什么是数据库?
存储数据的仓库
数据库的存储介质:磁盘和内存。
为什么要用数据库不用文件?(数据库与文件进行数据存储的区别)
1.文件存储安全性低
2.数据库对数据进行良好的存储,查询以及管理
3.便于程序控制(C/S架构)
关系型数据库:以行和列的形式组织(OLTP)联机事务处理
Oracle:甲骨文产品,适合大型项目,适合复杂业务逻辑,如ERP、OA等,收费
MySQL:甲骨文,不适合复杂业务,开源
SQL Server:微软产品,安装部署在windows server上,适合中大型项目,收费
MariaDB:基于MySQL的开源数据库产品
Sqlite:轻量化,免费,数据量大麻烦,文件模式
非关系型数据库(OLAP联机分析处理):不规定基于SQL实现。
memcache/redis:基于键值对
mongodb:基于文档类型
为什么使用MySQL数据库?
1.采用客户端服务器模型,可以多个客户端请求数据库,数据库管理系统对数据库进行统一管理。
2.开源免费
通过MysSQL连接服务器的指令:mysql -uroot -p
断开服务器连接指令:退出:quit或者Ctrl+C
SQL分类:
DDL数据定义语言,用来维护存储数据的结构
代表指令: create, drop, alter
DML数据操纵语言,用来对数据进行操作
代表指令: insert,delete,update
DML中又单独分了一个DQL,数据查询语言,代表指令: select
DCL数据控制语言,主要负责权限管理和事务
代表指令: grant,revoke,commit
数据库:安装配置,数据库基础,基础操作,进阶操作,索引事务
数据库基础:库的操作,表的操作
注意事项:
数据库操作语句中不区分大小写
库名称、表名称、表字段名。。。不能使用关键字,若非要使用则使用‘ ’括起来
数据库操作的每条语句都要以分号;结尾
数据库语句中不区分双引号和单引号
库的操作:
1.创建数据库
CREATE DATABASE +名称(CREATE DATABASE db_name)数据库名字不能以数字起始或单独只使用数字
create database if not exists class_90;//创建数据库,若存在则不创建,若不存在则创建
2.查看所有数据库
show databases;
select database();//查看当前所选择的数据库
3.使用数据库
use db_name;
4.删除数据库
drop_database db_name;
备份:mysqldump -uroot -p -B class_90 > class_90.sql
还原:mysql -uroot -p < class_90.sql
数据类型:
整型:bit[M],tinyint,smallint,int,bigint
浮点型:float(m,d),double(m,d),decimal(m,d),numeric(m,d)
m为有效数字的个数,d为数字中小数的个数 decimal(6,3)
字符串:char(m)
varchar(m)--可变长度
text(m)--长文本数据
blob(m)--二进制长文本数据
日期:date,time,datetime(1000~9999)8字节, timestamp(1970~2038)4字节
表的操作
1.表的创建:
create table tb_name(fields_name type,...);
create table if not exists stu(id int,name varchar(32),ch decimal(4,2));
create table if not exists stu(id int,name varchar(32),sex bit(1),ch decimal(4,2),en decimal(4,2),bir datetime);
2.表的查看
查看库中所有的表show tables;
查看指定表结构 desc tb_name;
查看表的创建语句 show create table tb_name;
3.删除表
drop table tb_name;
php增删改查、表的增删改查:
新增:insert
insert into tb_name values(1,"张三",0,88.88,77.29,now());
insert into tb_name (id,name,bir)values(2,"李四",now());//单条数据新增
insert into tb_name values(3,"王五",0,23.88,77.59,now()),(4,"赵六",0,98.88,99.59,now());//多行数据新增
删除:delete
delete from tb_name;//删除表中所有数据
delete from tb_name where id=2;//删除id=2的数据
修改:update
update tb_name set id=2;//修改表中所有数据
update tb_name set id=2 where name="王五";
查询:select
select[* /fileds_name] from tb_name where condition;
select *from tb_name;//查询所有数据
select name,ch,en from tb_name;//查询指定字段的数据
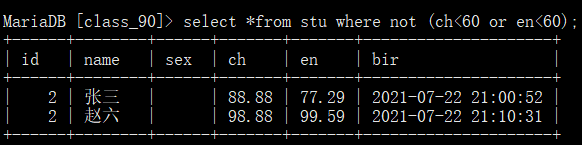
select *from tb_name where name="王五";//条件查询
select ch+en as 总成绩 from tb_name;//查询字段可以为表达式,as取别名
去重:select distinct id from tb_name;//只能显示去重的列
select distinct id,name from tb_name;//以id和name一起作为整体去重
排序:order by desc-降序 asc-升序,默认升序
select *from stu order by ch desc;//表为stu,通过ch进行stu表的排序,desc降序
select *from stu order by ch desc,en desc;//多列时第一列为第一优先排序,第一列相等则以第二列进行降序排序
分页查询:limit
limit num;--只查询前num条数据
limit num offset start;//从第start条开始查询前num条数据
select *from stu order by ch limit 3;//查询语文成绩前三的同学信息
select *from stu limit 2 offset 0;//从第0条开始查询2条数据
select *from stu limit num offset (n-1)*num; //分页查询
条件查询:where 子条件,没有where都是针对所有数据
关系运算符: >,>=,<,<= 大小判断
=,<=>是否相等判断
!=,<>是否不相等判断
is NULL/is not NULL 判断字段是否为NULL
in(d1,d2,d3) 判断字段是否是集合中的某一个
between start and end 判断字段数据是否在start和end之间
like 模糊匹配,例如:select *from stu where name like "王%";
子条件 where
逻辑运算符:
数据库主表和相关表如何建立关系, 逻辑与:and,两个条件都为真则结果为真
逻辑或:or,两个条件任意一个为真则结果为真
逻辑非:not,单个条件为真,则结果为假
增删改查进阶:表的约束,分组查询,数据库表的设计,多表联查。
表的约束:对表中某个字段值的约束
NOT NULL:约束字段的值不能为NULL

UNIQUE:约束表的字段的值必须唯一,唯一键约束

PRIMARY KEY:主键,约束字段必须非空且唯一(且一张表只能有一个主键)
create table if not exists tbt(id int ,primary key,name varchar(32));
create table if not exists tbt(id int, name varchar(32),primary key pkey(id,name)); 以id和name作为一个整体,组合主键。
DEFAULT:默认值约束,当不插入数据或者插入NULL则表示插入默认数据
create table if not exists tbt( id int, name varchar(32) NOT NULL);
AUTO_INCREMENT: 自动增长属性--只能对整形字段进行设置 (只针对主键--扩展属性
create table if not exists tbt( id int unique auto_increment, name varchar(32) );
FOREIGN KEY: 外键约束,约束字段匹配另一张表中的值。
create table if not exists tb_class( id int primary key, name varchar(32) not null unique);//子表
create table if not exists tb_stu( id int primary key, name varchar(32),class_id int,foreign key(class_id) references tb_class(id));//父表
子表对应外键的字段必须是父表中对应字段所存在的数据
CHECK字句:--检测数值是否符合条件
聚合查询:
聚合函数:
count(): 统计数据条数 实例:select max(ch) from stu;
sum(fields_name):某一列字段数据的综合
avg(fields_name):某一列字段数据平均数值
max(fields_name):某一列字段数据最大数值
min(fields_name):某一列字段数据最小数值
分组查询:按照表中某一字段作为依据对数据进行分组
group by column having condition;
分组查询中,通常是对分组的数据进行统计运算。
select role from emp group by role having avg(salary)>1500;
//其中emp是表,按照表中role进行统计salary的平均avg大于1500的有谁。
数据库表的设计:
三大范式:如何让数据库表设计的更加合理的一种规范
第一范式-1nf:保证表中每个字段具有不可分割原子性。

第二范式:表中数据必须与主键完全相关(不能部分相关,减少数据冗余)

将此表分成2部分进行设计:


第三范式:表中字段必须与主键直接相关,不能间接相关

班主任与学号是间接相关,产生数据冗余信息,

ER关系图--实体关系图
方形表示一个实体,圆形表示一个属性,菱形表示一个关系。
一对一:

在数据库表中,理解为,其中任意一方将对方的id作为自己的一个字段,则可以将两张表联系起来。
多对多:

多表联查:

笛卡尔积:

多表连接方式:内连接,外连接(左连接,右连接)




内连接:取交集,学生表,班级表--得出一一对应关系的
select 字段 from 表1 inner join 表2 on 连接条件 and 其他条件
右连接:以右表作为一个主表,在左表中查询数据,若查询不到则以NULL显示
学生表join班级表on学生表的班级id=班级表的id
select 字段 from 表名1 right join 表名2 on 连接条件;
左连接:与右连接相反
select 字段名 from 表名1 left join 表名2 on 连接条件
版权声明:本站所有资料均为网友推荐收集整理而来,仅供学习和研究交流使用。

工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态







![[Wayland] (二) 代码结构 [FW]](https://images2015.cnblogs.com/blog/753004/201607/753004-20160720100837341-320217114.png)


![BZOJ 3450: Tyvj1952 Easy [DP 概率]](/upload/rand_pic/2-1512.jpg)