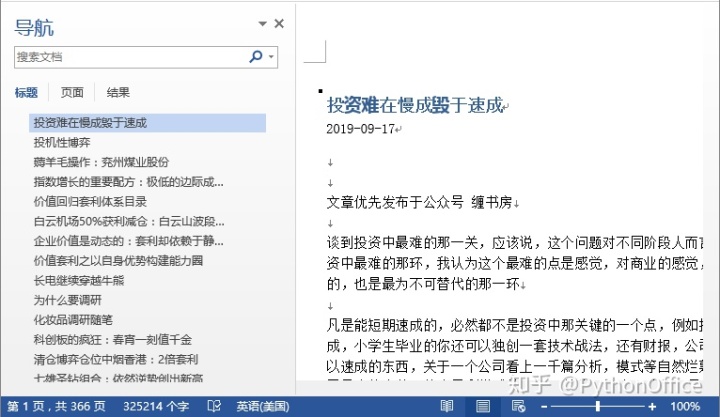
看上博客上一个作者的文章,想一次性下载到一个word文件中,并且可以设置好目录,通过word的“导航窗格”快速定位单篇文章。一劳永逸,从此再也不用去博客上一篇一篇地翻阅了。整理一下步骤:
python怎样爬取网页一篇文章、下面就按照以上步骤进行操作。
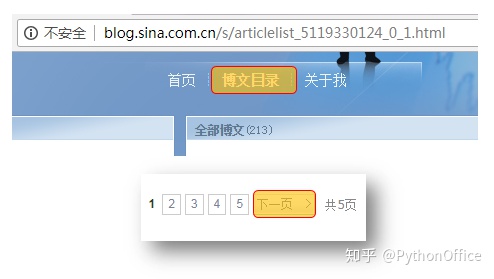
先进入到目标博客的主页,点击“博文目录”,这样就在网址栏看到“http://blog.sina.com.cn/s/articlelist_5119330124_0_1.html” 。再点击下一页,可以看到网址末尾的“1”变成了“2”。这样我们就知道所有页对应的网址了(尾号从1到5)。
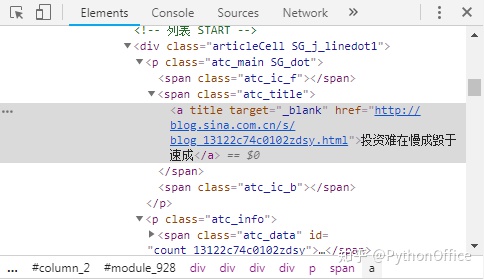
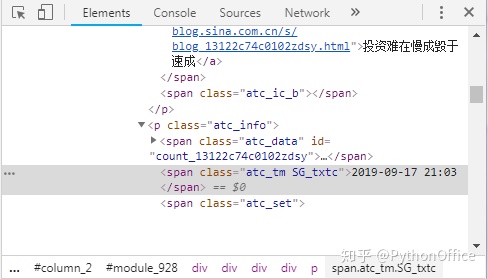
python爬取软件里面的信息?先挑第一页的网址,定位我们需要的信息,以便后续批量爬取。在博文的标题和发表日期上分别点右键,选择“检查”,在浏览器右侧看到如下信息。可见博文标题和博文链接都位于class="atc_title"下面,发表时间位于class="atc_tm SG_txtc"下面。
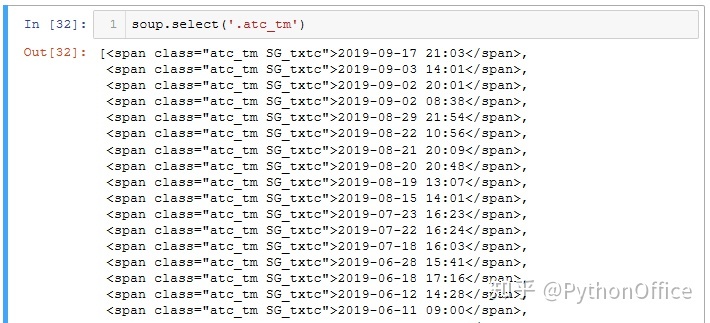
python爬取网页内容。因此使用soup.select('.atc_title')就可以获取当前网页的所有博文的链接和标题;使用soup.select('.atc_tm')可获取所有博文的发表日期。慢着,不是发表时间对应的class是"atc_tm SG_txtc"吗?怎么这里只取了atc_tm呢?这是因为atc_tm和SG_txtc之间有个空格,如果原样取,反而找不到目标。取二者之一或者将空格换成"."才能定位目标。这个涉及到网页编程语言了,就不深究了,我们只需要知道有这个坑,并且了解如何避坑就行。
import requests
from bs4 import BeautifulSoup
url = f'http://blog.sina.com.cn/s/articlelist_5119330124_0_1.html'
wb_data = requests.get(url)
soup = BeautifulSoup(wb_data.content)
#获取当页所有文章的标题和链接
soup.select('.atc_title')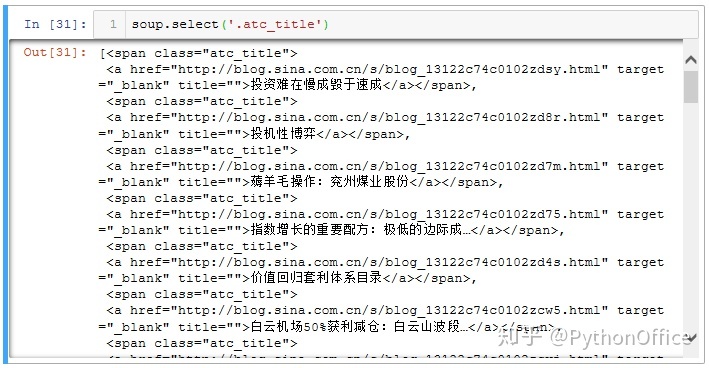
python 爬取。如上获取的文章标题及链接信息是存在一个大列表中的。现在以第一个元素为例从中提取出链接和标题信息。观察发现链接位于a标签里的href里面,于是使用select方法选中a标签,可以看到结果是一个新的列表(如下)。
soup.select('.atc_title')[0].select('a')
>>
[<a href="http://blog.sina.com.cn/s/blog_13122c74c0102zdsy.html" target="_blank" title="">投资难在慢成毁于速成</a>]然后再从这个新列表中提取出链接和标题。使用get("href")方法获得链接;使用text方法获得标题。
soup.select('.atc_title')[0].select('a')[0].get("href")
>>
'http://blog.sina.com.cn/s/blog_13122c74c0102zdsy.html'soup.select('.atc_title')[0].select('a')[0].text
>>
'投资难在慢成毁于速成'发表时间的获取就简单很多了,直接用text方法即可。
soup.select('.atc_tm')[0].text
>>
'2019-09-17 21:03'如何用python爬数据,单页的信息搞定,然后就可以批量处理了。使用for循环遍历所有页,然后逐个提取。因为我们已知作者的文章共有5页,所以直接使用range(1,6)。将最终的信息存入字典all_links。其中,“标题”作为键,文章链接和发表时间作为值。通过len(all_links)查看获取的文章链接数,一共211篇文章。
#获取所有博客文章的链接
import requests
from bs4 import BeautifulSoupall_links = {}
for i in range(1,6):url = f'http://blog.sina.com.cn/s/articlelist_5119330124_0_{i}.html'wb_data = requests.get(url)soup = BeautifulSoup(wb_data.content)links = soup.select('.atc_title')times = soup.select('.atc_tm')for i in range(len(links)):http_link = links[i].select('a')[0].get('href')title = links[i].text.strip()time = times[i].textall_links[title] = [http_link, time] 
拿到所有文章链接后,先取一个来测试一下如何获取页面的文字。在文字上点右键,选择“检查”,可见其内容位于class=articalContent newfont_family里面,因此使用soup.select(".articalContent.newfont_family")就可以获取到(注意articalContent和newfont_family之间的空格要用"."代替)。将其存入article变量,显示一下,可以看到这是一个大列表,其中的文本就是我们需要的内容。下面就需要将文本单独提取出来。
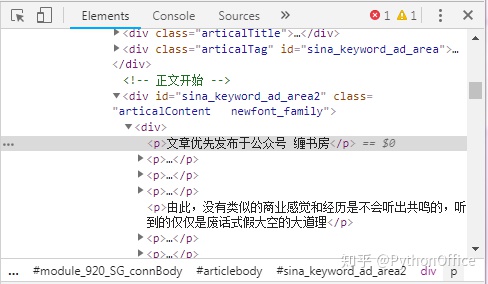
#获取单篇文章中的文字
url = 'http://blog.sina.com.cn/s/blog_13122c74c0102zbt3.html'
wb_data = requests.get(url)
soup = BeautifulSoup(wb_data.content)
article = soup.select(".articalContent.newfont_family")
article
直接使用text方法就能提取出来。“xa0”是个什么鬼?明显不是我们要的,百度了一下,说是什么不间断空格符。管他呢,直接使用replace("xa0","")删掉,这下就美丽了。“n”是换行,就不要删了,保持原格式比较好。


以上理顺,就可以大刀阔斧地开干了。定义一个函数to_word,一个参数,就是上面获取到的数据字典all_links。设定好header,假装是浏览器在访问。然后新建一个word文档,设置全局字体为宋体。因为有些文章被加密,无法访问并获取内容,所以最终获取到的文章数不一定等于链接数。于是增加一个初始值为0的计数器,用于记录写入word文档中的文章数,以便心中有数。然后遍历所有文章的标题,将标题按照“1级”写入word文档,这样才能在“导航窗格”看到文章目录,方便后续选取阅读。日期和内容都作为段落写入。有些文章被加密,获取不到内容,此时article变量为空,所以加个if语句判断,以免程序崩溃。每写入一篇文章,计数器自动加1,然后通过print输出信息。
#写入标题,内容到word文件
import docx
from docx.oxml.ns import qn #用于应用中文字体def to_word(all_links):header = {"User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0"}doc=docx.Document() #新建word文档doc.styles['Normal'].font.name=u'宋体'doc.styles['Normal']._element.rPr.rFonts.set(qn('w:eastAsia'), u'宋体')counter = 0 #计数器,用于记录写入word的文章数for title in all_links.keys():doc.add_heading(title,1)date = all_links[title][1][:10]#只取日期,不要时间doc.add_paragraph(date)wb_data = requests.get(all_links[title][0],headers = header)soup = BeautifulSoup(wb_data.content) article = soup.select(".articalContent.newfont_family")#有些文章被加密,获取不到内容,此时article为空,所以加个if语句判断if article:text = article[0].text.replace("xa0","")doc.add_paragraph(text)print(f"写入文章 {title} 。")counter += 1print(f"共写入 {counter} 篇文章。")doc.save("新浪微博文章.docx") to_word(all_links)
最后保存文件,366页,35万字的博客就到手了,结果是美丽的!从此阅读博客文章轻松多了。
版权声明:本站所有资料均为网友推荐收集整理而来,仅供学习和研究交流使用。

工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态