1. 插入排序和冒泡排序的時間復雜度
插入排序和冒泡排序的時間復雜度相同,都是 O(n2),在實際的軟件開發里,為什么我們更傾向于使用插入排序算法而不是冒泡排序算法呢?
2. 先看一下排序算法的幾個概念
選擇排序和冒泡排序哪個快,1.原地排序
原地排序(Sorted in place)。原地排序算法,就是特指空間復雜度是 O(1) ,的排序算法;因為只需要定義變量來交互值,所以為O(1)。
2.排序算法的穩定性
僅僅用執行效率和內存消耗來衡量排序算法的好壞是不夠的。針對排序算法,我們還有一個重要的度量指標,穩定性。這個概念是說,如果待排序的序列中存在值相等的元素,經過排序之后,相等元素之間原有的先后順序不變。
arraylist遍歷。 比如我們有一組數據 2,9,3,4,8,3,按照大小排序之后就是 2,3,3,4,8,9。這組數據里有兩個 3。經過某種排序算法排序之后,如果兩個 3 的前后順序沒有改變,那我們就把這種排序算法叫作穩定的排序算法;如果前后順序發生變化,那對應的排序算法就叫作不穩定的排序算法。
兩個 3 哪個在前,哪個在后有什么關系啊,穩不穩定又有什么關系呢?為什么要考察排序算法的穩定性呢?
比如說,我們現在要給電商交易系統中的“訂單”排序。訂單有兩個屬性,一個是下單時間,另一個是訂單金額。如果我們現在有 10 萬條訂單數據,我們希望按照金額從小到大對訂單數據排序。對于金額相同的訂單,我們希望按照下單時間從早到晚有序。對于這樣一個排序需求,我們怎么來做呢? 最先想到的方法是:我們先按照金額對訂單數據進行排序,然后,再遍歷排序之后的訂單數據,對于每個金額相同的小區間再按照下單時間排序。這種排序思路理解起來不難,但是實現起來會很復雜。借助穩定排序算法,這個問題可以非常簡潔地解決。解決思路是這樣的:我們先按照下單時間給訂單排序,注意是按照下單時間,不是金額。排序完成之后,我們用穩定排序算法,按照訂單金額重新排序。兩遍排序之后,我們得到的訂單數據就是按照金額從小到大排序,金額相同的訂單按照下單時間從早到晚排序的。為什么呢? 穩定排序算法可以保持金額相同的兩個對象,在排序之后的前后順序不變。第一次排序之后,所有的訂單按照下單時間從早到晚有序了。在第二次排序中,我們用的是穩定的排序算法,所以經過第二次排序之后,相同金額的訂單仍然保持下單時間從早到晚有序。

arraylist的排序,3. 冒泡排序(Bubble Sort)
冒泡排序只會操作相鄰的兩個數據。每次冒泡操作都會對相鄰的兩個元素進行比較,看是否滿足大小關系要求。如果不滿足就讓它倆互換。一次冒泡會讓至少一個元素移動到它應該在的位置,重復 n 次,就完成了 n 個數據的排序工作。
我們要對一組數據 4,5,6,3,2,1,從小到大進行排序。第一次冒泡操作的詳細過程就是這樣:
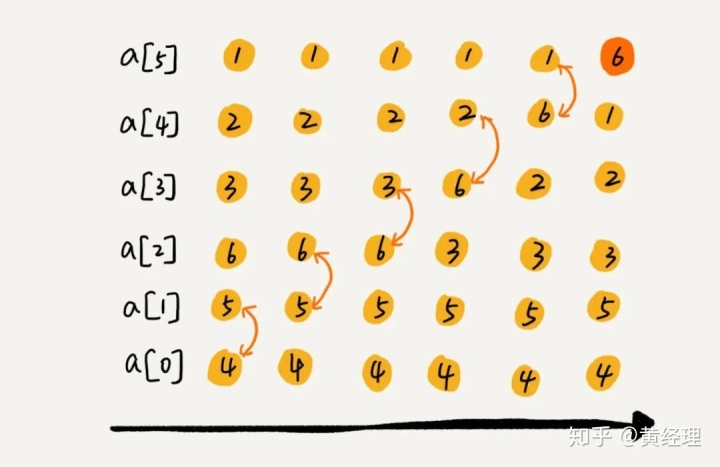
arraylist排序sort,3可以看出,經過一次冒泡操作之后,6 這個元素已經存儲在正確的位置上。要想完成所有數據的排序,我們只要進行 6 次這樣的冒泡操作就行了。

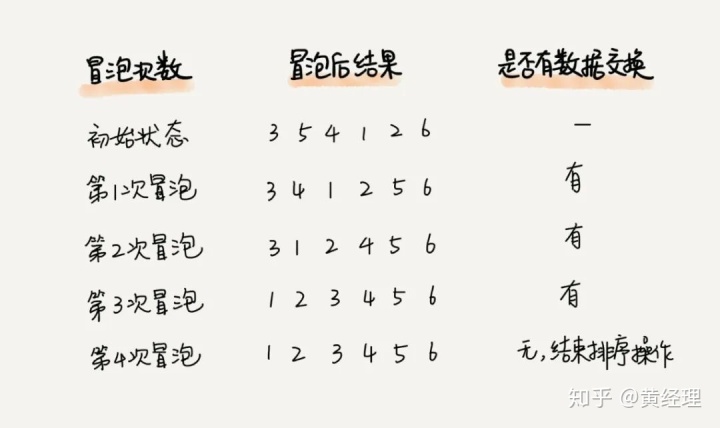
實際上,剛講的冒泡過程還可以優化。當某次冒泡操作已經沒有數據交換時,說明已經達到完全有序,不用再繼續執行后續的冒泡操作。我這里還有另外一個例子,這里面給 6 個元素排序,只需要 4 次冒泡操作就可以了。
arraylist 數組。具體代碼如下所示:

ps:冒泡排序是原地排序,只需要常量級的臨時空間,所以它的空間復雜度為 O(1),是一個原地排序算法。冒泡排序是穩定的排序算法因為我們判斷的是>而不是>=。冒泡排序的時間復雜度最好就是有序的所以是O(n),而最壞就是反序的就是O(n2)。
4.插入排序(Insertion Sort)
歸并排序? 一個有序的數組,我們往里面添加一個新的數據后,如何繼續保持數據有序呢?很簡單,我們只要遍歷數組,找到數據應該插入的位置將其插入即可。
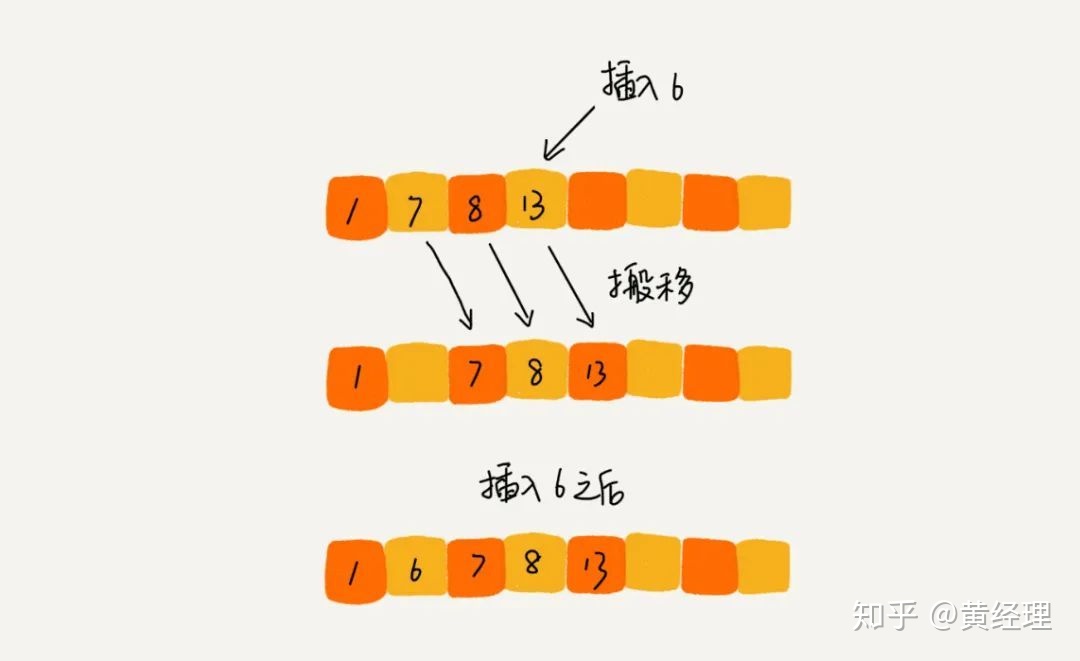
這是一個動態排序的過程,即動態地往有序集合中添加數據,我們可以通過這種方法保持集合中的數據一直有序。而對于一組靜態數據,我們也可以借鑒上面講的插入方法,來進行排序,于是就有了插入排序算法。
那插入排序具體是如何借助上面的思想來實現排序的呢?首先,我們將數組中的數據分為兩個區間,已排序區間和未排序區間。初始已排序區間只有一個元素,就是數組的第一個元素。插入算法的核心思想是取未排序區間中的元素,在已排序區間中找到合適的插入位置將其插入,并保證已排序區間數據一直有序。重復這個過程,直到未排序區間中元素為空,算法結束。如圖所示,要排序的數據是 4,5,6,1,3,2,其中左側為已排序區間,右側是未排序區間。
排序?

插入排序也包含兩種操作,一種是元素的比較,一種是元素的移動。當我們需要將一個數據 a 插入到已排序區間時,需要拿 a 與已排序區間的元素依次比較大小,找到合適的插入位置。找到插入點之后,我們還需要將插入點之后的元素順序往后移動一位,這樣才能騰出位置給元素 a 插入。
插入排序代碼實現如下

ps:插入排序是原地排序,只需要常量級的臨時空間,所以它的空間復雜度為 O(1),是一個原地排序算法。插入排序是穩定的排序算法因為我們判斷的是>而不是>=。插入排序的時間復雜度最好就是有序的所以是O(n),而最壞就是反序的就是O(n2)。
4.為什么插入排序比冒泡排序更受歡迎?
冒泡和插入排序最好時間復雜度和最壞時間復雜度都是O(n)和O(n2),首先我們看一下冒泡排序當比對結果若前比后大則交換位置(從小到大排序時)因為需要交換位置所以需要進行三次賦值操作,而插入排序只需要一次賦值操作,假如我們設每次賦值所需要時間為time那么,冒泡每交換一次就是3*time,而插入則是time,可能在你覺得不就是三次賦值嘛,能消費多少性能,當然在數組排序量不大時,看不出來效果,當數組排序量很大呢?下面我們通過實際測試看看性能上的差距
假定一個需要排序的數組為50000,為了兩個算法對比時數據的一致性,所以我們數組中的默認值都是從小到大排序的,而將他們全部變成從大到小時看看兩種算法所消耗的時間。圖一為測試代碼插入排序的所需時間為圖二,冒泡排序為圖三。
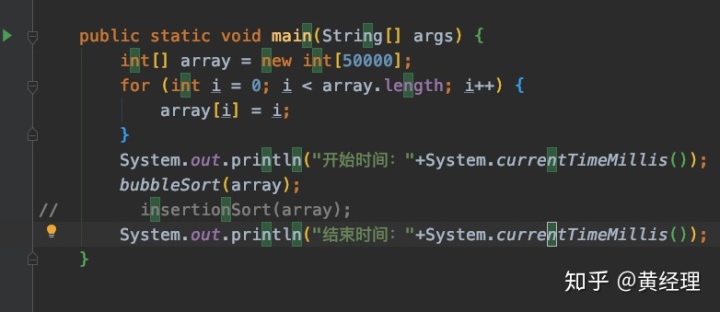
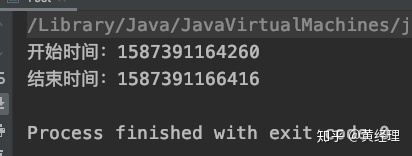
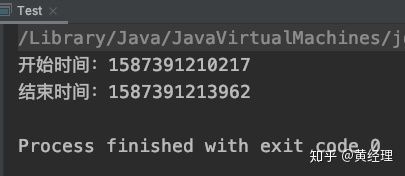
當然實際上在50000的數據量時也不是差距很大,但是如果是更大的呢?如果實際開發中使用到排序在這兩種算法之間進行選擇的話,優先選擇插入排序。
鏈接:為什么插入排序比冒泡排序更受歡迎?
出處:騰訊云
作者: 大貓的Java筆記
版权声明:本站所有资料均为网友推荐收集整理而来,仅供学习和研究交流使用。

工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态