Python時間序列數據分析--以示例說明
標簽(空格分隔): 時間序列數據分析
本文的內容主要來源于博客:本人做了適當的注釋和補充。
https://www.analyticsvidhya.com/blog/2016/02/time-series-forecasting-codes-python/ 英文不錯的讀者可以前去閱讀原文。
在閱讀本文之前 ,推薦先閱讀:http://www.cnblogs.com/bradleon/p/6827109.html
導讀
本文主要分為四個部分:
- 用pandas處理時序數據
- 怎樣檢查時序數據的穩定性
- 怎樣讓時序數據具有穩定性
- 時序數據的預測
1. 用pandas導入和處理時序數據
第一步:導入常用的庫
import pandas as pd
import numpy as np
import matplotlib.pylab as plt
from matplotlib.pylab import rcParams
#rcParams設定好畫布的大小
rcParams['figure.figsize'] = 15, 6第二步:導入時序數據
數據文件可在github:
http://github.com/aarshayj/Analytics_Vidhya/tree/master/Articles/Time_Series_Analysis 中下載
data = pd.read_csv(path+"AirPassengers.csv")
print data.head()
print '\n Data types:'
print data.dtypes運行結果如下:數據包括每個月對應的passenger的數目。
可以看到data已經是一個DataFrame,包含兩列Month和#Passengers,其中Month的類型是object,而index是0,1,2...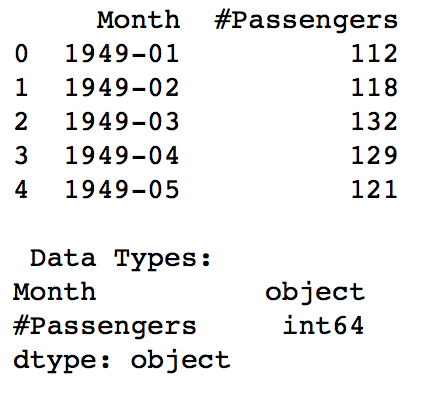
第三步:處理時序數據
我們需要將Month的類型變為datetime,同時作為index。
dateparse = lambda dates: pd.datetime.strptime(dates, '%Y-%m')
#---其中parse_dates 表明選擇數據中的哪個column作為date-time信息,
#---index_col 告訴pandas以哪個column作為 index
#--- date_parser 使用一個function(本文用lambda表達式代替),使一個string轉換為一個datetime變量
data = pd.read_csv('AirPassengers.csv', parse_dates=['Month'], index_col='Month',date_parser=dateparse)
print data.head()
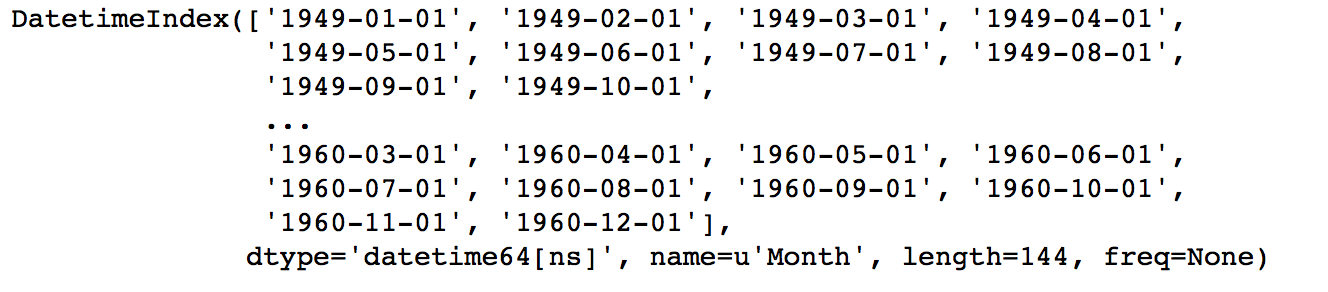
print data.index結果如下:可以看到data的index已經變成datetime類型的Month了。
2.怎樣檢查時序數據的穩定性(Stationarity)
因為ARIMA模型要求數據是穩定的,所以這一步至關重要。
1. 判斷數據是穩定的常基于對于時間是常量的幾個統計量:
- 常量的均值
- 常量的方差
- 與時間獨立的自協方差
用圖像說明如下:
- 均值
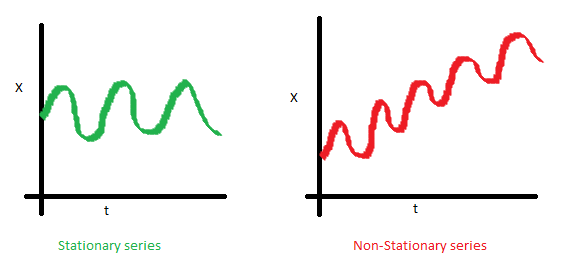
X是時序數據的值,t是時間。可以看到左圖,數據的均值對于時間軸來說是常量,即數據的均值不是時間的函數,所有它是穩定的;右圖隨著時間的推移,數據的值整體趨勢是增加的,所有均值是時間的函數,數據具有趨勢,所以是非穩定的。 - 方差
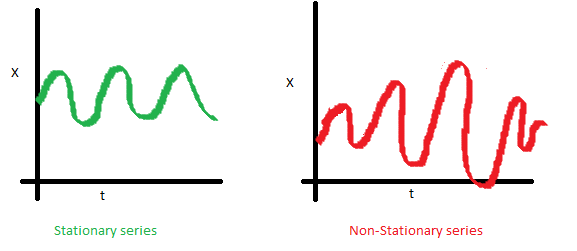
可以看到左圖,數據的方差對于時間是常量,即數據的值域圍繞著均值上下波動的振幅是固定的,所以左圖數據是穩定的。而右圖,數據的振幅在不同時間點不同,所以方差對于時間不是獨立的,數據是非穩定的。但是左、右圖的均值是一致的。 - 自協方差
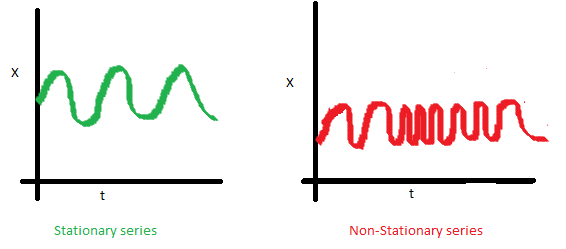
一個時序數據的自協方差,就是它在不同兩個時刻i,j的值的協方差。可以看到左圖的自協方差于時間無關;而右圖,隨著時間的不同,數據的波動頻率明顯不同,導致它i,j取值不同,就會得到不同的協方差,因此是非穩定的。雖然右圖在均值和方差上都是與時間無關的,但仍是非穩定數據。
2. python判斷時序數據穩定性
有兩種方法:
1.Rolling statistic-- 即每個時間段內的平均的數據均值和標準差情況。
- Dickey-Fuller Test -- 這個比較復雜,大致意思就是在一定置信水平下,對于時序數據假設 Null hypothesis: 非穩定。
if 通過檢驗值(statistic)< 臨界值(critical value),則拒絕null hypothesis,即數據是穩定的;反之則是非穩定的。
from statsmodels.tsa.stattools import adfuller
def test_stationarity(timeseries):#這里以一年為一個窗口,每一個時間t的值由它前面12個月(包括自己)的均值代替,標準差同理。rolmean = pd.rolling_mean(timeseries,window=12)rolstd = pd.rolling_std(timeseries, window=12)#plot rolling statistics:fig = plt.figure()fig.add_subplot()orig = plt.plot(timeseries, color = 'blue',label='Original')mean = plt.plot(rolmean , color = 'red',label = 'rolling mean')std = plt.plot(rolstd, color = 'black', label= 'Rolling standard deviation')plt.legend(loc = 'best')plt.title('Rolling Mean & Standard Deviation')plt.show(block=False)#Dickey-Fuller test:print 'Results of Dickey-Fuller Test:'dftest = adfuller(timeseries,autolag = 'AIC')#dftest的輸出前一項依次為檢測值,p值,滯后數,使用的觀測數,各個置信度下的臨界值dfoutput = pd.Series(dftest[0:4],index = ['Test Statistic','p-value','#Lags Used','Number of Observations Used'])for key,value in dftest[4].items():dfoutput['Critical value (%s)' %key] = valueprint dfoutputts = data['#Passengers']
test_stationarity(ts)結果如下: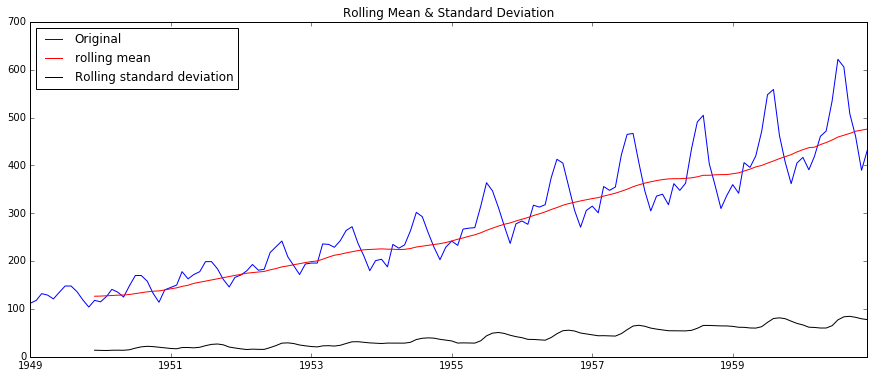

可以看到,數據的rolling均值/標準差具有越來越大的趨勢,是不穩定的。
且DF-test可以明確的指出,在任何置信度下,數據都不是穩定的。
3. 讓時序數據變成穩定的方法
讓數據變得不穩定的原因主要有倆:
- 趨勢(trend)-數據隨著時間變化。比如說升高或者降低。
- 季節性(seasonality)-數據在特定的時間段內變動。比如說節假日,或者活動導致數據的異常。
由于原數據值域范圍比較大,為了縮小值域,同時保留其他信息,常用的方法是對數化,取log。
ts_log = np.log(ts)檢測和去除趨勢
通常有三種方法:- 聚合 : 將時間軸縮短,以一段時間內星期/月/年的均值作為數據值。使不同時間段內的值差距縮小。
- 平滑: 以一個滑動窗口內的均值代替原來的值,為了使值之間的差距縮小
- 多項式過濾:用一個回歸模型來擬合現有數據,使得數據更平滑。
本文主要使用平滑方法
Moving Average--移動平均
moving_avg = pd.rolling_mean(ts_log,12)
plt.plot(ts_log ,color = 'blue')
plt.plot(moving_avg, color='red')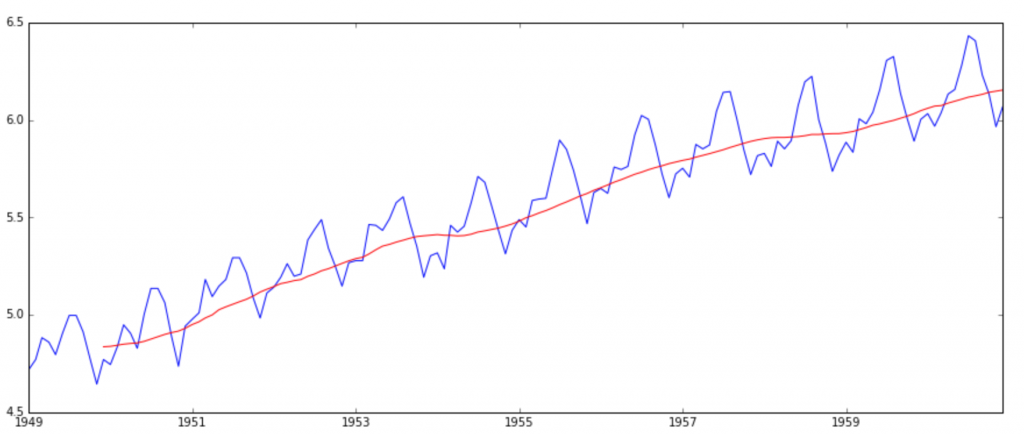
可以看出moving_average要比原值平滑許多。
然后作差:
ts_log_moving_avg_diff = ts_log-moving_avg
ts_log_moving_avg_diff.dropna(inplace = True)
test_stationarity(ts_log_moving_avg_diff)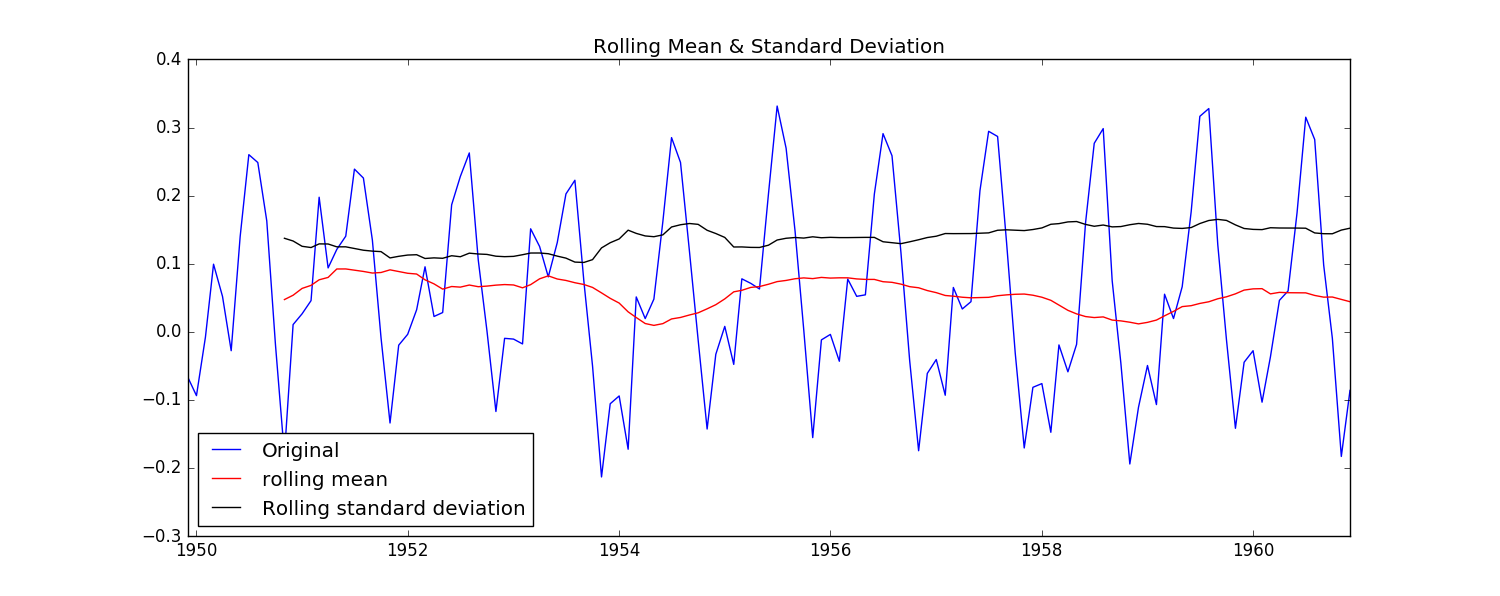

可以看到,做了處理之后的數據基本上沒有了隨時間變化的趨勢,DFtest的結果告訴我們在95%的置信度下,數據是穩定的。
上面的方法是將所有的時間平等看待,而在許多情況下,可以認為越近的時刻越重要。所以引入指數加權移動平均-- Exponentially-weighted moving average.(pandas中通過ewma()函數提供了此功能。)
# halflife的值決定了衰減因子alpha: alpha = 1 - exp(log(0.5) / halflife)
expweighted_avg = pd.ewma(ts_log,halflife=12)
ts_log_ewma_diff = ts_log - expweighted_avg
test_stationarity(ts_log_ewma_diff)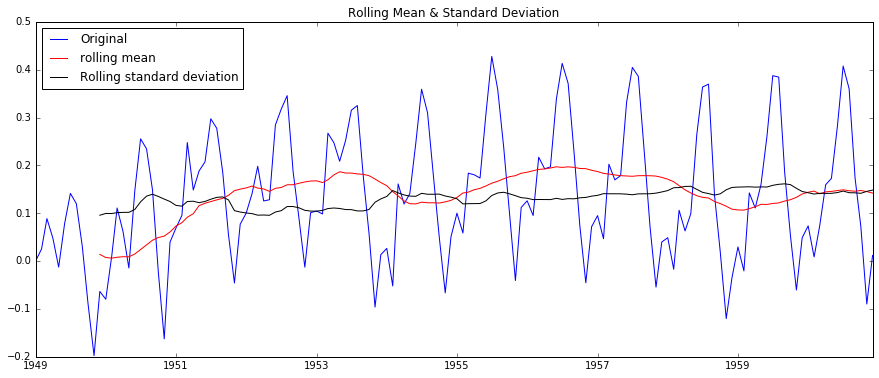
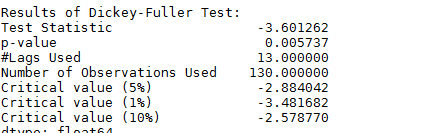
可以看到相比普通的Moving Average,新的數據平均標準差更小了。而且DFtest可以得到結論:數據在99%的置信度上是穩定的。
檢測和去除季節性
有兩種方法:- 1 差分化: 以特定滯后數目的時刻的值的作差
- 2 分解: 對趨勢和季節性分別建模在移除它們
Differencing--差分
ts_log_diff = ts_log - ts_log.shift()
ts_log_diff.dropna(inplace=True)
test_stationarity(ts_log_diff)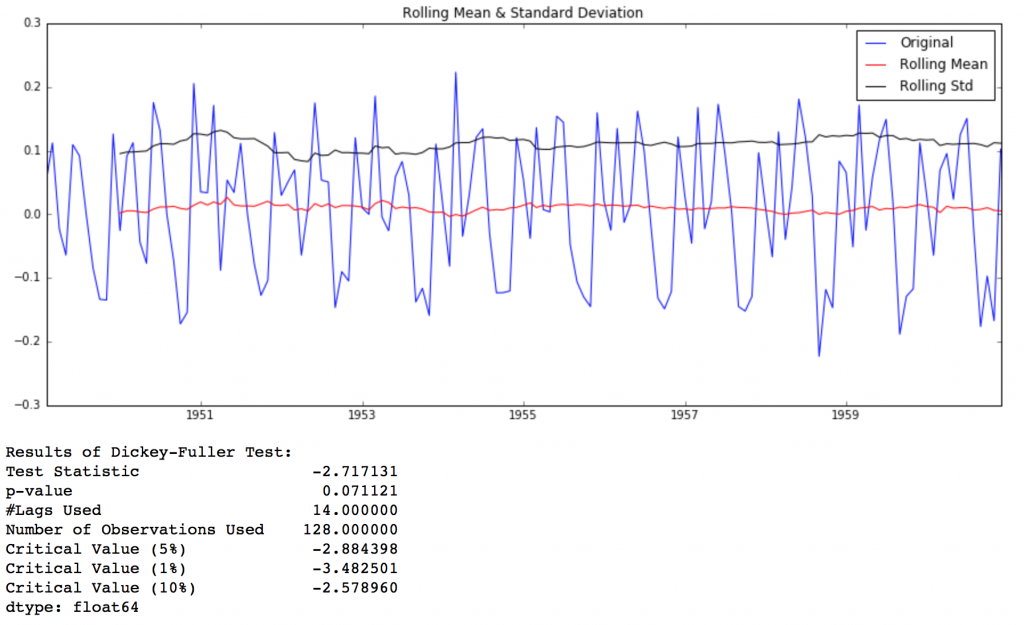
如圖,可以看出相比MA方法,Differencing方法處理后的數據的均值和方差的在時間軸上的振幅明顯縮小了。DFtest的結論是在90%的置信度下,數據是穩定的。
3.Decomposing-分解
#分解(decomposing) 可以用來把時序數據中的趨勢和周期性數據都分離出來:
from statsmodels.tsa.seasonal import seasonal_decompose
def decompose(timeseries):# 返回包含三個部分 trend(趨勢部分) , seasonal(季節性部分) 和residual (殘留部分)decomposition = seasonal_decompose(timeseries)trend = decomposition.trendseasonal = decomposition.seasonalresidual = decomposition.residplt.subplot(411)plt.plot(ts_log, label='Original')plt.legend(loc='best')plt.subplot(412)plt.plot(trend, label='Trend')plt.legend(loc='best')plt.subplot(413)plt.plot(seasonal,label='Seasonality')plt.legend(loc='best')plt.subplot(414)plt.plot(residual, label='Residuals')plt.legend(loc='best')plt.tight_layout()return trend , seasonal, residual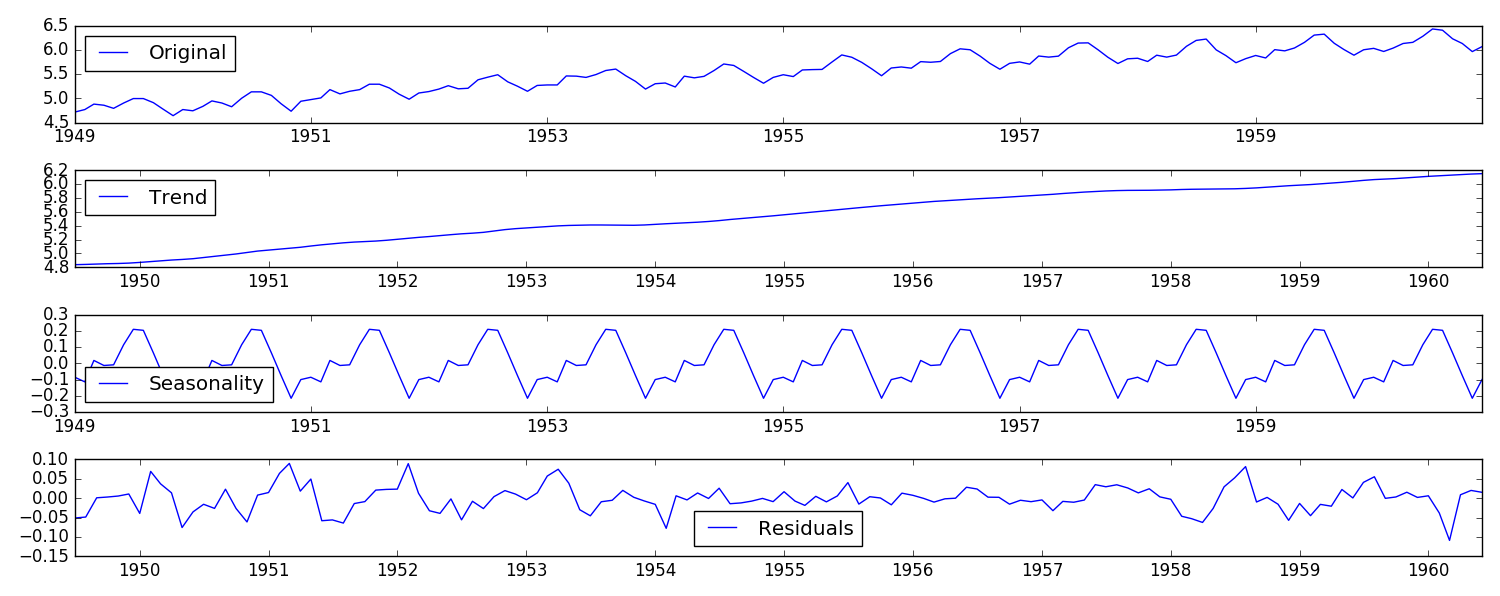
如圖可以明顯的看到,將original數據 拆分成了三份。Trend數據具有明顯的趨勢性,Seasonality數據具有明顯的周期性,Residuals是剩余的部分,可以認為是去除了趨勢和季節性數據之后,穩定的數據,是我們所需要的。
#消除了trend 和seasonal之后,只對residual部分作為想要的時序數據進行處理
trend , seasonal, residual = decompose(ts_log)
residual.dropna(inplace=True)
test_stationarity(residual)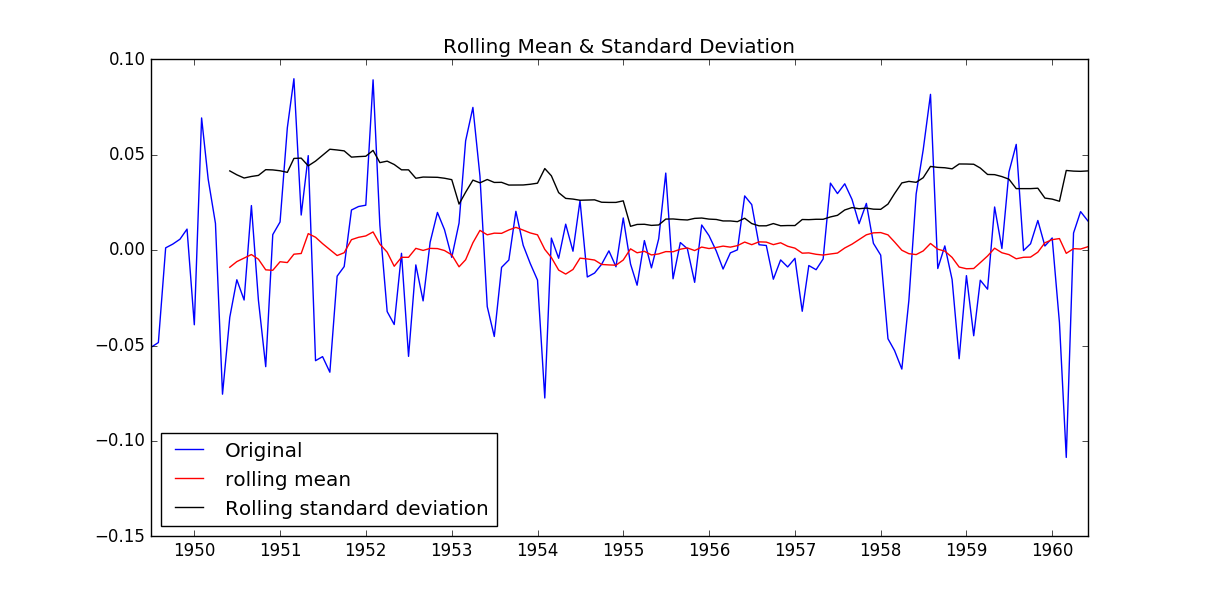
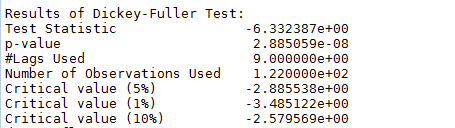
如圖所示,數據的均值和方差趨于常數,幾乎無波動(看上去比之前的陡峭,但是要注意他的值域只有[-0.05,0.05]之間),所以直觀上可以認為是穩定的數據。另外DFtest的結果顯示,Statistic值原小于1%時的Critical value,所以在99%的置信度下,數據是穩定的。
4. 對時序數據進行預測
假設經過處理,已經得到了穩定時序數據。接下來,我們使用ARIMA模型
對數據已經預測。ARIMA的介紹可以見本目錄下的另一篇文章。
step1: 通過ACF,PACF進行ARIMA(p,d,q)的p,q參數估計
由前文Differencing部分已知,一階差分后數據已經穩定,所以d=1。
所以用一階差分化的ts_log_diff = ts_log - ts_log.shift() 作為輸入。
等價于\[y_t = Y_t-Y_{t-1}\]作為輸入。
先畫出ACF,PACF的圖像,代碼如下:
#ACF and PACF plots:
from statsmodels.tsa.stattools import acf, pacf
lag_acf = acf(ts_log_diff, nlags=20)
lag_pacf = pacf(ts_log_diff, nlags=20, method='ols')
#Plot ACF:
plt.subplot(121)
plt.plot(lag_acf)
plt.axhline(y=0,linestyle='--',color='gray')
plt.axhline(y=-1.96/np.sqrt(len(ts_log_diff)),linestyle='--',color='gray')
plt.axhline(y=1.96/np.sqrt(len(ts_log_diff)),linestyle='--',color='gray')
plt.title('Autocorrelation Function')#Plot PACF:
plt.subplot(122)
plt.plot(lag_pacf)
plt.axhline(y=0,linestyle='--',color='gray')
plt.axhline(y=-1.96/np.sqrt(len(ts_log_diff)),linestyle='--',color='gray')
plt.axhline(y=1.96/np.sqrt(len(ts_log_diff)),linestyle='--',color='gray')
plt.title('Partial Autocorrelation Function')
plt.tight_layout()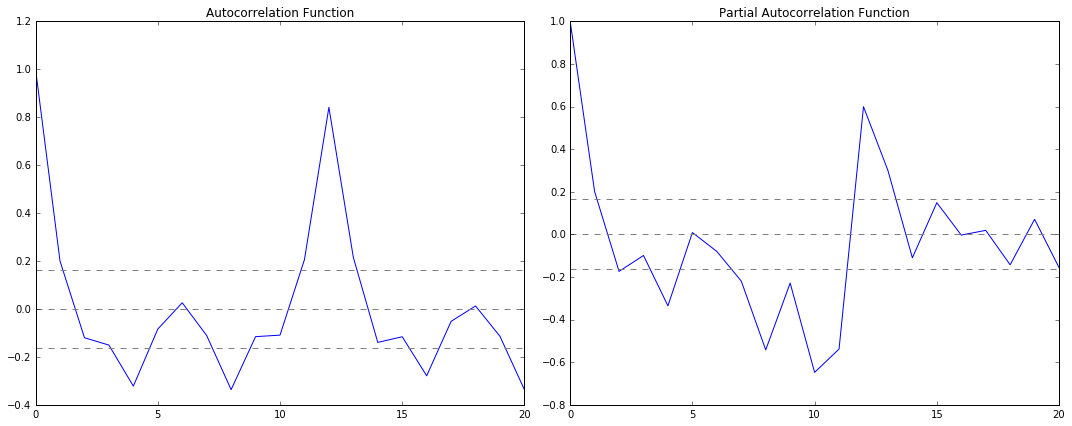
圖中,上下兩條灰線之間是置信區間,p的值就是ACF第一次穿過上置信區間時的橫軸值。q的值就是PACF第一次穿過上置信區間的橫軸值。所以從圖中可以得到p=2,q=2。
step2: 得到參數估計值p,d,q之后,生成模型ARIMA(p,d,q)
為了突出差別,用三種參數取值的三個模型作為對比。
模型1:AR模型(ARIMA(2,1,0))
from statsmodels.tsa.arima_model import ARIMA
model = ARIMA(ts_log, order=(2, 1, 0))
results_AR = model.fit(disp=-1)
plt.plot(ts_log_diff)
plt.plot(results_AR.fittedvalues, color='red')
plt.title('RSS: %.4f'% sum((results_AR.fittedvalues-ts_log_diff)**2))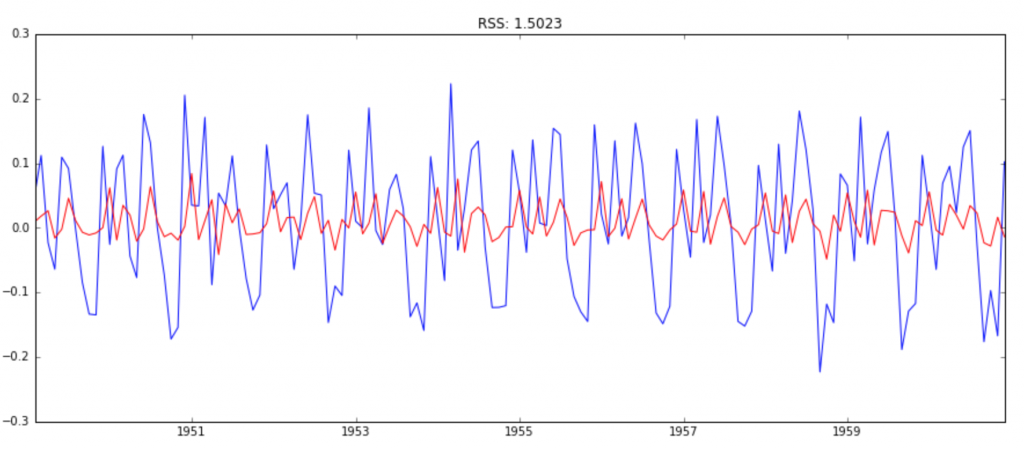
圖中,藍線是輸入值,紅線是模型的擬合值,RSS的累計平方誤差。
模型2:MA模型(ARIMA(0,1,2))
model = ARIMA(ts_log, order=(0, 1, 2))
results_MA = model.fit(disp=-1)
plt.plot(ts_log_diff)
plt.plot(results_MA.fittedvalues, color='red')
plt.title('RSS: %.4f'% sum((results_MA.fittedvalues-ts_log_diff)**2))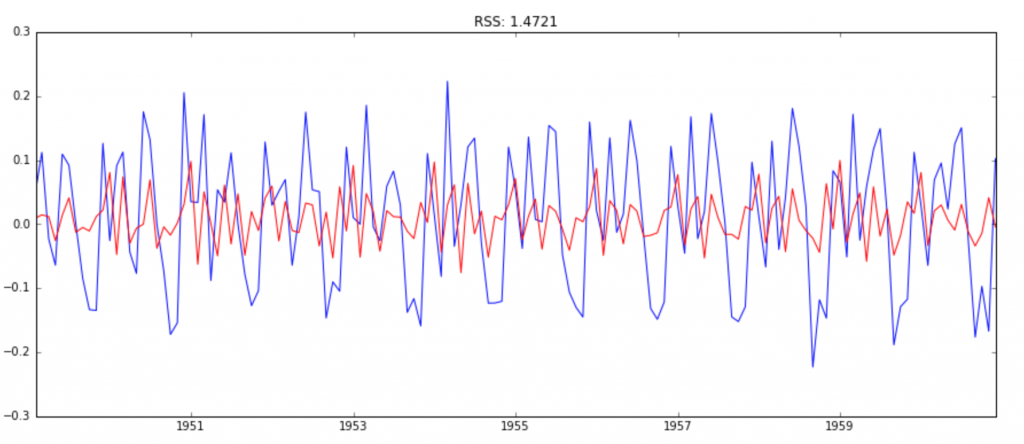
模型3:ARIMA模型(ARIMA(2,1,2))
model = ARIMA(ts_log, order=(2, 1, 2))
results_ARIMA = model.fit(disp=-1)
plt.plot(ts_log_diff)
plt.plot(results_ARIMA.fittedvalues, color='red')
plt.title('RSS: %.4f'% sum((results_ARIMA.fittedvalues-ts_log_diff)**2))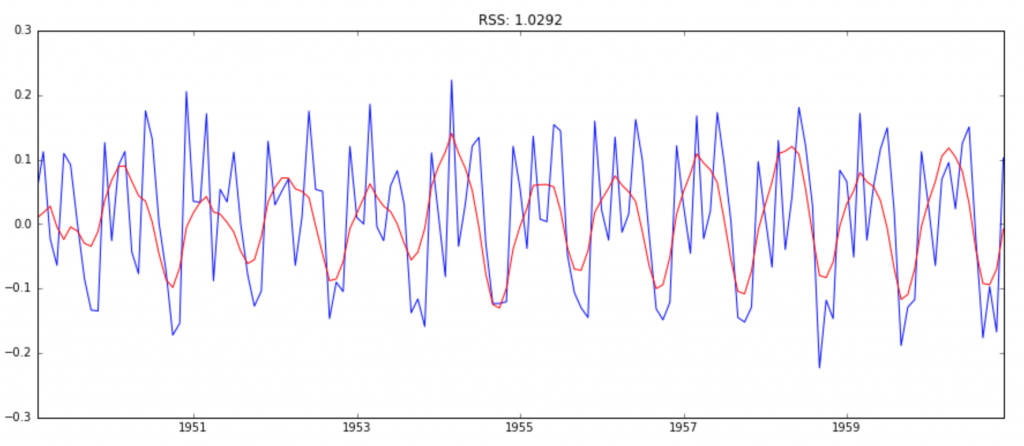
由RSS,可知模型3--ARIMA(2,1,2)的擬合度最好,所以我們確定了最終的預測模型。
step3: 將模型代入原數據進行預測
因為上面的模型的擬合值是對原數據進行穩定化之后的輸入數據的擬合,所以需要對擬合值進行相應處理的逆操作,使得它回到與原數據一致的尺度。
#ARIMA擬合的其實是一階差分ts_log_diff,predictions_ARIMA_diff[i]是第i個月與i-1個月的ts_log的差值。
#由于差分化有一階滯后,所以第一個月的數據是空的,
predictions_ARIMA_diff = pd.Series(results_ARIMA.fittedvalues, copy=True)
print predictions_ARIMA_diff.head()
#累加現有的diff,得到每個值與第一個月的差分(同log底的情況下)。
#即predictions_ARIMA_diff_cumsum[i] 是第i個月與第1個月的ts_log的差值。
predictions_ARIMA_diff_cumsum = predictions_ARIMA_diff.cumsum()
#先ts_log_diff => ts_log=>ts_log => ts
#先以ts_log的第一個值作為基數,復制給所有值,然后每個時刻的值累加與第一個月對應的差值(這樣就解決了,第一個月diff數據為空的問題了)
#然后得到了predictions_ARIMA_log => predictions_ARIMA
predictions_ARIMA_log = pd.Series(ts_log.ix[0], index=ts_log.index)
predictions_ARIMA_log = predictions_ARIMA_log.add(predictions_ARIMA_diff_cumsum,fill_value=0)
predictions_ARIMA = np.exp(predictions_ARIMA_log)
plt.figure()
plt.plot(ts)
plt.plot(predictions_ARIMA)
plt.title('RMSE: %.4f'% np.sqrt(sum((predictions_ARIMA-ts)**2)/len(ts)))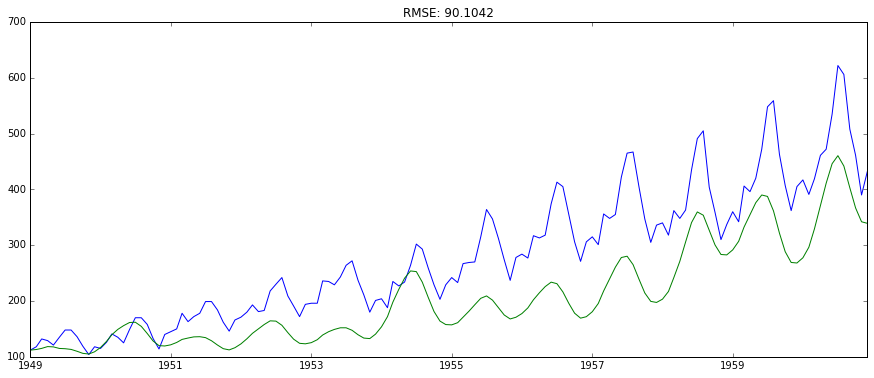
5.總結
前面一篇文章,總結了ARIMA建模的步驟。
(1). 獲取被觀測系統時間序列數據;
(2). 對數據繪圖,觀測是否為平穩時間序列;對于非平穩時間序列要先進行d階差分運算,化為平穩時間序列;
(3). 經過第二步處理,已經得到平穩時間序列。要對平穩時間序列分別求得其自相關系數ACF 和偏自相關系數PACF,通過對自相關圖和偏自相關圖的分析,得到最佳的階層 p 和階數 q
(4). 由以上得到的d、q、p,得到ARIMA模型。然后開始對得到的模型進行模型檢驗。
具體例子會在另一篇文章中給出。
本文結合一個例子,說明python如何解決:
1.判斷一個時序數據是否是穩定。對應步驟(1)
- 怎樣讓時序數據穩定化。對應步驟(2)
- 使用ARIMA模型進行時序數據預測。對應步驟(3,4)
另外對data science感興趣的同學可以關注這個網站,干貨還挺多的。
https://www.analyticsvidhya.com/blog/