一、base64原理简介
base64可以理解为一种加密算法,用64个常见字符来表示8字节的二进制数字。
64个字符:'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/'
base64转换后的结果只会出现这64个字符,这也是base64名字的由来。(由于不同的应用场景,当+或/有特殊含义时,这两个字符被换成了其他字符,那属于base64的变种)。
那64个字符怎么表示8字节的二进制数字呢?
首先,上面的64个字符按顺序分别对应了十进制数字的0到63,可以理解为上面的字符串的索引。
其次,一个8位二进制数字转换为十进制后表示的是0到255。base64会物理上将3个8位(3*8=24位)的二进制数据连在一起,然后切分成4个6位(4*6=24位)的二进制数据,然后再在这4个6位二进制数据的前面都补两个0,补满8位。这样处理后的二进制数字转换为十进制后表示的是0到63。
聪明的您应该明白了,这刚好与上面的0到63个字符对应。可以参考下面的图片。
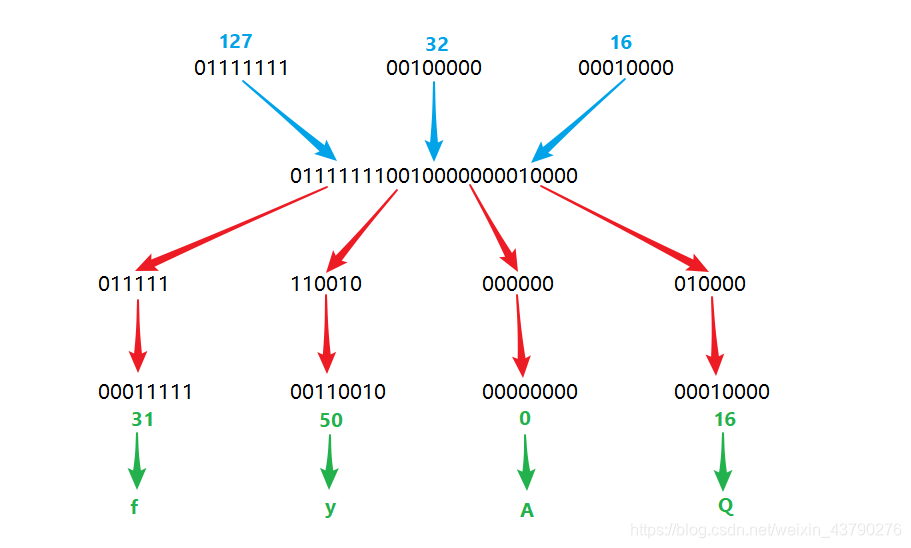
对于需要加密的内容,base64都会先将其转换为8位的二进制数据,然后进行上面的处理。
这样,我们用逆向思维,就已经搞清楚base64的原理了。
另外,base64会在数据的末尾填充等号=。一般来说,对字符串进行base64转换时,字符数量整除3不会补=,余1会补两个==,余2会补一个=。
二、base64对字符串进行转换
# coding=utf-8
import base64
import string
import randombase_str = string.ascii_letters + string.punctuation
print(base_str)
result_str = ''.join(random.choices(base_str, k=20))
print(result_str)
result = base64.encodebytes(bytes(result_str.encode('utf-8'))).decode('utf-8')
print(result)
result_back = base64.decodebytes(bytes(result.encode('utf-8'))).decode('utf-8')
print(result_back)运行结果:
abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ!"#$%&'()*+,-./:;<=>?@[\]^_`{|}~
C{%H/>wHXk:H.Jlf<UBy
Q3slSC8+d0hYazpILkpsZjxVQnk=C{%H/>wHXk:H.Jlf<UBy上面的代码中,我们从字符中随机选取了20个字符,用encodebytes()方法将字符串转换成了base64字符,然后用decodebytes()方法将base64转换回字符串。
在Python的base64模块中,encodebytes()与decodebytes()互为逆运算,具体用法如上面代码。
如果是在Python2中,random没有choices()方法,encodebytes()和decodebytes() 要分别换成 encodestring()和decodestring()。
# Python2
result_str = 'UVWXYZ!#$%&()*+,-./'
print(result_str)
result = base64.encodestring(bytes(result_str.encode('utf-8'))).decode('utf-8')
print(result)
result_back = base64.decodestring(bytes(result.encode('utf-8'))).decode('utf-8')
print(result_back)运行结果:
UVWXYZ!#$%&()*+,-./
VVZXWFlaISMkJSYoKSorLC0uLw==UVWXYZ!#$%&()*+,-./三、base64对文件中的字符串进行转换
base_str = string.ascii_letters + string.punctuation
print(base_str)
result_str = ''.join(random.choices(base_str, k=20))
print(result_str)
with open('base64.txt', 'wb') as f:f.write(bytes(result_str.encode('utf-8')))
base64.encode(open('base64.txt', 'rb'), open('base64.b64', 'wb'))
print(open("base64.b64").read())base64.decode(open('base64.b64', 'rb'), open('base64.new', 'wb'))
print(open("base64.new").read())运行结果:
abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ!"#$%&'()*+,-./:;<=>?@[\]^_`{|}~
_iPv}x\},*mkn,IYsqD#
X2lQdn14XH0sKm1rbixJWXNxRCM=_iPv}x\},*mkn,IYsqD#上面的代码中,我们先随机生成了一串字符,写入base64.txt中,然后用base64.encode()方法读取字符,转换成base64字符后写入base64.b64文件中。然后又用base64.decode()方法读取出base64字符,将base64字符转换回原始字符后写入base64.new文件中。
在Python的base64模块中,base64.encode()与base64.decode()互为逆运算。
代码运行后,会在当前目录下生成三个文件,分别是base64.txt, base64.b64, base64.new, 用文本方式打开,base64.txt中的字符串是转换前的字符串, base64.b64中的字符是base64字符串, base64.new中的字符串与base64.txt中一模一样。
四、base64其他方法的使用
base_str = string.ascii_letters + string.punctuation
print(base_str)
result_str = ''.join(random.choices(base_str, k=20))
print(result_str)
result = base64.b64encode(bytes(result_str.encode('utf-8'))).decode('utf-8')
print(result)
result_back = base64.b64decode(bytes(result.encode('utf-8'))).decode('utf-8')
print(result_back)运行结果:
abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ!"#$%&'()*+,-./:;<=>?@[\]^_`{|}~
$\kFS:TkXHQkkw[GMl,k
JFxrRlM6VGtYSFFra3dbR01sLGs=
$\kFS:TkXHQkkw[GMl,k代码还是之前的代码,只是把 encodebytes()和decodebytes() 换成了 b64encode()和b64decode(),效果也是一样的,只是encode时少了一个换行符而已。
除了b64encode()之外,base64模块中还有几对成对的方法,都是从base64延伸出来的。b32encode()和b32decode(), b16encode()和b16decode(),b85encode()和b85decode(), a85encode()和a85decode(), standard_b64encode()和standard_b64decode(),
urlsafe_b64encode()和urlsafe_b64decode()。
使用方法与上面的完全一样,直接用方法名换掉上面代码中的的方法名就可以运行。只是转换的原理和转换的结果不同,应用的地方也有区别,比如urlsafe_b64encode是为了避免转换时使用斜杠/,因为url中有斜杠/,会造成混淆,所以改了转换时使用的字符。感兴趣的话可以慢慢研究。

版权声明:本站所有资料均为网友推荐收集整理而来,仅供学习和研究交流使用。

工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态