,-> sum(l_quantity) as sum_qty,-> sum(l_extendedprice) as sum_base_price,-> sum(l_extendedprice * (1 - l_discount)) as sum_disc_price,-> sum(l_extendedprice * (1 - l_discount) * (1 + l_tax)) as sum_charge,-> avg(l_quantity) as avg_qty,-> avg(l_extendedprice) as avg_price,-> avg(l_discount) as avg_disc,-> count(*) as count_order-> from-> lineitem-> where-> l_shipdate <= date '1998-12-01' - interval '90' day-> group by-> l_returnflag,-> l_linestatus-> order by-> l_returnflag,-> l_linestatus\G*************************** 1. row *************************** id: 1select_type: SIMPLE table: lineitem partitions: NULLtype: ALLpossible_keys: NULLkey: NULLkey_len: NULLref: NULLrows: 555253035filtered: 33.33Extra: Using pushed NDP condition ((`tpch`.`lineitem`.`L_SHIPDATE` <= <cache>((DATE'1998-12-01' - interval '90' day)))); Using pushed NDP columns; Using temporary; Using filesort1 row in set, 1 warning (0.00 sec)执行计划有可以看到有Using pushed NDP condition。
或者用hint 开启 NDP_PUSHDOWN ,关掉NDP的hint是 NO_NDP_PUSHDOWN ,如下:
mysql> explain-> select /*+ NDP_PUSHDOWN(t1) */-> l_returnflag,-> l_linestatus,-> sum(l_quantity) as sum_qty,-> sum(l_extendedprice) as sum_base_price,-> sum(l_extendedprice * (1 - l_discount)) as sum_disc_price,-> sum(l_extendedprice * (1 - l_discount) * (1 + l_tax)) as sum_charge,-> avg(l_quantity) as avg_qty,-> avg(l_extendedprice) as avg_price,-> avg(l_discount) as avg_disc,-> count(*) as count_order-> from-> lineitem t1-> where-> l_shipdate <= date '1998-12-01' - interval '90' day-> group by-> l_returnflag,-> l_linestatus-> order by-> l_returnflag,-> l_linestatus \G*************************** 1. row *************************** id: 1select_type: SIMPLE table: t1 partitions: NULLtype: ALLpossible_keys: NULLkey: NULLkey_len: NULLref: NULLrows: 555253035filtered: 33.33Extra: Using pushed NDP condition ((`tpch`.`t1`.`L_SHIPDATE` <= <cache>((DATE'1998-12-01' - interval '90' day)))); Using pushed NDP columns; Using temporary; Using filesort1 row in set, 1 warning (0.00 sec)GaussDB(for MySQL) 开启并行;
全局参数force_parallel_execute来控制是否强制启用并行执行;
使用全局参数parallel_default_dop来控制使用多少线程并行执行;
使用全局参数parallel_cost_threshold来控制当数据规模为多大时开启并行执行。
mysql> SET force_parallel_execute=1;Query OK, 0 rows affected (0.00 sec)mysql> SET parallel_default_dop=16;Query OK, 0 rows affected (0.00 sec)mysql> SET parallel_cost_threshold=0;Query OK, 0 rows affected (0.00 sec)mysql> explain
-> select-> l_returnflag,
-> l_linestatus,
-> sum(l_quantity) as sum_qty,
-> sum(l_extendedprice) as sum_base_price,
-> sum(l_extendedprice * (1 - l_discount)) as sum_disc_price,
-> sum(l_extendedprice * (1 - l_discount) * (1 + l_tax)) as sum_charge,
-> avg(l_quantity) as avg_qty,
-> avg(l_extendedprice) as avg_price,
-> avg(l_discount) as avg_disc,
-> count(*) as count_order
-> from-> lineitem
-> where-> l_shipdate <= date '1998-12-01' - interval '90' day-> group by-> l_returnflag,
-> l_linestatus
-> order by-> l_returnflag,
-> l_linestatus \G*************************** 1. row *************************** id: 1select_type: SIMPLE table: <gather1> partitions: NULLtype: ALLpossible_keys: NULLkey: NULLkey_len: NULLref: NULLrows: 555253035filtered: 33.33Extra: Parallel execute (16 workers, tpch.lineitem)*************************** 2. row *************************** id: 1select_type: SIMPLE table: lineitem partitions: NULLtype: ALLpossible_keys: NULLkey: NULLkey_len: NULLref: NULLrows: 555253035filtered: 33.33Extra: Using pushed NDP condition ((`tpch`.`lineitem`.`L_SHIPDATE` <= <cache>((DATE'1998-12-01' - interval '90' day)))); Using pushed NDP columns; Using temporary; Using filesort2 rows in set, 1 warning (0.00 sec)执行计划中多出来了Parallel execute (16 workers, tpch.lineitem),或用hint开启并行:
mysql> explain-> select /*+ PQ(8) */-> l_returnflag,-> l_linestatus,-> sum(l_quantity) as sum_qty,-> sum(l_extendedprice) as sum_base_price,-> sum(l_extendedprice * (1 - l_discount)) as sum_disc_price,-> sum(l_extendedprice * (1 - l_discount) * (1 + l_tax)) as sum_charge,-> avg(l_quantity) as avg_qty,-> avg(l_extendedprice) as avg_price,-> avg(l_discount) as avg_disc,-> count(*) as count_order-> from-> lineitem t1-> where-> l_shipdate <= date '1998-12-01' - interval '90' day-> group by-> l_returnflag,-> l_linestatus-> order by-> l_returnflag,-> l_linestatus \G*************************** 1. row *************************** id: 1select_type: SIMPLE table: <gather1> partitions: NULLtype: ALLpossible_keys: NULLkey: NULLkey_len: NULLref: NULLrows: 555253035filtered: 33.33Extra: Parallel execute (8 workers, tpch.t1)*************************** 2. row *************************** id: 1select_type: SIMPLE table: t1 partitions: NULLtype: ALLpossible_keys: NULLkey: NULLkey_len: NULLref: NULLrows: 555253035filtered: 33.33Extra: Using where; Using temporary; Using filesort2 rows in set, 1 warning (0.00 sec)以上测试的数据是通过TPC-H 工具导入数据库中,大概100G数据。
TPC-H 是业界常用的一套 Benchmark,由 TPC 委员会制定发布,用于评测数据库的分析型查询能力。TPC-H 查询包含 8 张数据表、22 条复杂的 SQL 查询,大多数查询包含若干表 Join、子查询和 Group-by 聚合等等。
4
测试总结
针对16个测试场景测试结果如下:
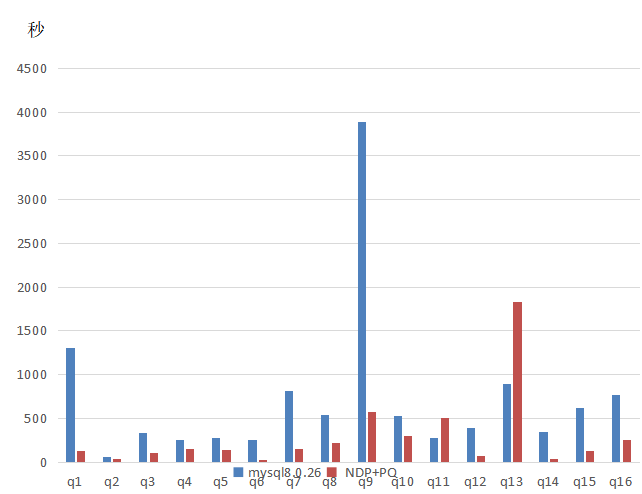
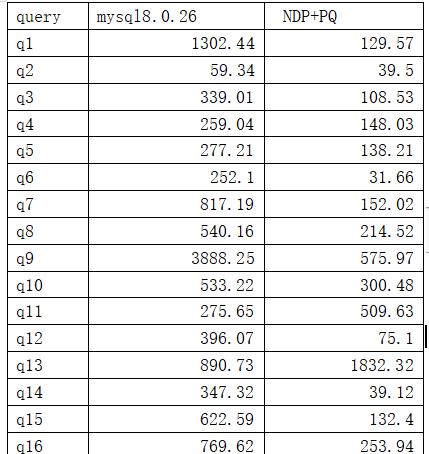
以上图中蓝色为MySQL8.0.26的官方版本查询时间,紫色为GaussDB(for MySQL)的开启NDP和PQ的查询时间,总体来说,GaussDB(for MySQL) 比较快,快的达到了100多倍,当然有些SQL反而比较慢,比如第13个SQL,查看执行计划,不支持并行,官方描述说不支持的可能会变慢。总体来说,GaussDB(for MySQL) 的NDP和PQ提高了很大的性能。
墨天轮原文链接:https://www.modb.pro/db/172928?sjhy(复制到浏览器或者点击“阅读原文”立即查看)
关于作者
黄江平,云和恩墨MySQL DBA, Oracle OCP。现服务于金融证券行业,负责MySQL数据库SQL优化、数据库故障处理、备份恢复、迁级升级、性能优化,有10年的数据库运维经验。
更多数据库行业相关内容,欢迎光临 2021 数据技术嘉年华 :https://www.modb.pro/dtc2021(扫描下方二维码免费领取大会门票)
END
推荐阅读:267页!2020年度数据库技术年刊
推荐下载:2020数据技术嘉年华PPT下载
2020数据技术嘉年华近50个PPT下载、视频回放已上传墨天轮平台,可在“数据和云”公众号回复关键词“2020DTC”获得!
你知道吗?我们的视频号里已经发布了很多精彩的内容,快去看看吧!↓↓↓
点击下图查看更多 ↓



云和恩墨大讲堂 | 一个分享交流的地方
长按,识别二维码,加入万人交流社群
请备注:云和恩墨大讲堂
点个“在看”
你的喜欢会被看到❤
版权声明:本站所有资料均为网友推荐收集整理而来,仅供学习和研究交流使用。

工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态