作者:vinyyu
聲明:版權所有,轉載請注明出處,謝謝。
time庫用于每次獲取頁面的時間間隔;pandas庫用于DataFrame的數據格式存儲;requests用于爬蟲獲取頁面Html信息;BeautifulSoup用于去掉網頁格式提取相關信息;lxml用于操作excel文件。
BeautifulSoup 目前已經被移植到 bs4 庫中,也就是說在導入 BeautifulSoup 時需要先安裝的是 bs4 庫。
import time
import pandas as pd
import requests
from bs4 import BeautifulSoup
import lxml零基礎學python爬蟲、網頁請求的過程分為兩個環節:

對于網頁請求的方式,也分為兩種:
例如,需要獲得網易體育的頁面內容,編寫最簡單代碼:
url='http://sports.163.com'
html = requests.get(url)
print(html.text)一個簡單的爬蟲實例、獲得結果如下:

可以看到,這里獲得的是這個url的整個網頁內容。然后我們需要通過所需內容的選擇器(selector)和BeautifulSoup解析獲得該網頁中我們需要的部分內容。
*本文默認讀者已知網頁結構。網頁一般由三部分組成,分別是 HTML(超文本標記語言)、CSS(層疊樣式表)和JScript(活動腳本語言)。
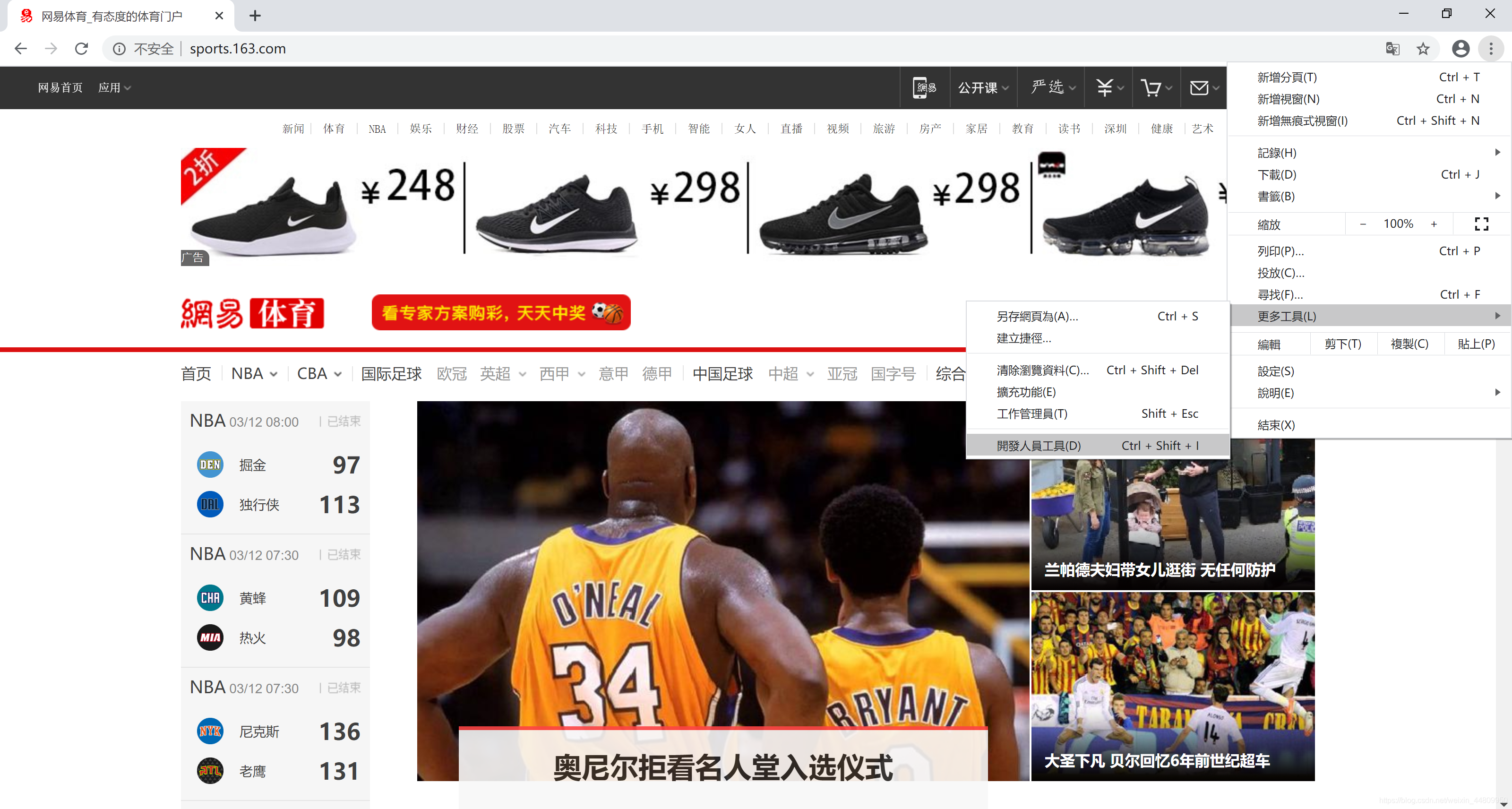
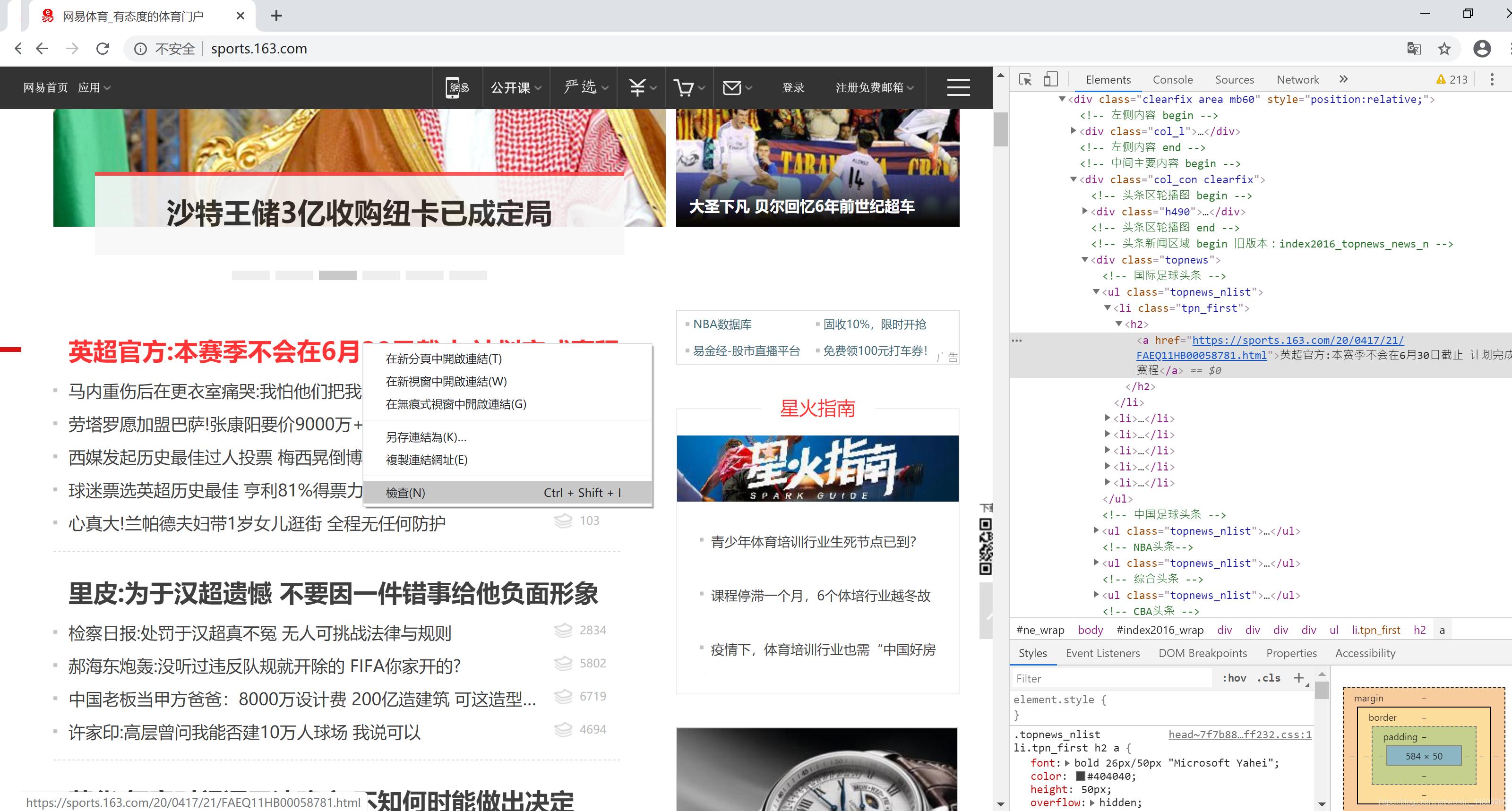
推薦用Chrome瀏覽器打開網頁。點擊右上角“自定及管理”按鈕,選擇“更多工具”菜單,選擇“開發人員工具”子菜單,打開網頁開發平臺。然后在一個網頁的所需信息上,右鍵點擊鼠標,彈出浮動菜單選擇“檢查”。在開發平臺上選中的所需信息位置上,右鍵點擊鼠標,彈出浮動菜單選擇“Copy”,然后選擇“copy selector”,復制所需頁面的選擇器。整個操作過程如下所示:
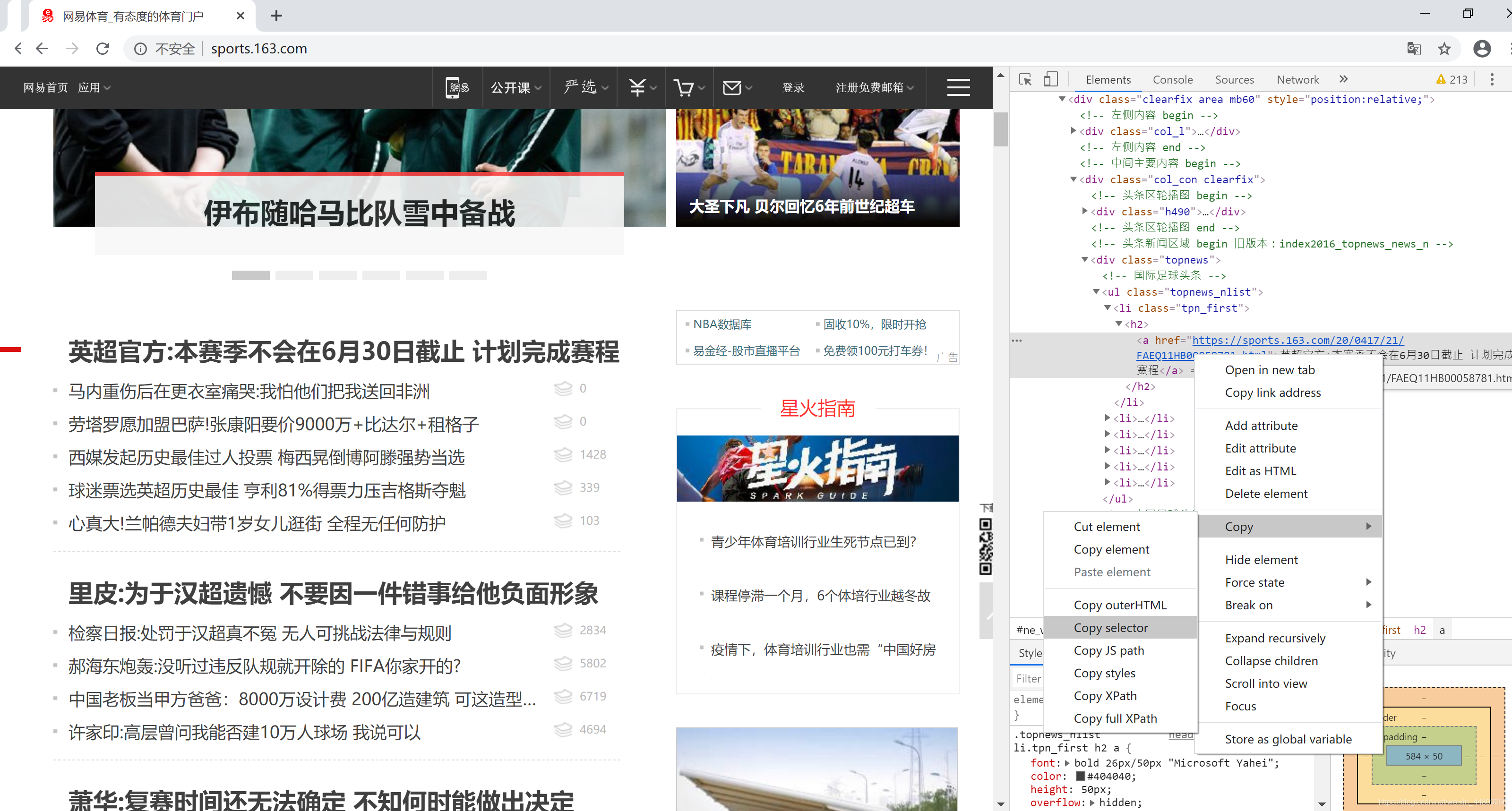
下面代碼第一句是用BeautifulSoup解析在2.1中通過requests.get()獲得的html.txt。第二句是用BeautifulSoup的select()函數,參數是2.2中獲得的選擇器(selector),提取網頁中我們需要的內容放到data變量中。for循環用于讀取data中的內容并顯示結果。
要明確BeautifulSoup的select()函數獲得的data數據格式。提取的數據包含標題和鏈接,標題在<a>標簽中,提取標簽的正文用get_text() 方法。鏈接在<a>標簽的 href 屬性中,提取標簽中的 href 屬性用 get() 方法,在括號中指定要提取的屬性數據,即 get(‘href’)。
soup=BeautifulSoup(html.text,'lxml')
data=soup.select('#index2016_wrap > div.index2016_content > div.clearfix.area.mb60 > div.col_con.clearfix > div.topnews > ul:nth-child(1) > li.tpn_first > h2 > a')
for item in data:result={'title':item.get_text(),'link':item.get('href')}print(result)結果顯示為:
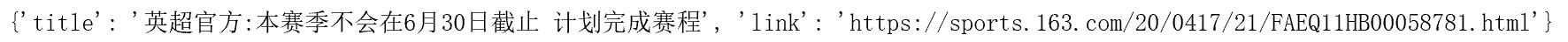 如果我們需要獲取所有的頭條新聞,因此將 ul:nth-child(1)…中冒號(包含冒號)后面的部分刪掉。并根據結果顯示,可以采用字符串替換函數.replace("\n", " ")等清洗獲得的數據。形成新的代碼如下:
如果我們需要獲取所有的頭條新聞,因此將 ul:nth-child(1)…中冒號(包含冒號)后面的部分刪掉。并根據結果顯示,可以采用字符串替換函數.replace("\n", " ")等清洗獲得的數據。形成新的代碼如下:
soup=BeautifulSoup(html.text,'lxml')
data=soup.select('#index2016_wrap > div.index2016_content > div.clearfix.area.mb60 > div.col_con.clearfix > div.topnews > ul')
for item in data:result={'title':item.get_text().replace('\n', ' '),'link':item.get('href')}print(result)則所有結果顯示為:

上面的程序只是用print語句看了一下結果,下面用pandas的DataFrame把數據保存起來
df_data=pd.DataFrame()
data=soup.select('#index2016_wrap > div.index2016_content > div.clearfix.area.mb60 > div.col_con.clearfix > div.topnews > ul')
for item in data:result={'title':item.get_text().replace('\n', ' '), 'link':item.get('href')}new=pd.DataFrame(result, index=[1])df_data=df_data.append(new,ignore_index=True)
df_data
df_data.to_excel("D:/result.xlsx", encoding='utf-8', index=False, header=True)下圖可以看到我們將整個結果保存到DataFrame數據框中,當然,也可以再對文本中“跟貼”的數量做字符串的處理提取等操作。最后,用lxml庫中的to_excel()將結果保存到excel文件中。

例如有道翻譯網站http://www.youdao.com,可以查詢中文詞語對應的英文表達。比如我們有一組詞語“秋風送爽、琵琶行、篳路藍縷、確實、過猶不及、海闊天空”,需要查詢它們的意思,可以看到有道網站對應的網址為:
http://www.youdao.com/w/eng/中文詞語/#keyfrom=dict2.index。
那么可以用循環構成同樣類型的網頁后獲得對應詞語的意思,語句如下。
array=['秋風送爽','琵琶行','篳路藍縷','確實','過猶不及','海闊天空']
df_data=pd.DataFrame()
for item in array:url='http://www.youdao.com/w/eng/' + item + '/#keyfrom=dict2.index'html = requests.get(url)soup=BeautifulSoup(html.text,'lxml')data=soup.select('#phrsListTab > div.trans-container > ul > p > span:nth-child(1) > a')for subitem in data:result={'words':item,'title':subitem.get_text().replace('\n', ' '), 'link':subitem.get('href')}new=pd.DataFrame(result, index=[1])df_data=df_data.append(new,ignore_index=True)
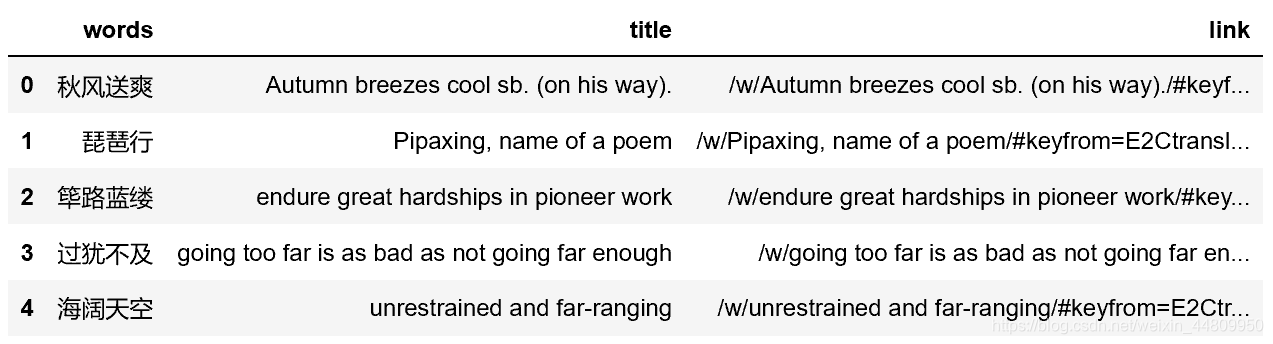
df_data.to_excel("D:/result1.xlsx", encoding='utf-8', index=False, header=True)需要查找的中文詞語做成列表,然后建立一個存放檢索結果的DataFrame。循環選擇每個詞語構成對應網頁,用requests庫的get()函數獲得網頁內容,然后用BeautifulSoup解析該網頁。用前2.2中所述方法獲得對應翻譯的selector,并通過select()函數獲得對應內容。再通過一個循環將提取標題和鏈接對應數據,每次提取后建立一個新的DataFrame名稱為new,然后添加到存放檢索結果的df_data當中去。獲得的df_data結果如下。最后同樣的,用lxml庫中的to_excel()將結果保存到excel文件中。
爬蟲是模擬人的瀏覽訪問行為,進行數據的批量抓取。當抓取的數據量逐漸增大時,會給被訪問的服務器造成很大的壓力,甚至有可能崩潰。換句話就是說,服務器是不喜歡有人抓取自己的數據的。那么,網站方面就會針對這些爬蟲者,采取一些反爬策略。服務器第一種識別爬蟲的方式就是通過檢查連接的 useragent 來識別到底是瀏覽器訪問,還是代碼訪問的。如果是代碼訪問的話,訪問量增大時,服務器會直接封掉來訪 IP。
那么應對這種初級的反爬機制,我們可以采用兩種簡單策略應對。一是構造瀏覽器的請求頭,封裝自己的請求;二是增加抓取數據的時間間隔。
我們只需要構造這個模擬瀏覽器請求的參數。創建請求頭部信息即可,代碼如下:
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18363'}
html = requests.get(url, headers=headers)這個headers必須是自己所用瀏覽器信息。獲得的方法是,首先用chrome瀏覽器瀏覽一個網頁,然后打開“開發者工具”,在“network”頁面中選擇“All”標簽。
左邊“Name”列表欄中很多個隨便選一欄點擊后,可以看到右邊“Headers”欄。在該欄目下找到“User-Agent”,其后面的內容就是requests.get的headers參數的值。具體如下圖所示。

就是常用的增設延時,例如每 1秒鐘抓取一次,代碼如下:
time.sleep(1)爬蟲異常會在沒有網絡連接(沒有路由到特定服務器),或者服務器不存在的情況下產生。但在正常情況下,多次重復的請求也可能網站響應緩慢而捕捉不到所需內容。當我們保證網站鏈接和服務器是正常的情況下,可以捕捉異常并再次請求的方法保證對網站的爬取。基本代碼如下:
i = 0
while i < 10:try:html = requests.get(url, timeout=5, headers=headers)return htmlexcept requests.exceptions.RequestException:i += 1print(i)requests庫中get()函數的timeout 參數,包括:
連接(connet)超時 指的是客戶端實現到遠端服務器端口的連接時request 所等待的時間。連接超時一般設為比 3 的倍數略大的一個數值,因為 TCP 數據包重傳窗口的默認大小是 3。
讀取(read)超時 指的客戶端已經連接上服務器并且發送了request后,客戶端等待服務器發送請求的時間。
timeout 可以設置一個元組,也可以象上述例程一樣設置單一的值,將會用作 connect 和 read 二者的 timeout。
如果發生響應超時的情況,則異常代碼為requests.exceptions.RequestException,這時異常處理次數增加1次。重復請求網頁,直到累計10次錯誤后退出循環。
仍然以有道翻譯中文詞語為例,實現了反爬蟲和異常處理的完整小程序如下:
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18363'}
def gethtml(url, headers):i = 0while i < 10:try:html = requests.get(url, timeout=5, headers=headers)return htmlexcept requests.exceptions.RequestException:i += 1print(i)array=['秋風送爽','琵琶行','篳路藍縷','確實','過猶不及','海闊天空']
df_data=pd.DataFrame()
for item in array:url='http://www.youdao.com/w/eng/' + item + '/#keyfrom=dict2.index'html = gethtml(url,headers)time.sleep(1)soup=BeautifulSoup(html.text,'lxml')data=soup.select('#phrsListTab > div.trans-container > ul > p > span:nth-child(1) > a')for subitem in data:result={'words':item,'title':subitem.get_text().replace('\n', ' '), 'link':subitem.get('href')}new=pd.DataFrame(result, index=[1])df_data=df_data.append(new,ignore_index=True)
df_data.to_excel("D:/result1.xlsx", encoding='utf-8', index=False, header=True)本文實現了完整的python小爬蟲。具體網頁的selector要根據自己所需內容確定;get()獲取網頁的Headers參數也要根據自己的電腦條件填寫;最終獲得的數據還應該根據自己的需求繼續處理,本文當中僅做了最簡單處理。
另外,這個是requests庫中get()方式獲得網頁,另外一種requests庫中的post()方式獲得網頁在別的篇幅中再做介紹。
版权声明:本站所有资料均为网友推荐收集整理而来,仅供学习和研究交流使用。

工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态