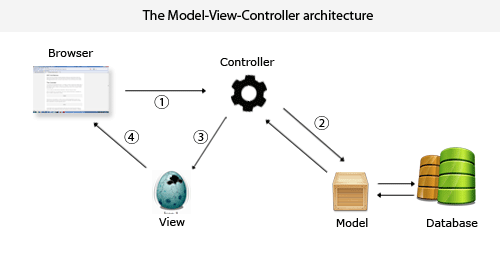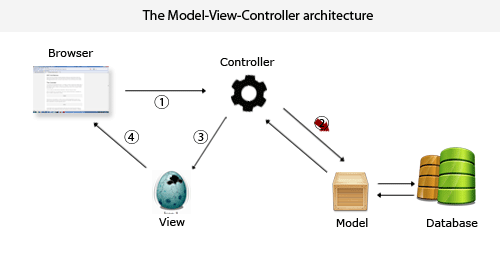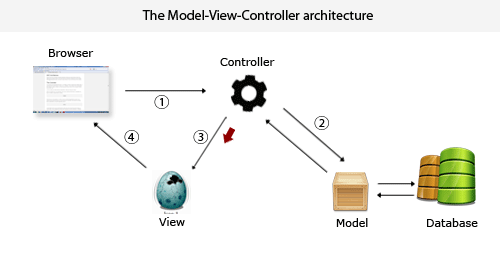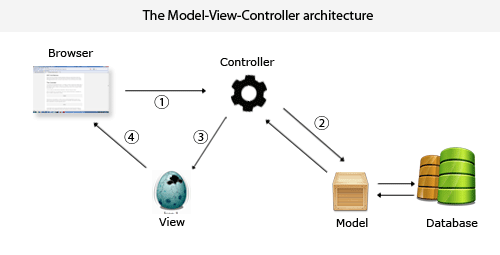
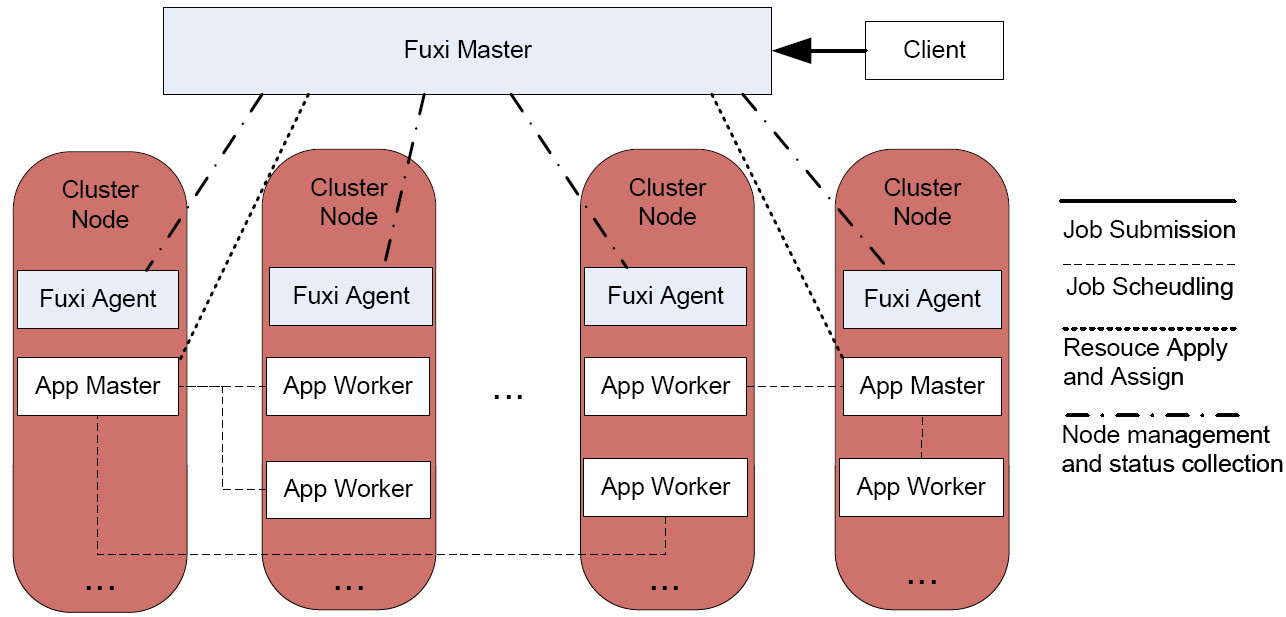
2019独角兽企业重金招聘Python工程师标准>>> 
一、性能测试相关术语介绍。
1.响应时间。
客户端显示时间,如何将服务器传过来的页面尽快显示到浏览器上,是开发 人员需要考虑的问题,这里面涉及算法优化等问题。这也是开发人员容易忽视的地方。
2.吞吐量
数据库如何优化, 是指单位时间内流经被测系统的数据流量,一般单位为b/s,即每秒钟流经的字节数。
吞吐量和很多相关的因素有关,比如服务器的硬件配置,网络的拓扑结构,软件的技术架构等。相对于对电子商务网站来说要求比较高。
3.并发
并发,是指多个同时发生的操作。
需要注意的是,并发和并行不是一个概念,并发是同时发生,并行是同步运行。
4.稳定性测试
数据库优化、 也叫可靠性测试,是指连续被测系统,检查系统运行时的稳定程度。
5.负载测试
通常是指让被测系统在其能忍受的压力的极限范围之内连续运行,来测试系统的稳定性。假如现在的并发用户数为20,我们就用这20个用户同时多次重复登入,直到系统出现故障为止。负载测试为我们测试系统在临界状态下运行是否稳定提供一种方法。
6.压力测试
通常指连续不断的给被测系统增加压力,直到将被测系统压垮为止,用来测试系统所能承受的最大压力。比如我们不断增加并发的登入用户数,直到崩溃。
以上为相关术语的介绍。
oracle数据库优化思路。二、创建数据库时的优化
1.建表
一般把主键ID设置为自动增长,方便查询,同时ID为int类型。同时会加上创建时间和删除事件。
2.总结
检查ER中各个表之间的关系是否合理。
检查每个数据表的字段类型和长度,看是否影响性能的地方。
数据库优化技术。 检查触发器和存储过程所对应的SQL语句,是否有需要改进的地方,以提高执行效率。
索引设计是否合理。
三、数据库对象级别的优化
包括以下方面:数据库范式设计的优化,数据表设计的优化,索引设计的优化,以及sql语句的优化。
1.范式设计的优化
遵守范式的规则, 数据库设计时会产生较少的列和更多的表,因而也就减少了数据冗余,但同时表关系也变得复杂起来,查询某一条记录时,往往需要合并多个表来处理,这样会降低系统性能。
数据库的调优、 如何平衡呢?这就需要我们对设计的系统非常熟悉,清楚地知道哪些数据是要被经常访问和重复查询的,而哪些数据只是偶尔会被操作,对于经常被查询和操作的数据所在的数据库,可以适当的放宽范式设计的标准。
设计过程如下:1).如果真的需要在两个表之间,使用第三范式,那么我们就要在这两个表之间建立一个关联表。比如学生和课程,一个学生对应多个课程,一个成绩对应多个课程。如果需要知道成绩,即需要学号,也需要课程。这样的话可以创建一个存储过程完成上述要求,并在空闲的时候加以执行。
2).将常用的计算字段(比如求和,求平均值)放入数据表中。
3).将一个数据表拆分成两个部分。这里面的是拆分又包括了拆分列和拆分行。拆分列指的是如果是一个数据表中的字段是有一部分会被频繁使用,而另一部分基本不会被使用,则可以考虑按照使用频率将该数据库拆分成两个表。拆分行指的是如果一个数据表中的一部分记录会被频繁使用,而另一部分记录却很少被使用,则可以拆分两个表。
2.表设计的优化选择
1).除非必要,避免使用允许null值的列和可变长度的列,处理null值会带来额外的开销。
数据库性能、 2).视图的处理速度并不是很快,如果能在程序中直接实现视图的功能最好。
3).视图只是逻辑结构,通常使用视图时要过滤某些固定的数据;当然,使用视图时要考虑效率,如果两个大表关联,那查询速度是很慢的,使用临时表。
4).字段的长度够用就好,不要浪费空间。
5).如果开发的系统是单一语言的,就不需要Unicode的数据类型。
6).外键约束的处理速度比触发器要快的多。
7).避免使用text类型的字段。
sql数据库优化从哪些方面。 8).正确的使用索引。
9).对于日期类型来说,使用smalldatetime类型就可以了。
3.索引的优化选择
索引主要分为聚簇索引(也称为聚类索引)和非聚簇索引,一个数据表只能有一个聚簇索引,可以有多个非聚簇索引。合理的使用索引可以大大提高数据的查询速度,是优化数据表查询性能的最常用途径之一。但是在添加聚簇索引的时候一定要考察目标数据表的特点,因为它会降低数据的插入和更新速度,如果数据表中的数据会频繁的更新的话,建议不要使用。
如何使用聚簇索引和非聚簇索引呢?
两种索引使用的时机
| 目标列 | 聚簇索引 | 非聚簇索引 |
| 经常被分组排序 | 应该使用 | 可以使用 |
| 含有小数目的不同值 | 应该使用 | 不应使用 |
| 含有大数目的不同值 | 不应使用 | 应该使用 |
| 极少有不同值比,如性别 | 不应使用 | 不应使用 |
| 频繁更新的列 | 不应使用 | 应该使用 |
提高数据库性能的几种方法。注意:认为就应该在主键创建聚簇索引,虽然字段ID比较适合做主键(唯一性),但由于其含有大数目的不同值,并不适合用聚簇索引。我们应用聚簇索引的方法就是看哪一个字段在查询条件中应用的最为频繁。比如用户ID主键,就可以建立一个。
最好选择查询条件中的使用最频繁的字段作为前导列,放在复合索引的最前面。对于多个字段一起频繁出现的情况可以使用复合索引,并且将使用最频繁的查询条件作为复合索引的前导列。
4.SQL语句级别的优化
数据的原则:
1).使用select语句查询时,尽量不要使用select * 语句,而是应该指明具体要查询的字段,提取的字段数量越少,查询的速度越快。
2).使用order by语句排序时,最好按照聚簇索引的字段排序,这样会大大提高排序的速度。
数据库优化从哪些方面。 3).尽量不要使用or 关键字,或是in(),否则会引起全表扫描,大大降低数据的检索速度。
4).对笛卡尔积、游标、循环要谨慎使用。
5).存储过程、函数、包、触发器等尽量不要超过1000行,之间调用不要复杂。
6).order by 、group by、distinct这些语句运行时相对来说会占用较大内存,使用需加以注意。
7).检查嵌套、递归、子查询,最好不要超过3层。
8).尽量少用not,包括not in和 not exist。
数据库的优化方法? 9).between 1 and 10 要比 in(1,10)的执行效率高。
10).数值类型的字段要比字符串类型的字段执行效率高。
11).当where语句后有多个查询条件时,应该将数据量大的表查询过滤条件放在前面。
12).like语句是很耗时间的,如果允许的话,可以使用功能相同的语句代替。
13).尽量不要在sql语句中进行对列的操作,包括数据库函数,计算表达式等,否则会导致表扫描。要尽可能将操作移至等号右边。比如应该写成这样: select * from user where score >10*10。
如何优化sql、