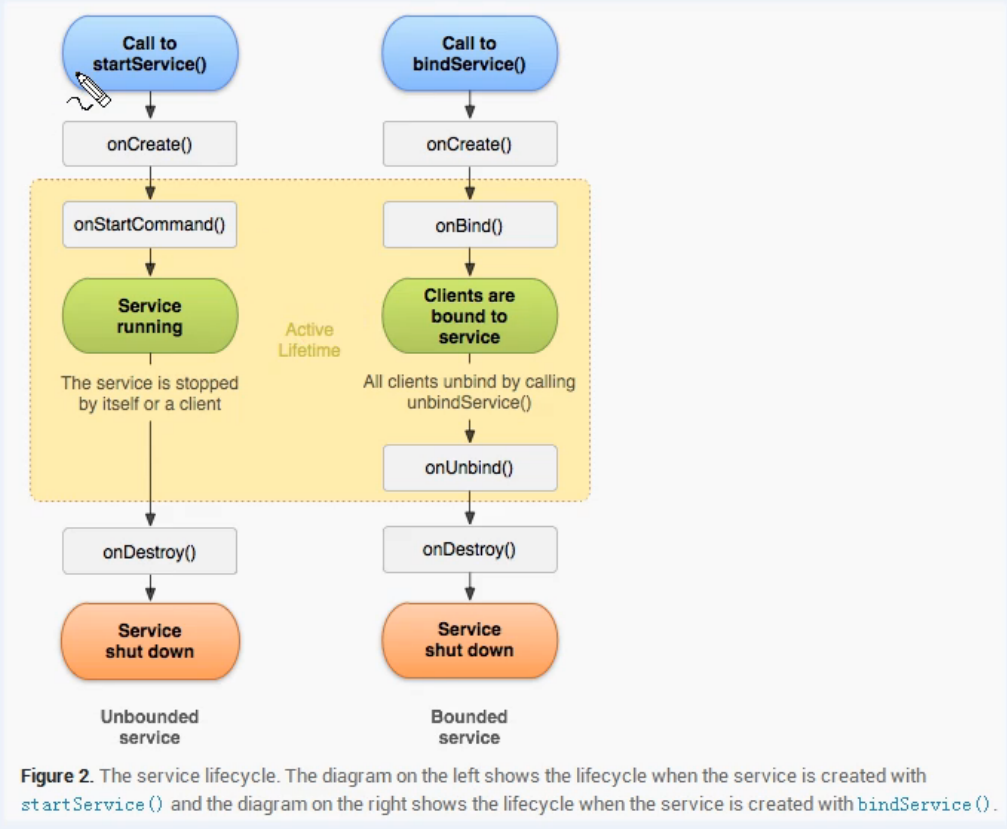
信用標準評分卡模型開發及實現的文章,是標準的評分卡建模流程在R上的實現,非常不錯,就想著能不能把開發流程在Python上實驗一遍呢,經過一番折騰后,終于在Python上用類似的代碼和包實現出來,由于Python和R上函數的差異以及樣本抽樣的差異,本文的結果與該文有一定的差異,這是意料之中的,也是正常,接下來就介紹建模的流程和代碼實現。 #####代碼中需要引用的包##### import numpy as np import pandas as pd from sklearn.utils import shuffle from sklearn.feature_selection import RFE, f_regression import scipy.stats.stats as stats import matplotlib.pyplot as plt from sklearn.linear_model import LogisticRegression import math
用python做量化分析,二、數據集準備
加州大學機器學習數據庫中的german credit data,原本是存在R包”klaR”中的GermanCredit,我在R中把它加載進去,然后導出csv,最終導入Python作為數據集 ############## R ################# library(klaR) data(GermanCredit ,package="klaR") write.csv(GermanCredit,"/filePath/GermanCredit.csv")
Python中評委為選手打分、>>> df_raw = pd.read_csv('/filePath/GermanCredit.csv') >>> df_raw.dtypes Unnamed: 0 int64 status object duration int64 credit_history object purpose object amount int64 savings object employment_duration object installment_rate int64 personal_status_sex object other_debtors object present_residence int64 property object age int64 other_installment_plans object housing object number_credits int64 job object people_liable int64 telephone object foreign_worker object credit_risk object
#提取樣本訓練集和測試集 def split_data(data, ratio=0.7, seed=None): if seed: shuffle_data = shuffle(data, random_state=seed) else: shuffle_data = shuffle(data, random_state=np.random.randint(10000)) train = shuffle_data.iloc[:int(ratio*len(shuffle_data)), ] test = shuffle_data.iloc[int(ratio*len(shuffle_data)):, ] return train, test #設置seed是為了保證下次拆分的結果一致 df_train,df_test = split_data(df_raw, ratio=0.7, seed=666) #將違約樣本用“1”表示,正常樣本用“0”表示。 credit_risk = [0 if x=='good' else 1 for x in df_train['credit_risk']] #credit_risk = np.where(df_train['credit_risk'] == 'good',0,1) data = df_train data['credit_risk']=credit_risk
三、定量指標篩選
#獲取定量指標 quant_index = np.where(data.dtypes=='int64') quant_vars = np.array(data.columns)[quant_index] quant_vars = np.delete(quant_vars,0)
df_feature = pd.DataFrame(data,columns=['duration','amount','installment_rate','present_residence','age','number_credits','people_liable']) f_regression(df_feature,credit_risk) #輸出逐步回歸后得到的變量,選擇P值<=0.1的變量 quant_model_vars = ["duration","amount","age","installment_rate"]
四、定性指標篩選
def woe(bad, good): return np.log((bad/bad.sum())/(good/good.sum())) all_iv = np.empty(len(factor_vars)) woe_dict = dict() #存起來后續有用 i = 0 for var in factor_vars: data_group = data.groupby(var)['credit_risk'].agg([np.sum,len]) bad = data_group['sum'] good = data_group['len']-bad woe_dict[var] = woe(bad,good) iv = ((bad/bad.sum()-good/good.sum())*woe(bad,good)).sum() all_iv[i] = iv i = i+1 high_index = np.where(all_iv>0.1) qual_model_vars = factor_vars[high_index]
至此,就完成了數據集的準備和指標的篩選,下面就要進行邏輯回歸模型的建模了,請見
版权声明:本站所有资料均为网友推荐收集整理而来,仅供学习和研究交流使用。

工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态