在很多系统中都允许用户设置单条消息处理模式或者批处理模式。例如,在storm中,用户可以通过core和Trident两种API编写,区别是前者是一个tuple一个tuple地处理,而后者是多个tuple组成一个batch,然后一个batch一个batch地处理。
由于这两种处理模式的不同,导致二者在性能上的表现也不同,例如吞吐率和延迟。下面引用一个典型的测试结果,详情:https://github.com/ptgoetz/storm-benchmark。
| 测试环境:5 nodes on AWS,1zookeeper,1nimbus,3supervisor(配置一般) 测试程序:内存拷贝 | ||
|
| 吞吐率(tuple/sec) | 延迟(ms) |
| Storm Core API | 约150k | 约80 |
| Storm Trident API | 约300k | 约250 |
从结果可以看出,Trident相对于Core来说,吞吐率上升了1倍,而延迟也上升了2倍左右。在实际的开发过程中,一般Core API用地相对多一些。
上面只是“高吞吐率往往伴随着高延迟”的一个特例,下面我从理论上抽象地(不是针对某一种特定技术)对这一现象给予解释。
一个batch由多个tuple构成,因此抽象地看多个tuple和多个batch的处理过程可以用下图表示:
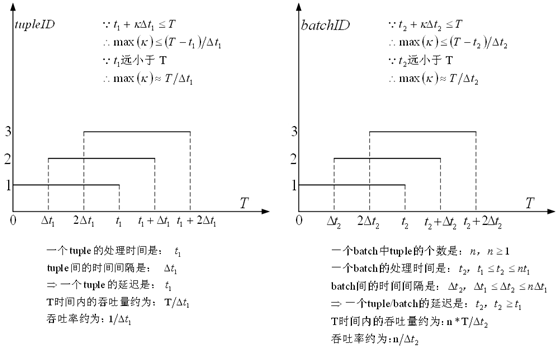
其中,一般情况下处理一个batch的时间比处理一个tuple的时间要长,但不会大于一个tuple处理时长的n倍,这是由于处理系统一般会为批处理做很多优化,提高其处理效率。同理,batch间的时间间隔比tuple间的时间间隔大,但小于tuple间时间间隔的n倍。因此,一个batch的延迟会大于一个tuple的延迟,但吞吐率会上升,即“高吞吐率往往伴随着高延迟”。
基于上述分析结果,文章开始的测试结果就不难理解了,并且这一测试结果只是普遍规律的一个特例。