這個教程將利用機器學習的手段來對鳶尾花按照物種進行分類。本教程將利用 TensorFlow 來進行以下操作:
- 構建一個模型,
- 用樣例數據集對模型進行訓練,以及
- 利用該模型對未知數據進行預測。
TensorFlow 編程
本指南采用了以下高級 TensorFlow 概念:
- 使用 TensorFlow 默認的???eager execution???開發環境,
- 使用???Datasets API???導入數據,
- 使用 TensorFlow 的???Keras API???來構建各層以及整個模型。
本教程的結構同很多 TensorFlow 程序相似:
- 數據集的導入與解析
- 選擇模型類型
- 對模型進行訓練
- 評估模型效果
- 使用訓練過的模型進行預測
環境的搭建
配置導入
導入 TensorFlow 以及其他需要的 Python 庫。 默認情況下,TensorFlow 用???eager execution???來實時評估操作, 返回具體值而不是建立一個稍后執行的??計算圖??。 如果您習慣使用 REPL 或 python 交互控制臺, 對此您會感覺得心應手。
import os
import matplotlib.pyplot as plt
import tensorflow as tf
print("TensorFlow version: {}".format(tf.__version__))
print("Eager execution: {}".format(tf.executing_eagerly()))
TensorFlow version: 2.6.0
Eager execution: True
鳶尾花分類問題
想象一下,您是一名植物學家,正在尋找一種能夠對所發現的每株鳶尾花進行自動歸類的方法。機器學習可提供多種從統計學上分類花卉的算法。例如,一個復雜的機器學習程序可以根據照片對花卉進行分類。我們的要求并不高 - 我們將根據鳶尾花花萼和花瓣的長度和寬度對其進行分類。
tensorflow菜鳥教程。鳶尾屬約有 300 個品種,但我們的程序將僅對下列三個品種進行分類:
- 山鳶尾
- 維吉尼亞鳶尾
- 變色鳶尾
|
Figure 1.???山鳶尾???(by???Radomil??, CC BY-SA 3.0),???變色鳶尾??, (by???Dlanglois??, CC BY-SA 3.0), and???維吉尼亞鳶尾???(by???Frank Mayfield??, CC BY-SA 2.0). {nbsp} |

幸運的是,有人已經創建了一個包含有花萼和花瓣的測量值的??120 株鳶尾花的數據集??。這是一個在入門級機器學習分類問題中經常使用的經典數據集。
導入和解析訓練數據集
下載數據集文件并將其轉換為可供此 Python 程序使用的結構。
下載數據集
keep自定義訓練、使用???tf.keras.utils.get_file???函數下載訓練數據集文件。該函數會返回下載文件的文件路徑:
train_dataset_url = "https://storage.googleapis.com/download.tensorflow.org/data/iris_training.csv"
train_dataset_fp = tf.keras.utils.get_file(fname=os.path.basename(train_dataset_url),
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?origin=train_dataset_url)
print("Local copy of the dataset file: {}".format(train_dataset_fp))
Downloading data from https://storage.googleapis.com/download.tensorflow.org/data/iris_training.csv
16384/2194 [================================================================================================================================================================================================================================] - 0s 0us/step
Local copy of the dataset file: /home/kbuilder/.keras/datasets/iris_training.csv
檢查數據
數據集???iris_training.csv???是一個純文本文件,其中存儲了逗號分隔值 (CSV) 格式的表格式數據.請使用???head -n5???命令查看前 5 個條目:
head -n5 {train_dataset_fp}
120,4,setosa,versicolor,virginica
6.4,2.8,5.6,2.2,2
5.0,2.3,3.3,1.0,1
4.9,2.5,4.5,1.7,2
4.9,3.1,1.5,0.1,0
我們可以從該數據集視圖中注意到以下信息:
- 第一行是表頭,其中包含數據集信息:
- 共有 120 個樣本。每個樣本都有四個特征和一個標簽名稱,標簽名稱有三種可能。
- 后面的行是數據記錄,每個??樣本??各占一行,其中:
- 前四個字段是??特征??: 這四個字段代表的是樣本的特點。在此數據集中,這些字段存儲的是代表花卉測量值的浮點數。
- 最后一列是??標簽??:即我們想要預測的值。對于此數據集,該值為 0、1 或 2 中的某個整數值(每個值分別對應一個花卉名稱)。
我們用代碼表示出來:
# column order in CSV file
column_names = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width', 'species']
feature_names = column_names[:-1]
label_name = column_names[-1]
print("Features: {}".format(feature_names))
print("Label: {}".format(label_name))
Features: ['sepal_length', 'sepal_width', 'petal_length', 'petal_width']
Label: species
每個標簽都分別與一個字符串名稱(例如 “setosa” )相關聯,但機器學習通常依賴于數字值。標簽編號會映射到一個指定的表示法,例如:
- ?
?0???: 山鳶尾 - ?
?1???: 變色鳶尾 - ?
?2???: 維吉尼亞鳶尾
如需詳細了解特征和標簽,請參閱???《機器學習速成課程》的“機器學習術語”部分??.
class_names = ['Iris setosa', 'Iris versicolor', 'Iris virginica']
創建一個???tf.data.Dataset??
印象筆記如何創建自己的模板,TensorFlow的???Dataset API???可處理在向模型加載數據時遇到的許多常見情況。這是一種高階 API ,用于讀取數據并將其轉換為可供訓練使用的格式。如需了解詳情,請參閱??數據集快速入門指南??
由于數據集是 CSV 格式的文本文件,請使用???make_csv_dataset???函數將數據解析為合適的格式。由于此函數為訓練模型生成數據,默認行為是對數據進行隨機處理 (??shuffle=True, shuffle_buffer_size=10000???),并且無限期重復數據集(??num_epochs=None??)。 我們還設置了???batch_size???參數:
batch_size = 32
train_dataset = tf.data.experimental.make_csv_dataset(
? ? train_dataset_fp,
? ? batch_size,
? ? column_names=column_names,
? ? label_name=label_name,
? ? num_epochs=1)
??make_csv_dataset???返回一個??(features, label)???對構建的???tf.data.Dataset???,其中???features???是一個字典:???{'feature_name': value}??
這些???Dataset???對象是可迭代的。 我們來看看下面的一些特征:
features, labels = next(iter(train_dataset))
print(features)
OrderedDict([('sepal_length', <tf.Tensor: shape=(32,), dtype=float32, numpy=
array([6.4, 6.5, 5.4, 5.8, 5.7, 6.4, 7. , 7.7, 6.2, 6.5, 7.3, 4.8, 7.4,
4.9, 4.9, 4.4, 5.6, 5. , 6.1, 6.7, 4.6, 6.8, 6.3, 5.1, 5.8, 5. ,
5.7, 7.2, 5.7, 5.7, 5. , 5.2], dtype=float32)>), ('sepal_width', <tf.Tensor: shape=(32,), dtype=float32, numpy=
array([2.7, 3. , 3.7, 4. , 3. , 3.2, 3.2, 3. , 2.2, 2.8, 2.9, 3.1, 2.8,
3.1, 3. , 2.9, 2.9, 2. , 2.8, 3. , 3.4, 3.2, 3.3, 3.5, 2.8, 3.2,
4.4, 3.6, 2.8, 2.9, 3. , 2.7], dtype=float32)>), ('petal_length', <tf.Tensor: shape=(32,), dtype=float32, numpy=
array([5.3, 5.8, 1.5, 1.2, 4.2, 5.3, 4.7, 6.1, 4.5, 4.6, 6.3, 1.6, 6.1,
1.5, 1.4, 1.4, 3.6, 3.5, 4.7, 5.2, 1.4, 5.9, 4.7, 1.4, 5.1, 1.2,
1.5, 6.1, 4.5, 4.2, 1.6, 3.9], dtype=float32)>), ('petal_width', <tf.Tensor: shape=(32,), dtype=float32, numpy=
array([1.9, 2.2, 0.2, 0.2, 1.2, 2.3, 1.4, 2.3, 1.5, 1.5, 1.8, 0.2, 1.9,
0.1, 0.2, 0.2, 1.3, 1. , 1.2, 2.3, 0.3, 2.3, 1.6, 0.3, 2.4, 0.2,
0.4, 2.5, 1.3, 1.3, 0.2, 1.4], dtype=float32)>)])
注意到具有相似特征的樣本會歸為一組,即分為一批。更改???batch_size???可以設置存儲在這些特征數組中的樣本數。
繪制該批次中的幾個特征后,就會開始看到一些集群現象:
plt.scatter(features['petal_length'],
? ? ? ? ? ? features['sepal_length'],
? ? ? ? ? ? c=labels,
? ? ? ? ? ? cmap='viridis')
plt.xlabel("Petal length")
plt.ylabel("Sepal length")
plt.show()
印象筆記標簽分類模板、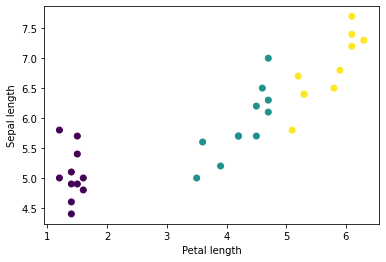
要簡化模型構建步驟,請創建一個函數以將特征字典重新打包為形狀為???(batch_size, num_features)???的單個數組。
此函數使用???tf.stack???方法,該方法從張量列表中獲取值,并創建指定維度的組合張量:
def pack_features_vector(features, labels):
? """Pack the features into a single array."""
? features = tf.stack(list(features.values()), axis=1)
? return features, labels
然后使用???tf.data.Dataset.map???方法將每個???(features,label)???對中的???features???打包到訓練數據集中:
train_dataset = train_dataset.map(pack_features_vector)
??Dataset???的特征元素被構成了形如???(batch_size, num_features)???的數組。我們來看看前幾個樣本:
features, labels = next(iter(train_dataset))
print(features[:5])
tf.Tensor(
[[6.3 3.3 6. 2.5]
[4.6 3.4 1.4 0.3]
[5.8 2.8 5.1 2.4]
[6.8 2.8 4.8 1.4]
[5.2 3.4 1.4 0.2]], shape=(5, 4), dtype=float32)
選擇模型類型
為何要使用模型?
??模型??是指特征與標簽之間的關系。對于鳶尾花分類問題,模型定義了花萼和花瓣測量值與預測的鳶尾花品種之間的關系。一些簡單的模型可以用幾行代數進行描述,但復雜的機器學習模型擁有大量難以匯總的參數。
自定義健身計劃,您能否在不使用機器學習的情況下確定四個特征與鳶尾花品種之間的關系?也就是說,您能否使用傳統編程技巧(例如大量條件語句)創建模型?也許能,前提是反復分析該數據集,并最終確定花瓣和花萼測量值與特定品種的關系。對于更復雜的數據集來說,這會變得非常困難,或許根本就做不到。一個好的機器學習方法可為您確定模型。如果您將足夠多的代表性樣本饋送到正確類型的機器學習模型中,該程序便會為您找出相應的關系。
選擇模型
我們需要選擇要進行訓練的模型類型。模型具有許多類型,挑選合適的類型需要一定的經驗。本教程使用神經網絡來解決鳶尾花分類問題。??神經網絡???可以發現特征與標簽之間的復雜關系。神經網絡是一個高度結構化的圖,其中包含一個或多個??隱含層???。每個隱含層都包含一個或多個??神經元???。 神經網絡有多種類別,該程序使用的是密集型神經網絡,也稱為??全連接神經網絡???: 一個層中的神經元將從上一層中的每個神經元獲取輸入連接。例如,圖 2 顯示了一個密集型神經網絡,其中包含 1 個輸入層、2 個隱藏層以及 1 個輸出層:
|
圖 2.?包含特征、隱藏層和預測的神經網絡 {nbsp} |
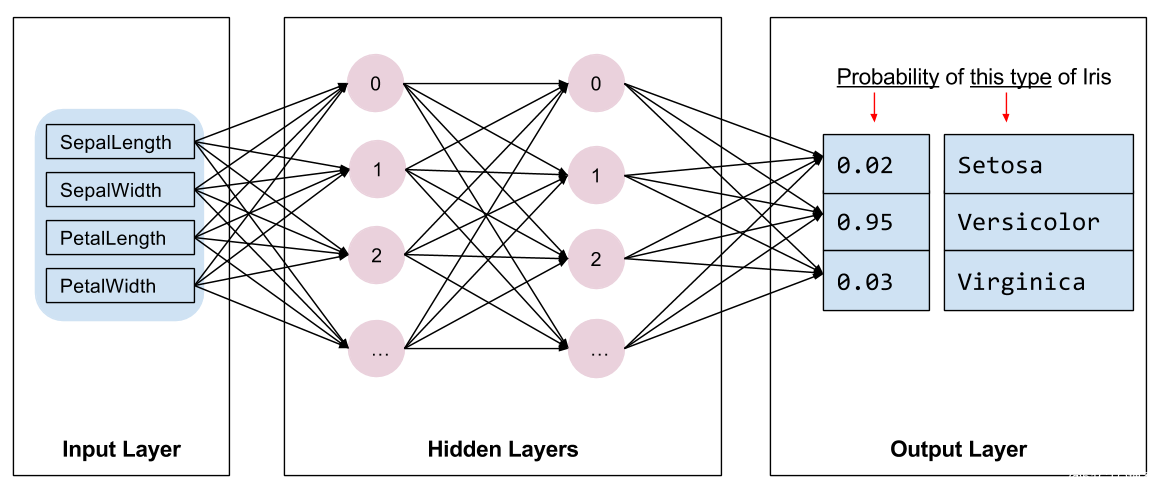
當圖 2 中的模型經過訓練并獲得無標簽樣本后,它會產生 3 個預測結果:相應鳶尾花屬于指定品種的可能性。這種預測稱為??推理??。對于該示例,輸出預測結果的總和是 1.0。在圖 2 中,該預測結果分解如下:山鳶尾為 0.02,變色鳶尾為 0.95,維吉尼亞鳶尾為 0.03。這意味著該模型預測某個無標簽鳶尾花樣本是變色鳶尾的概率為 95%。
使用 Keras 創建模型
筆記范本,TensorFlow???tf.keras???API 是創建模型和層的首選方式。通過該 API,您可以輕松地構建模型并進行實驗,而將所有部分連接在一起的復雜工作則由 Keras 處理。
??tf.keras.Sequential???模型是層的線性堆疊。該模型的構造函數會采用一系列層實例;在本示例中,采用的是 2 個??密集層??(各自包含10個節點),以及 1 個輸出層(包含 3 個代表標簽預測的節點。第一個層的???input_shape???參數對應該數據集中的特征數量,它是一項必需參數:
model = tf.keras.Sequential([
? tf.keras.layers.Dense(10, activation=tf.nn.relu, input_shape=(4,)), ?# input shape required
? tf.keras.layers.Dense(10, activation=tf.nn.relu),
? tf.keras.layers.Dense(3)
])
??激活函數???可決定層中每個節點的輸出形式。 這些非線性關系很重要,如果沒有它們,模型將等同于單個層。??激活函數??有很多種,但隱藏層通常使用???ReLU??。
隱藏層和神經元的理想數量取決于問題和數據集。與機器學習的多個方面一樣,選擇最佳的神經網絡形狀需要一定的知識水平和實驗基礎。一般來說,增加隱藏層和神經元的數量通常會產生更強大的模型,而這需要更多數據才能有效地進行訓練。
使用模型
我們快速了解一下此模型如何處理一批特征:
predictions = model(features)
predictions[:5]
<tf.Tensor: shape=(5, 3), dtype=float32, numpy=
array([[-4.0646663, -2.4679987, -3.2957547],
[-2.665149 , -1.5487775, -2.1048567],
[-3.6250556, -2.2275388, -3.0203269],
[-3.918368 , -2.351877 , -3.4466283],
[-2.902191 , -1.6912566, -2.3519876]], dtype=float32)>
在此示例中,每個樣本針對每個類別返回一個???logit??。
為知筆記添加筆記方法。要將這些對數轉換為每個類別的概率,請使用???softmax???函數:
tf.nn.softmax(predictions[:5])
<tf.Tensor: shape=(5, 3), dtype=float32, numpy=
array([[0.12354876, 0.6099051 , 0.26654616],
[0.17226714, 0.52606136, 0.30167148],
[0.14543554, 0.5883075 , 0.26625693],
[0.13527055, 0.6479204 , 0.21680896],
[0.16419756, 0.55114865, 0.28465378]], dtype=float32)>
對每個類別執行???tf.argmax???運算可得出預測的類別索引。不過,該模型尚未接受訓練,因此這些預測并不理想。
print("Prediction: {}".format(tf.argmax(predictions, axis=1)))
print(" ? ?Labels: {}".format(labels))
Prediction: [1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1]
Labels: [2 0 2 1 0 1 0 0 0 0 1 2 1 2 2 0 1 0 1 2 0 2 0 2 1 0 2 2 0 2 1 2]
訓練模型
??訓練???是一個機器學習階段,在此階段中,模型會逐漸得到優化,也就是說,模型會了解數據集。目標是充分了解訓練數據集的結構,以便對未見過的數據進行預測。如果您從訓練數據集中獲得了過多的信息,預測便會僅適用于模型見過的數據,但是無法泛化。此問題被稱之為??過擬合??—就好比將答案死記硬背下來,而不去理解問題的解決方式。
鳶尾花分類問題是??監督式機器學習???的一個示例: 模型通過包含標簽的樣本加以訓練。 而在??非監督式機器學習??中,樣本不包含標簽。相反,模型通常會在特征中發現一些規律。
定義損失和梯度函數
在訓練和評估階段,我們都需要計算模型的??損失??。 這樣可以衡量模型的預測結果與預期標簽有多大偏差,也就是說,模型的效果有多差。我們希望盡可能減小或優化這個值。
我們的模型會使用???tf.keras.losses.SparseCategoricalCrossentropy???函數計算其損失,此函數會接受模型的類別概率預測結果和預期標簽,然后返回樣本的平均損失。
loss_object = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
def loss(model, x, y, training):
? # training=training is needed only if there are layers with different
? # behavior during training versus inference (e.g. Dropout).
? y_ = model(x, training=training)
? return loss_object(y_true=y, y_pred=y_)
l = loss(model, features, labels, training=False)
print("Loss test: {}".format(l))
Loss test: 1.3196566104888916
編輯筆記,使用???tf.GradientTape???的前后關系來計算??梯度??以優化你的模型:
def grad(model, inputs, targets):
? with tf.GradientTape() as tape:
? ? loss_value = loss(model, inputs, targets, training=True)
? return loss_value, tape.gradient(loss_value, model.trainable_variables)
創建優化器
??優化器???會將計算出的梯度應用于模型的變量,以使???loss???函數最小化。您可以將損失函數想象為一個曲面(見圖 3),我們希望通過到處走動找到該曲面的最低點。梯度指向最高速上升的方向,因此我們將沿相反的方向向下移動。我們以迭代方式計算每個批次的損失和梯度,以在訓練過程中調整模型。模型會逐漸找到權重和偏差的最佳組合,從而將損失降至最低。損失越低,模型的預測效果就越好。
|
圖 3.?優化算法在三維空間中隨時間推移而變化的可視化效果。 (來源:???斯坦福大學 CS231n 課程??,MIT 許可證,Image credit:???Alec Radford??) |
TensorFlow有許多可用于訓練的??優化算法??。此模型使用的是???tf.train.GradientDescentOptimizer???, 它可以實現??隨機梯度下降法???(SGD)。??learning_rate???被用于設置每次迭代(向下行走)的步長。 這是一個?超參數?,您通常需要調整此參數以獲得更好的結果。
筆記。我們來設置優化器:
optimizer = tf.keras.optimizers.SGD(learning_rate=0.01)
我們將使用它來計算單個優化步驟:
loss_value, grads = grad(model, features, labels)
print("Step: {}, Initial Loss: {}".format(optimizer.iterations.numpy(),
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? loss_value.numpy()))
optimizer.apply_gradients(zip(grads, model.trainable_variables))
print("Step: {}, ? ? ? ? Loss: {}".format(optimizer.iterations.numpy(),
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? loss(model, features, labels, training=True).numpy()))
Step: 0, Initial Loss: 1.3196566104888916
Step: 1, Loss: 1.2388347387313843
訓練循環
一切準備就緒后,就可以開始訓練模型了!訓練循環會將數據集樣本饋送到模型中,以幫助模型做出更好的預測。以下代碼塊可設置這些訓練步驟:
- 迭代每個周期。通過一次數據集即為一個周期。
- 在一個周期中,遍歷訓練??
?Dataset???中的每個樣本,并獲取樣本的特征(??x??)和標簽(??y??)。 - 根據樣本的特征進行預測,并比較預測結果和標簽。衡量預測結果的不準確性,并使用所得的值計算模型的損失和梯度。
- 使用??
?optimizer???更新模型的變量。 - 跟蹤一些統計信息以進行可視化。
- 對每個周期重復執行以上步驟。
??num_epochs???變量是遍歷數據集集合的次數。與直覺恰恰相反的是,訓練模型的時間越長,并不能保證模型就越好。??num_epochs???是一個可以調整的??超參數??。選擇正確的次數通常需要一定的經驗和實驗基礎。
## Note: Rerunning this cell uses the same model variables
# Keep results for plotting
train_loss_results = []
train_accuracy_results = []
num_epochs = 201
for epoch in range(num_epochs):
? epoch_loss_avg = tf.keras.metrics.Mean()
? epoch_accuracy = tf.keras.metrics.SparseCategoricalAccuracy()
? # Training loop - using batches of 32
? for x, y in train_dataset:
? ? # Optimize the model
? ? loss_value, grads = grad(model, x, y)
? ? optimizer.apply_gradients(zip(grads, model.trainable_variables))
? ? # Track progress
? ? epoch_loss_avg.update_state(loss_value) ?# Add current batch loss
? ? # Compare predicted label to actual label
? ? # training=True is needed only if there are layers with different
? ? # behavior during training versus inference (e.g. Dropout).
? ? epoch_accuracy.update_state(y, model(x, training=True))
? # End epoch
? train_loss_results.append(epoch_loss_avg.result())
? train_accuracy_results.append(epoch_accuracy.result())
? if epoch % 50 == 0:
? ? print("Epoch {:03d}: Loss: {:.3f}, Accuracy: {:.3%}".format(epoch,
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? epoch_loss_avg.result(),
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? epoch_accuracy.result()))
Epoch 000: Loss: 1.175, Accuracy: 31.667%
Epoch 050: Loss: 0.842, Accuracy: 68.333%
Epoch 100: Loss: 0.402, Accuracy: 95.000%
Epoch 150: Loss: 0.239, Accuracy: 97.500%
Epoch 200: Loss: 0.166, Accuracy: 97.500%
可視化損失函數隨時間推移而變化的情況
雖然輸出模型的訓練過程有幫助,但查看這一過程往往更有幫助。???TensorBoard???是與 TensorFlow 封裝在一起的出色可視化工具,不過我們可以使用???matplotlib???模塊創建基本圖表。
解讀這些圖表需要一定的經驗,不過您確實希望看到損失下降且準確率上升。
fig, axes = plt.subplots(2, sharex=True, figsize=(12, 8))
fig.suptitle('Training Metrics')
axes[0].set_ylabel("Loss", fontsize=14)
axes[0].plot(train_loss_results)
axes[1].set_ylabel("Accuracy", fontsize=14)
axes[1].set_xlabel("Epoch", fontsize=14)
axes[1].plot(train_accuracy_results)
plt.show()
tensorflow模型訓練?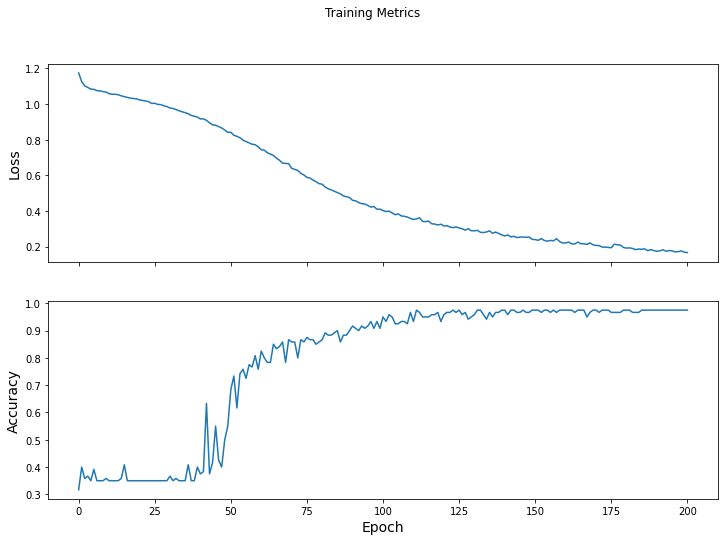
評估模型的效果
模型已經過訓練,現在我們可以獲取一些關于其效果的統計信息了。
評估?指的是確定模型做出預測的效果。要確定模型在鳶尾花分類方面的效果,請將一些花萼和花瓣測量值傳遞給模型,并要求模型預測它們所代表的鳶尾花品種。然后,將模型的預測結果與實際標簽進行比較。例如,如果模型對一半輸入樣本的品種預測正確,則???準確率???為???0.5???。 圖 4 顯示的是一個效果更好一些的模型,該模型做出 5 次預測,其中有 4 次正確,準確率為 80%:
樣本特征 | 標簽 | 模型預測 | |||
印象筆記自定義模板?5.9 | 3.0 | 4.3 | 1.5 | 1 | 1 |
tensorflow訓練自己的數據集、6.9 | 3.1 | 5.4 | 2.1 | 2 | 2 |
自定義訓練計劃的軟件?5.1 | 3.3 | 1.7 | 0.5 | 0 | 0 |
印象筆記如何修改模板。6.0 | 3.4 | 4.5 | 1.6 | 1 | 2 |
keep怎么自定義訓練。5.5 | 2.5 | 4.0 | 1.3 | 1 | 1 |
圖 4.?準確率為 80% 的鳶尾花分類器 {nbsp} | |||||
建立測試數據集
評估模型與訓練模型相似。最大的區別在于,樣本來自一個單獨的??測試集??,而不是訓練集。為了公正地評估模型的效果,用于評估模型的樣本務必與用于訓練模型的樣本不同。
測試???Dataset???的建立與訓練???Dataset???相似。下載 CSV 文本文件并解析相應的值,然后對數據稍加隨機化處理:
test_url = "https://storage.googleapis.com/download.tensorflow.org/data/iris_test.csv"
test_fp = tf.keras.utils.get_file(fname=os.path.basename(test_url),
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? origin=test_url)
Downloading data from https://storage.googleapis.com/download.tensorflow.org/data/iris_test.csv
16384/573 [=========================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================] - 0s 0us/step
test_dataset = tf.data.experimental.make_csv_dataset(
? ? test_fp,
? ? batch_size,
? ? column_names=column_names,
? ? label_name='species',
? ? num_epochs=1,
? ? shuffle=False)
test_dataset = test_dataset.map(pack_features_vector)
根據測試數據集評估模型
與訓練階段不同,模型僅評估測試數據的一個??周期??。在以下代碼單元格中,我們會遍歷測試集中的每個樣本,然后將模型的預測結果與實際標簽進行比較。這是為了衡量模型在整個測試集中的準確率。
test_accuracy = tf.keras.metrics.Accuracy()
for (x, y) in test_dataset:
? # training=False is needed only if there are layers with different
? # behavior during training versus inference (e.g. Dropout).
? logits = model(x, training=False)
? prediction = tf.argmax(logits, axis=1, output_type=tf.int32)
? test_accuracy(prediction, y)
print("Test set accuracy: {:.3%}".format(test_accuracy.result()))
Test set accuracy: 96.667%
例如,我們可以看到對于最后一批數據,該模型通常預測正確:
tf.stack([y,prediction],axis=1)
<tf.Tensor: shape=(30, 2), dtype=int32, numpy=
array([[1, 1],
[2, 2],
[0, 0],
[1, 1],
[1, 1],
[1, 1],
[0, 0],
[2, 2],
[1, 1],
[2, 2],
[2, 2],
[0, 0],
[2, 2],
[1, 1],
[1, 1],
[0, 0],
[1, 1],
[0, 0],
[0, 0],
[2, 2],
[0, 0],
[1, 2],
[2, 2],
[1, 1],
[1, 1],
[1, 1],
[0, 0],
[1, 1],
[2, 2],
[1, 1]], dtype=int32)>
使用經過訓練的模型進行預測
我們已經訓練了一個模型并“證明”它是有效的,但在對鳶尾花品種進行分類方面,這還不夠。現在,我們使用經過訓練的模型對???無標簽樣本??(即包含特征但不包含標簽的樣本)進行一些預測。
在現實生活中,無標簽樣本可能來自很多不同的來源,包括應用、CSV 文件和數據 Feed。暫時我們將手動提供三個無標簽樣本以預測其標簽。回想一下,標簽編號會映射到一個指定的表示法:
- ?
?0??: 山鳶尾 - ?
?1??: 變色鳶尾 - ?
?2??: 維吉尼亞鳶尾
predict_dataset = tf.convert_to_tensor([
? ? [5.1, 3.3, 1.7, 0.5,],
? ? [5.9, 3.0, 4.2, 1.5,],
? ? [6.9, 3.1, 5.4, 2.1]
])
# training=False is needed only if there are layers with different
# behavior during training versus inference (e.g. Dropout).
predictions = model(predict_dataset, training=False)
for i, logits in enumerate(predictions):
? class_idx = tf.argmax(logits).numpy()
? p = tf.nn.softmax(logits)[class_idx]
? name = class_names[class_idx]
? print("Example {} prediction: {} ({:4.1f}%)".format(i, name, 100*p))
Example 0 prediction: Iris setosa (95.2%)
Example 1 prediction: Iris versicolor (79.8%)
Example 2 prediction: Iris virginica (72.1%)
![[转]Oracle修改监听口令](/upload/rand_pic/2-1377.jpg)