随着移动互联网的市场份额逐步扩大,手机 APP 已经占据我们的生活,以往的数据分析都借助于爬虫爬取网页数据进行分析,但是新兴的产品有的只有 APP,并没有网页端这对于想要提取数据的我们就遇到了些问题,本章以豆果美食 APP 为例给大家演示如何提取手机的数据。
安装 Fiddler
Fiddler 官网下载地址:http://www.fiddler2.com/fiddl...,笔者是直接在百度搜索的下载版本
安装过程就是下一步下一步最后完成即可,安装好了以后需要配置一些内容
设置允许抓取 HTTPS 信息包
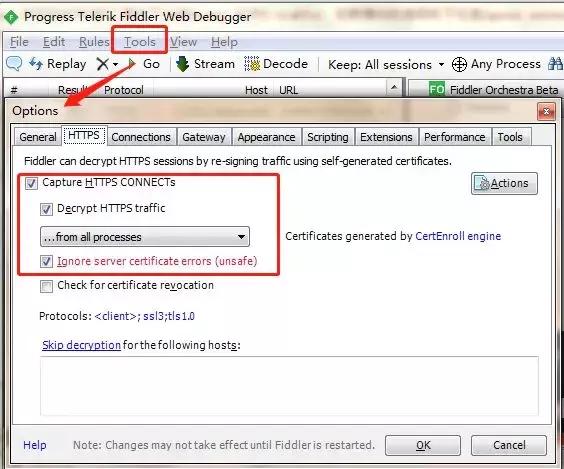
打开下载好的 fiddler,找到 Tools -> Options,然后在 HTTPS 的工具栏下勾选Decrpt HTTPS traffic,在新弹出的选项栏下勾选 Ignore server certificate errors。这样,fiddler 就会抓取到HTTPS的信息包
设置允许外部设备发送 HTTP/HTTPS 到 fiddler
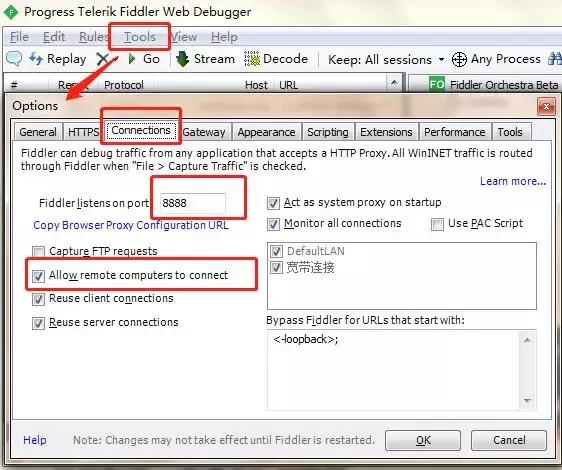
在 Connections 选项栏下勾选 Allow remote computers to connect
连通手机与电脑
想要抓取手机 APP 上的数据一大难点就在于,你并不知道他们数据请求的接口地址是多少,在 PC 端想要抓取一个网站的数据只要访问网址,用抓包工具就可以知道了,所以我们第一步先把环境配置好,就是在手机上访问地址(发送任何网络请求)都可以在电脑上通过 Fiddler 抓取到。
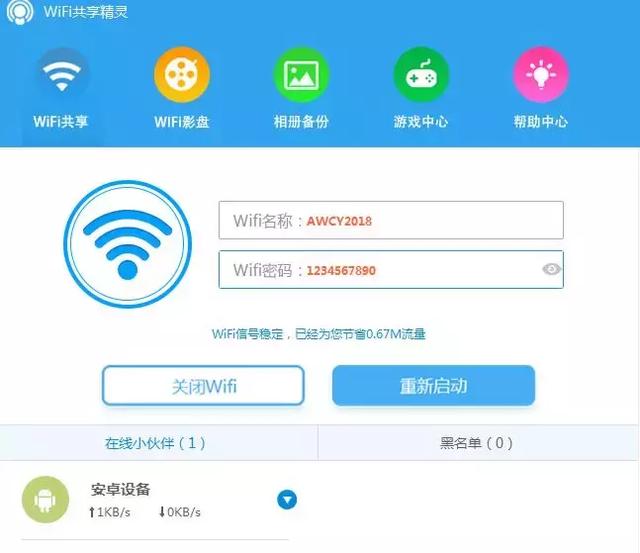
第一步:先保障手机和电脑上面连接网络,我这里是电脑连的网线,我单独安装了一个 Wi-Fi 共享精灵,手机(iphone6s)连接上共享出去的 wifi
第二步:查看电脑 IP 地址
先在电脑上打开 cmd,输入 ipconfig 查看 IP 地址
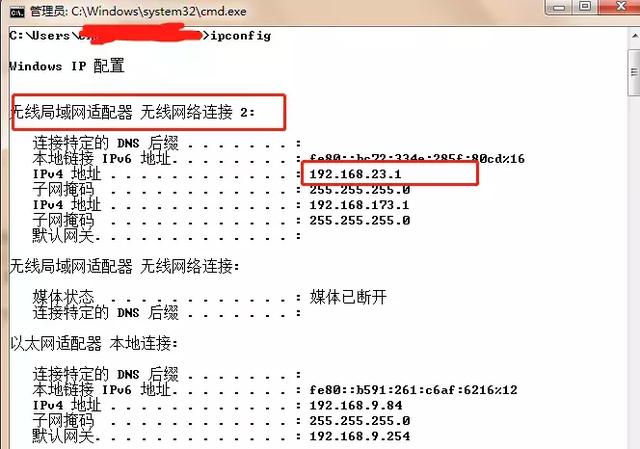
这里要注意 IP 地址用的是无线网络连接这个IP地址,不是本地连接的IP地址(坑点)
第三步:手机设置 HTTP 代理
打开手机无线网络连接,选择已经连接的网络连接,点击一个小圆圈叹号进入可以看到下图,选择配置代理,进入后把刚刚的 IP 地址输入进去,端口就是Fiddler 中设置的 8888 即可。

第四步:手机和电脑端安装证书
电脑端访问:http://localhost:8888/进行安装
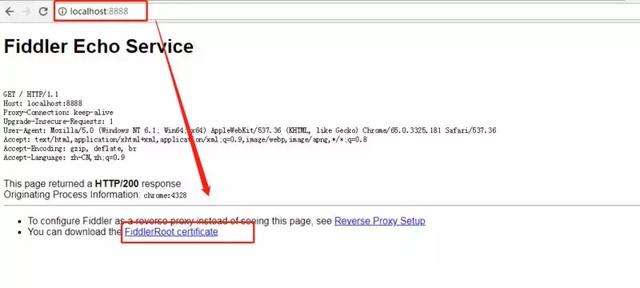
手机访问电脑的IP地址加端口8888即可,我这里的地址是:http://192.168.23.1:8888
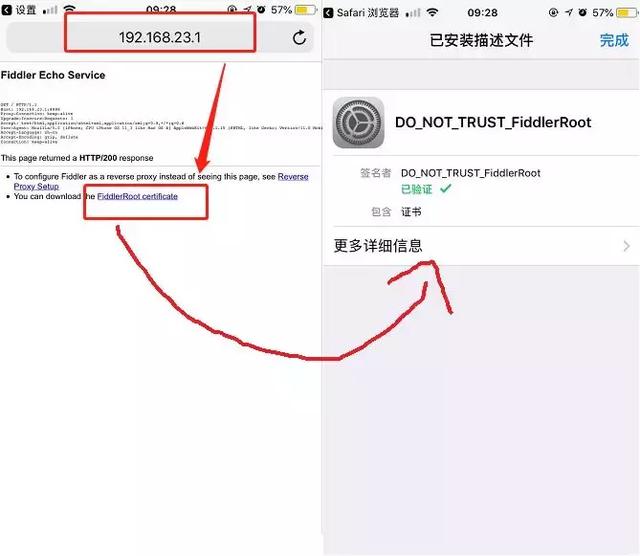
第五步:测试通过
最后就是来测试下,打开手机随便一个 APP,去访问里面的内容,这时打开 fiddler 可以看到所发出的网络请求,我这里打开的是豆果美食 APP
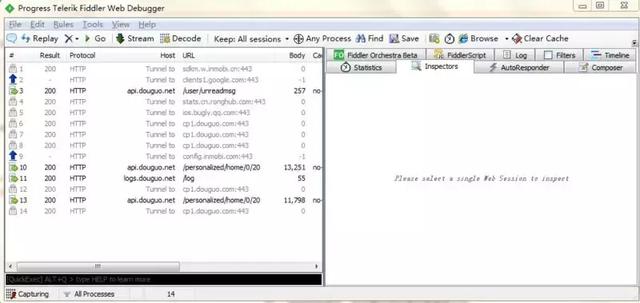
分析手机 APP 请求地址
通过观察 fiddler 中的请求可以发现 http://api.douguo.net/persona...,这个就是请求首页中的部分数据,直接把地址复制到网页中可以看到返回的JSON数据
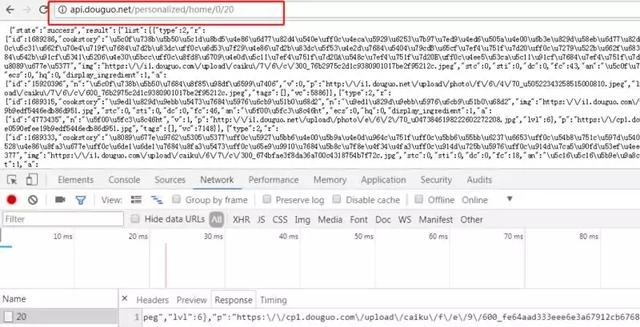
其实这部分内容是最重要也是最困难的一个环节,考验你工作年限的时候到了,要从中剥离出正确的 API 请求,并分析 API 中的数据结构,为后续数据分析做准备。
Python3.x 爬虫获取数据
这里直接通过 urllib.request 进行请求即可,这里并没有使用框架,代码如下:
import urllib.request# 向指定的url地址发送请求,并返回服务器响应的类文件对象response = urllib.request.urlopen("http://api.douguo.net/personalized/home/0/20")# 服务器返回的类文件对象支持Python文件对象的操作方法# read()方法就是读取文件里的全部内容,返回字符串html = response.read() # 打印响应内容print(html.decode("unicode_escape"))运行代码结果打印数据如下
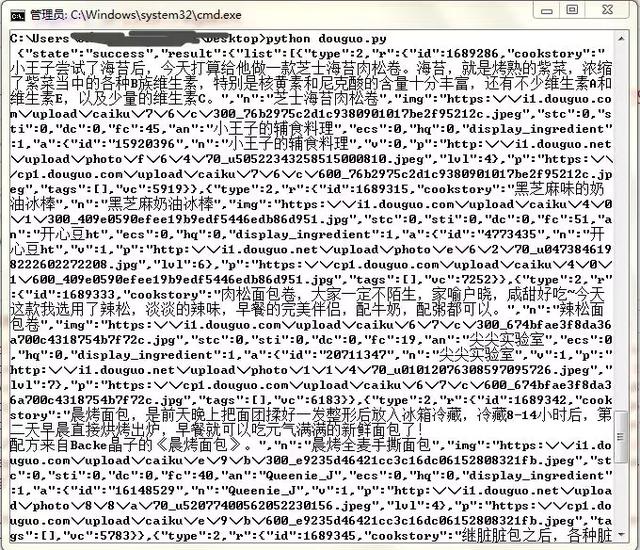
后续对这个数据是存储,还是分析就是后续的操作了,到此我们就已经完成了从手机 APP 中提取数据的步骤
原文:https://segmentfault.com/a/1190000015571256
版权声明:本站所有资料均为网友推荐收集整理而来,仅供学习和研究交流使用。

工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态