Kafka 是當下熱門的消息隊列中間件,它可以實時地處理海量數據,具備高吞吐、低延時等特性及可靠的消息異步傳遞機制,可以很好地解決不同系統間數據的交流和傳遞問題。
Kafka 在馬蜂窩也有非常廣泛的應用,為很多核心的業務提供支撐。本文將圍繞 Kafka 在馬蜂窩大數據平臺的應用實踐,介紹相關業務場景、在 Kafka 應用的不同階段我們遇到了哪些問題以及如何解決、之后還有哪些計劃等。
一、應用場景kafka集群高可用?從 Kafka 在大數據平臺的應用場景來看,主要分為以下三類:
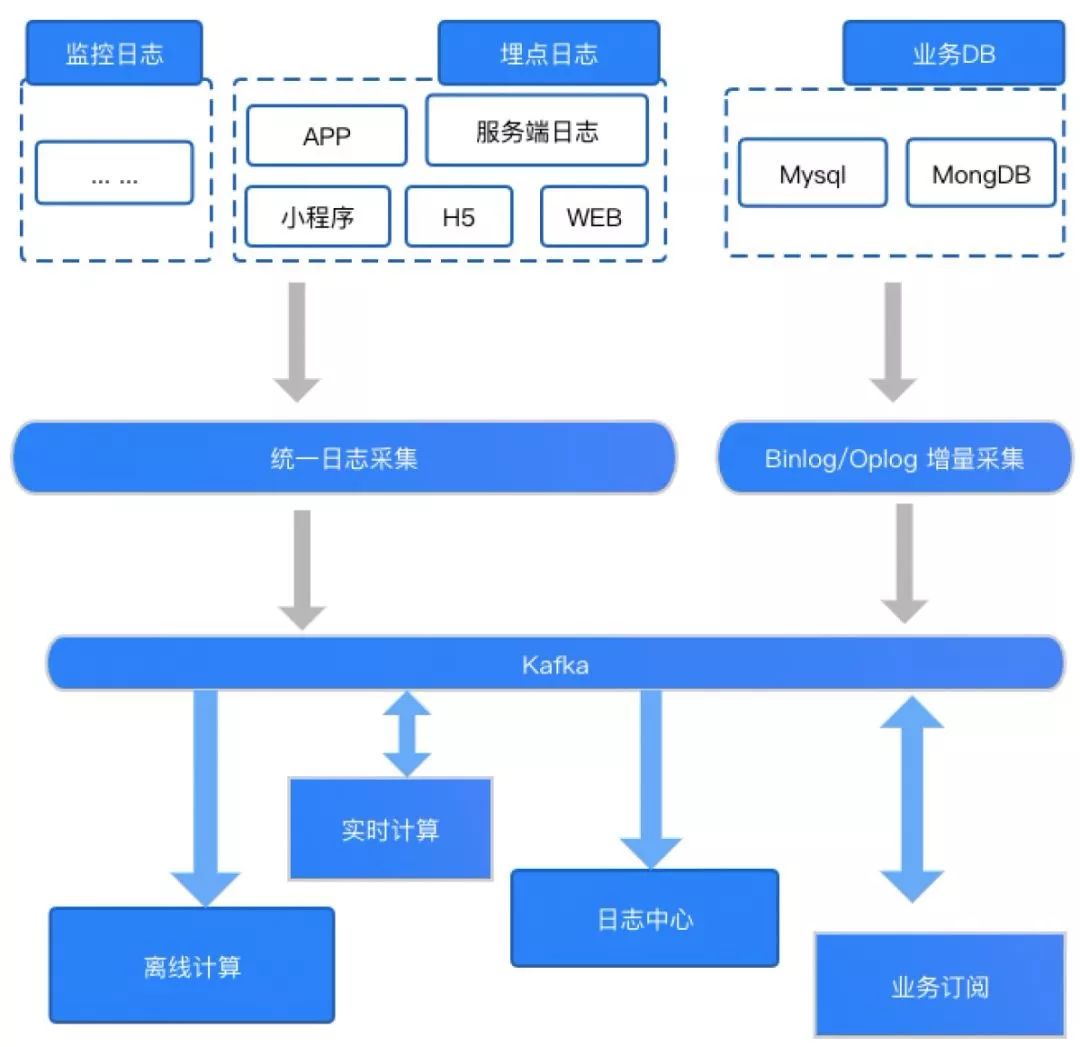
第一類是將 Kafka 作為數據庫,提供大數據平臺對實時數據的存儲服務。從來源和用途兩個維度來說,可以將實時數據分為業務端 DB 數據、監控類型日志、基于埋點的客戶端日志(H5、WEB、APP、小程序)和服務端日志。
第二類是為數據分析提供數據源,各埋點日志會作為數據源,支持并對接公司離線數據、實時數據倉庫及分析系統,包括多維查詢、實時 Druid OLAP、日志明細等。
netty集群,第三類是為業務方提供數據訂閱。除了在大數據平臺內部的應用之外,我們還使用 Kafka 為推薦搜索、大交通、酒店、內容中心等核心業務提供數據訂閱服務,如用戶實時特征計算、用戶實時畫像訓練及實時推薦、反作弊、業務監控報警等。
主要應用如下圖所示:
kafka 集群、早期大數據平臺之所以引入 Kafka 作為業務日志的收集處理系統,主要是考慮到它高吞吐低延遲、多重訂閱、數據回溯等特點,可以更好地滿足大數據場景的需求。
但隨著業務量的迅速增加,以及在業務使用和系統維護中遇到的問題,例如注冊機制、監控機制等的不完善,導致出現問題無法快速定位,以及一些線上實時任務發生故障后沒有快速恢復導致消息積壓等, 使 Kafka 集群的穩定性和可用性得受到挑戰,經歷了幾次嚴重的故障。
解決以上問題對我們來說迫切而棘手。針對大數據平臺在使用 Kafka 上存在的一些痛點,我們從集群使用到應用層擴展做了一系列的實踐,整體來說包括四個階段:
kafka集群部署。第一階段:版本升級
圍繞平臺數據生產和消費方面存在的一些瓶頸和問題,我們針對目前的 Kafka 版本進行技術選型,最終確定使用 1.1.1 版本。
第二階段:資源隔離
為了支持業務的快速發展,我們完善了多集群建設以及集群內 Topic 間的資源隔離。
第三階段:權限控制和監控告警
首先在安全方面,早期的 Kafka 集群處于裸跑狀態。由于多產品線共用 Kafka,很容易由于誤讀其他業務的 Topic 導致數據安全問題。因此我們基于 SASL/ SCRAM + ACL 增加了鑒權的功能。
在監控告警方面,Kafka 目前已然成為實時計算中輸入數據源的標配,那么其中 Lag 積壓情況、吞吐情況就成為實時任務是否健康的重要指標。因此,大數據平臺構建了統一的 Kafka 監控告警平臺并命名「雷達」,多維度監控 Kafka 集群及使用方情況。
第四階段:應用擴展
早期 Kafka 在對公司各業務線開放的過程中,由于缺乏統一的使用規范,導致了一些業務方的不正確使用。為解決該痛點,我們構建了實時訂閱平臺,通過應用服務的形式賦能給業務方,實現數據生產和消費申請、平臺的用戶授權、使用方監控告警等眾多環節流程化自動化,打造從需求方使用到資源全方位管控的整體閉環。
下面圍繞幾個關鍵點為大家展開介紹。
2、核心實踐1)版本升級
之前大數據平臺一直使用的是 0.8.3 這一 Kafka 早期版本,而截止到當前,Kafka 官方最新的 Release 版本已經到了 2.3,于是長期使用 0.8 版本過程中漸漸遇到的很多瓶頸和問題,我們是能夠通過版本升級來解決的。
舉例來說,以下是一些之前使用舊版時常見的問題:
缺少對 Security 的支持:存在數據安全性問題及無法通過認證授權對資源使用細粒度管理;
broker under replicated:發現 broker 處于 under replicated 狀態,但不確定問題的產生原因,難以解決;
新的 feature 無法使用:如事務消息、冪等消息、消息時間戳、消息查詢等;
客戶端的對 offset 的管理依賴 zookeeper, 對 zookeeper 的使用過重, 增加運維的復雜度;
監控指標不完善:如 topic、partition、broker 的數據 size 指標, 同時 kafka manager 等監控工具對低版本 kafka 支持不好。
同時對一些目標版本的特性進行了選型調研,如:
0.9 版本, 增加了配額和安全性, 其中安全認證和授權是我們最關注的功能;
0.10 版本,更細粒度的時間戳. 可以基于偏移量進行快速的數據查找,找到所要的時間戳。這在實時數據處理中基于 Kafka 數據源的數據重播是極其重要的;
0.11 版本, 冪等性和 Transactions 的支持及副本數據丟失/數據不一致的解決;
冪等性意味著對于同一個 Partition,面對 Data 的多次發布,Kafka broker 端就可以做到自動去重;
對 Transactions 的支持使一個事務下發布多條信息到多個Topic Partition 時,我們可以使它以原子性的方式被完成。在我們的下游消費者中,很多都是用 Flink 做一些流處理的工作,因此在數據處理及故障恢復時僅一次語義則顯得尤為重要。而0.11 版本對于事務的支持則可以保證與 Kafka 交互的 Flink 應用實現端到端僅一次語義, 支持 EOS 可以對數據可靠性有絕對要求, 比如交易、風控等場景下的重要支持;
Leader Epoch:解決了原先依賴水位表示副本進度可能造成的數據丟失/數據不一致問題;
1.1 版本,運維性的提升。比如當 Controller Shut Down,想要關閉一個 Broker 的時候,之前需要一個很長很復雜的過程在 1.0 版本得到很大的改善。
最終選擇 1.1 版本, 則是因為出于 Camus 與 Kafka 版本的兼容性及 1.1 版本已經滿足了使用場景中重要新特性的支持的綜合考量。這里再簡單說一下 Camus 組件,同樣是由 Linkedin 開源,在我們的大數據平臺中主要作為 Kafka 數據 Dump 到 HDFS 的重要方式。
2)資源隔離
之前由于業務的復雜性和規模不大,大數據平臺對于 Kafka 集群的劃分比較簡單。于是,一段時間以后導致公司業務數據混雜在一起,某一個業務主題存在的不合理使用都有可能導致某些 Broker 負載過重,影響到其他正常的業務,甚至某些 Broker 的故障會出現影響整個集群,導致全公司業務不可用的風險。
針對以上的問題,在集群改造上做了兩方面實踐
按功能屬性拆分獨立的集群;
集群內部 Topic 粒度的資源隔離。
①集群拆分
按照功能維度拆分多個 Kafka 物理集群,進行業務隔離,降低運維復雜度。
以目前最重要的埋點數據使用來說, 目前拆分為三類集群,各類集群的功能定義如下:
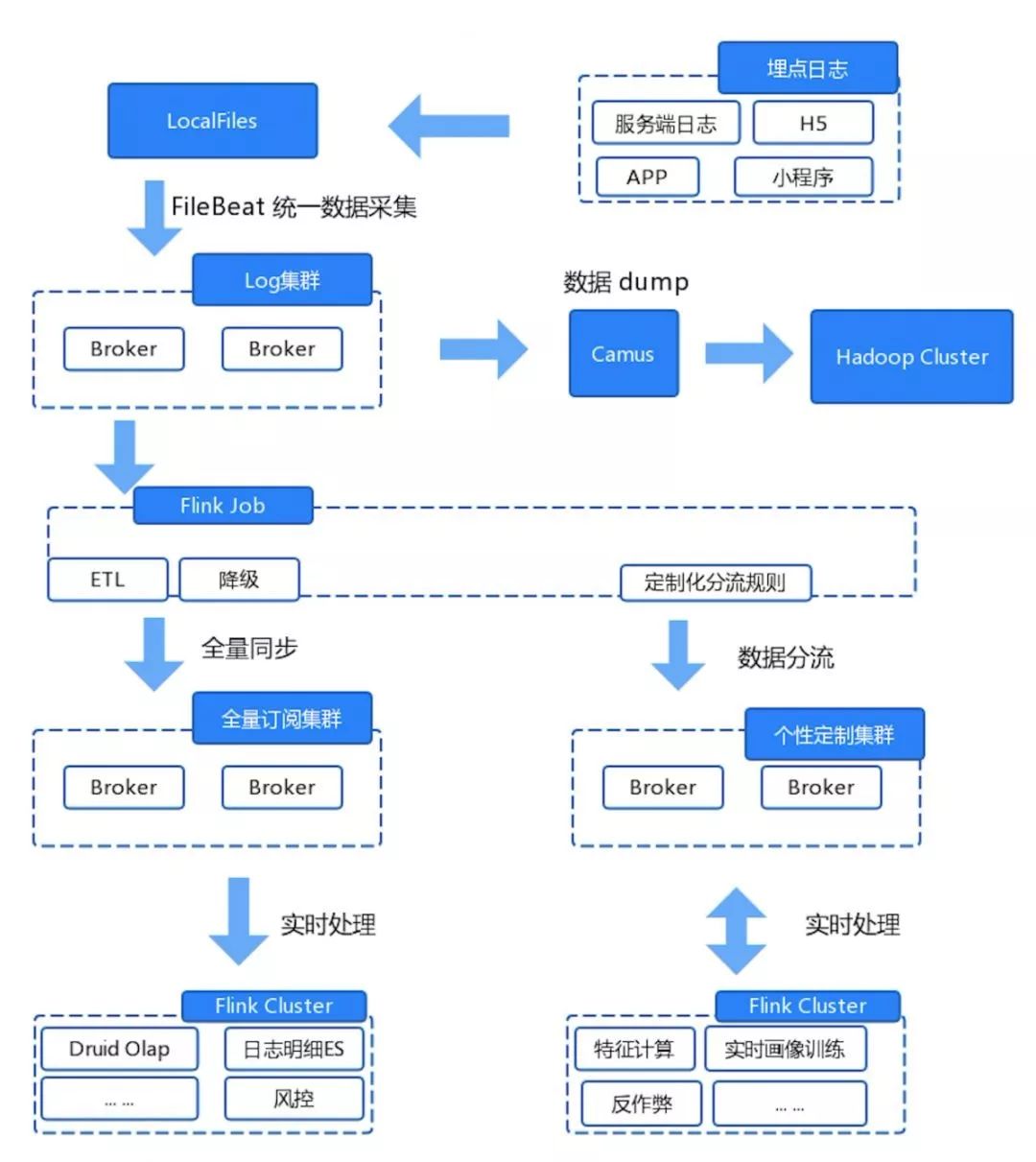
Log 集群:各端的埋點數據采集后會優先落地到該集群, 所以這個過程不能出現由于 Kafka 問題導致采集中斷,這對 Kafka 可用性要求很高。因此該集群不會對外提供訂閱,保證消費方可控;同時該集群業務也作為離線采集的源頭,數據會通過 Camus 組件按小時時間粒度 dump 到 HDFS 中,這部分數據參與后續的離線計算。
全量訂閱集群:該集群 Topic 中的絕大部分數據是從 Log 集群實時同步過來的。上面我們提到了 Log 集群的數據是不對外的,因此全量集群就承擔了消費訂閱的職責。目前主要是用于平臺內部的實時任務中,來對多個業務線的數據分析并提供分析服務。
個性定制集群:之前提到過,我們可以根據業務方需求來拆分、合并數據日志源,同時我們還支持定制化 Topic,該集群只需要提供分流后 Topic 的落地存儲。
集群整體架構劃分如下圖:
②資源隔離
Topic 的流量大小是集群內部進行資源隔離的重要依據。例如,我們在業務中埋點日志量較大的兩個數據源分別是后端埋點數據源 server-event 和端上的埋點 mobile-event 數據源,我們要避免存儲兩個數據的主題分區分配到集群中同一個 Broker 上的節點。通過在不同 Topic 進行物理隔離,就可以避免 Broker 上的流量發生傾斜。
3)權限控制和監控告警
①權限控制
開始介紹時我們說過,早期 Kafka 集群沒有設置安全驗證處于裸跑狀態,因此只要知道 Broker 的連接地址即可生產消費,存在嚴重的數據安全性問題。
一般來說, 使用 SASL 的用戶多會選擇 Kerberos,但就平臺 Kafka 集群的使用場景來說,用戶系統并不復雜,使用 Kerberos 就有些大材小用, 同時 Kerberos 相對復雜,存在引發其他問題的風險。另外,在 Encryption 方面, 由于都是運行在內網環境,所以并沒有使用 SSL 加密。
最終平臺 Kafka 集群使用 SASL 作為鑒權方式, 基于 SASL/ SCRAM + ACL 的輕量級組合方式,實現動態創建用戶,保障數據安全。
②監控告警
之前在集群的使用中我們經常發現,消費應用的性能無緣無故變差了。分析問題的原因, 通常是滯后 Consumer 讀取的數據大概率沒有命中 Page- cache,導致 Broker 端機器的內核要首先從磁盤讀取數據加載到 Page- cache 中后,才能將結果返還給 Consumer,相當于本來可以服務于寫操作的磁盤現在要讀取數據了, 影響了使用方讀寫同時降低的集群的性能。
這時就需要找出滯后 Consumer 的應用進行事前的干預從而減少問題發生,因此監控告警無論對平臺還是用戶都有著重大的意義。下面介紹一下我們的實踐思路。
整體方案:
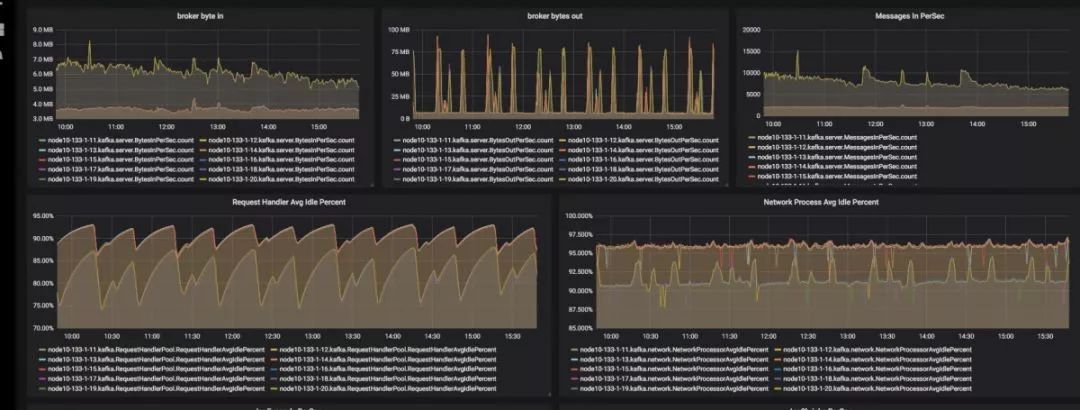
整體方案主要是基于開源組件 Kafka JMX?Metrics+OpenFalcon+Grafana:
Kafka JMX Metrics:Kafka broker 的內部指標都以 JMX Metrics 的形式暴露給外部。1.1.1 版本 提供了豐富的監控指標,滿足監控需要;
OpenFalcon:小米開源的一款企業級、高可用、可擴展的開源監控系統;
Grafana:Metrics 可視化系統,大家比較熟悉,可對接多種 Metrics 數據源。
關于監控:
Falcon-agent:部署到每臺 Broker 上, 解析 Kafka JMX 指標上報數據;
Grafana:用來可視化 Falcon Kafka Metrics 數據,對 Cluster、Broker、Topic、Consumer 4 個角色制作監控大盤;
Eagle:獲取消費組 Active 狀態、消費組 Lag 積壓情況,同時提供 API,為監控告警系統「雷達」提供監控數據。
關于告警:
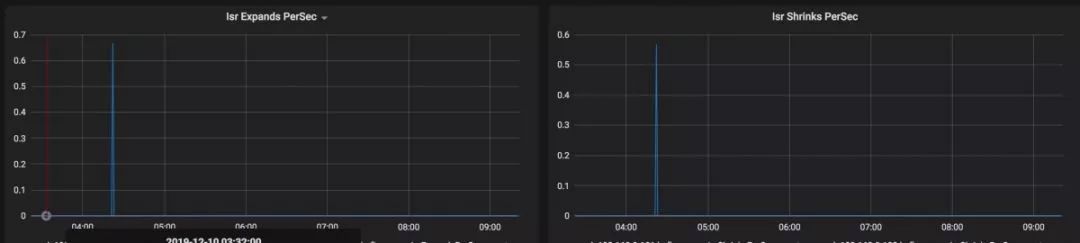
雷達系統: 自研監控系統,通過 Falcon 及 Eagle 獲取 Kafka 指標,結合設定閾值進行告警。以消費方式舉例,Lag 是衡量消費情況是否正常的一個重要指標,如果 Lag 一直增加,必須要對它進行處理。
發生問題的時候,不僅 Consumer 管理員要知道,它的用戶也要知道,所以報警系統也需要通知到用戶。具體方式是通過企業微信告警機器人自動提醒對應消費組的負責人或使用者及 Kafka 集群的管理者。
監控示例:




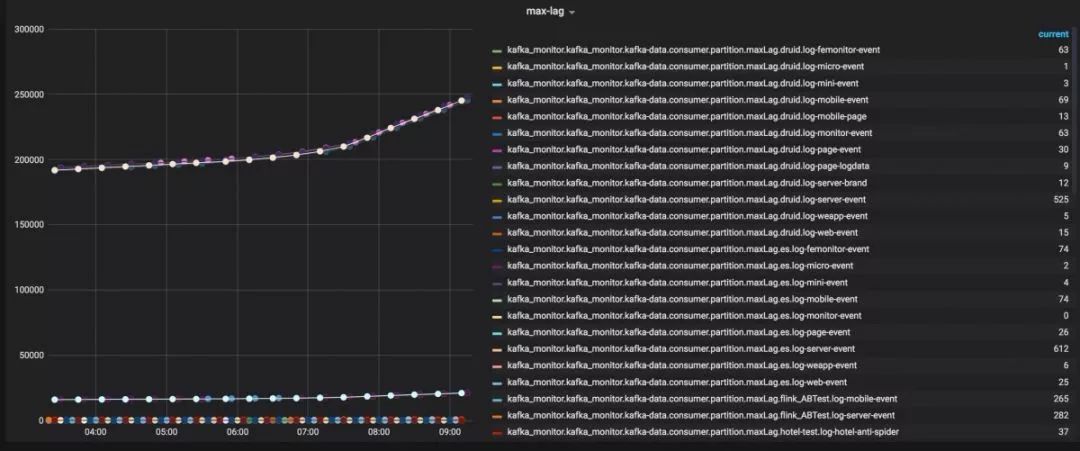
4)應用擴展
①實時數據訂閱平臺?
實時數據訂閱平臺是一個提供 Kafka 使用全流程管理的系統應用,以工單審批的方式將數據生產和消費申請、平臺用戶授權、使用方監控告警等眾多環節流程化自動化, 并提供統一管控。
核心思想是基于 Kafka 數據源的身份認證和權限控制,增加數據安全性的同時對 Kafka 下游應用進行管理。
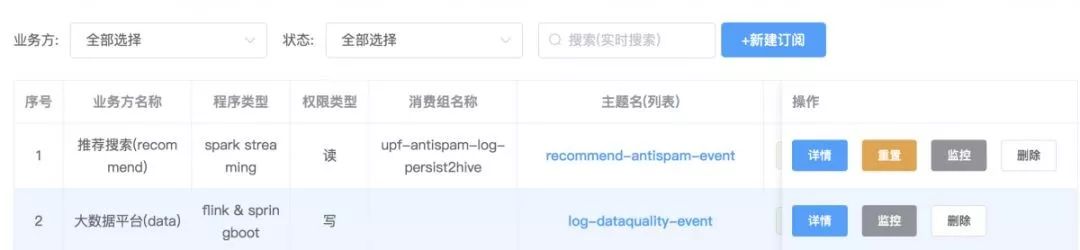
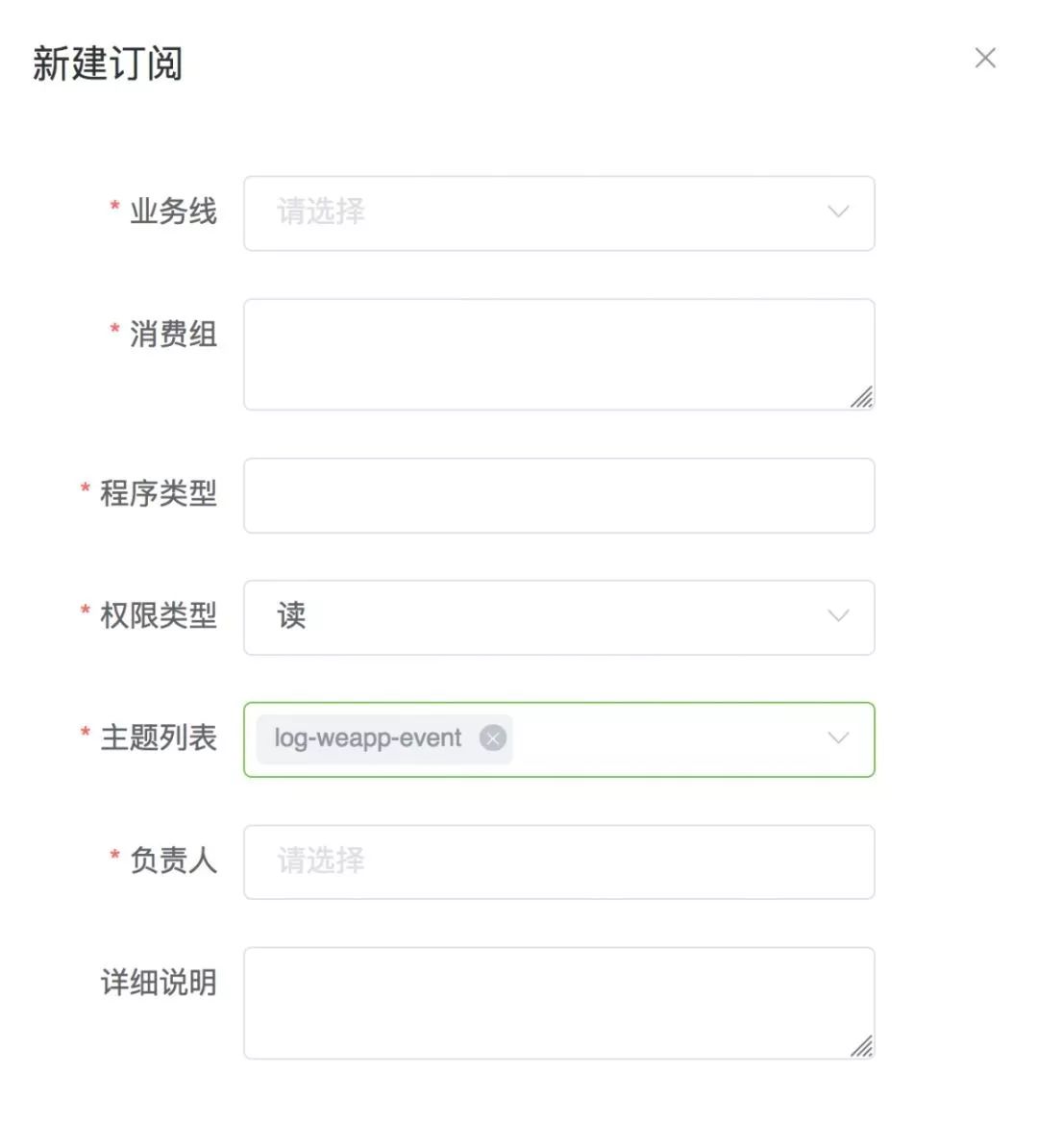
②標準化的申請流程
無論生產者還是消費者的需求,使用方首先會以工單的方式提出訂閱申請。申請信息包括業務線、Topic、訂閱方式等信息;工單最終會流轉到平臺等待審批;如果審批通過,使用方會分配到授權賬號及 Broker 地址。至此,使用方就可以進行正常的生產消費了。
③監控告警
對于平臺來說,權限與資源是綁定的,資源可以是用于生產的 Topic 或消費使用的 GroupTopic。一旦權限分配后,對于該部分資源的使用就會自動在我們的雷達監控系統進行注冊,用于資源整個生命的周期的監控。?
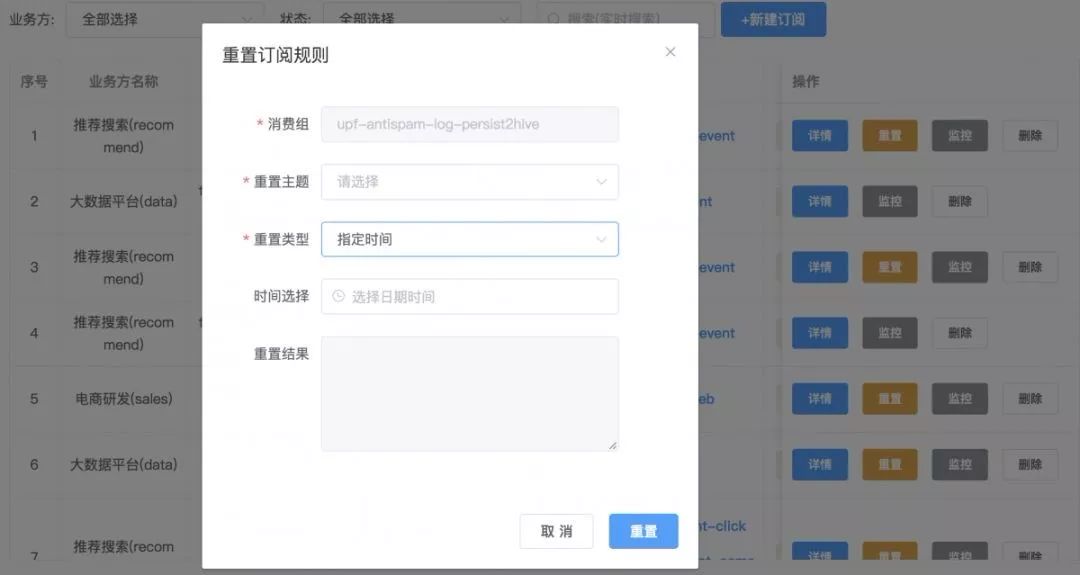
④數據重播
出于對數據完整性和準確性的考量,目前 Lamda 架構已經是大數據的一種常用架構方式。但從另一方面來說, Lamda 架構也存在資源的過多使用和開發難度高等問題。
實時訂閱平臺可以為消費組提供任意位點的重置,支持對實時數據按時間、位點等多種方式的數據重播, 并提供對 Kappa 架構場景的支持,來解決以上痛點。
⑤主題管理
為什么提供主題管理?舉一些很簡單的例子,比如當我們想讓一個用戶在集群上創建他自己的 Kafka ?Topic,這時顯然是不希望讓他直接到一個節點上操作的。因此剛才所講的服務,不管是對用戶來講,還是管理員來講,我們都需要有一個界面操作它,因為不可能所有人都通過 SSH 去連服務器。
因此需要一個提供管理功能的服務,創建統一的入口并引入主題管理的服務,包括主題的創建、資源隔離指定、主題元數據管理等。
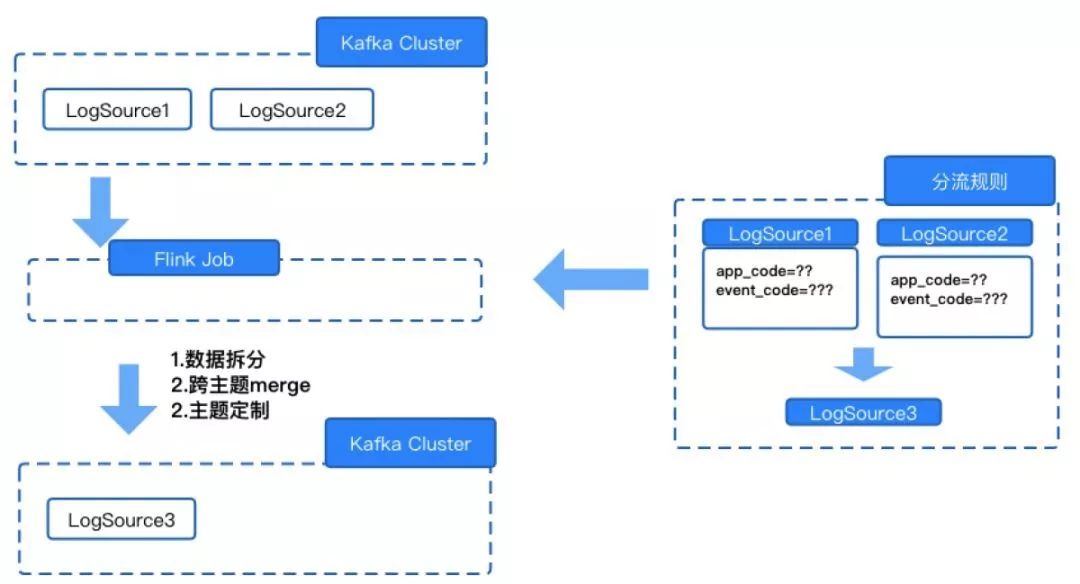
⑥數據分流
在之前的架構中, 使用方消費 Kafka 數據的粒度都是每個 Kafka Topic 保存 LogSource 的全量數據,但在使用中很多消費方只需要消費各 LogSource 的部分數據,可能也就是某一個應用下幾個埋點事件的數據。如果需要下游應用自己寫過濾規則,肯定存在資源的浪費及使用便捷性的問題;另外還有一部分場景是需要多個數據源 Merge 在一起來使用的。
基于上面的兩種情況, 我人實現了按業務方需求拆分、合并并定制化 Topic 支持跨數據源的數據合并及 appcode 和 event code 的任意組個條件的過濾規則。
1、解決數據重復問題。為了解決目前平臺實時流處理中因故障恢復等因素導致數據重復的問題,我們正在嘗試用 Kafka 的事務機制結合 Flink 的兩段提交協議實現端到端的僅一次語義。目前已經在平臺上小范圍試用, 如果通過測試,將會在生產環境下推廣。
2、Consumer 限流。在一寫多讀場景中, 如果某一個 Consumer 操作大量讀磁盤, 會影響 Produce 級其他消費者操作的延遲。l因此,通過 Kafka Quota 機制對 Consume 限流及支持動態調整閾值也是我們后續的方向
3、場景擴展。基于 Kafka 擴展 SDK、HTTP 等多種消息訂閱及生產方式,滿足不同語言環境及場景的使用需求。
以上就是關于 Kafka 在馬蜂窩大數據平臺應用實踐的分享,如果大家有什么建議或者問題,歡迎在后臺留言。
作者丨畢博來源丨馬蜂窩技術(ID:mfwtech)dbaplus社群歡迎廣大技術人員投稿,投稿郵箱:editor@dbaplus.cn近年來大數據技術發展迅速,并且不斷推陳出新來適應新時代的海量數據處理需求。但隨著技術的更迭,每次演進都需要耗費大量人員的精力與時間,以往的數據治理模式已經搖搖欲墜,此時DataOps應運而生。來和Gdevops全球敏捷運維峰會北京站一起看看聯通大數據背后的DataOps體系建設:
《數據智能時代:構建能力開放的運營商大數據DataOps體系》中國聯通大數據基礎平臺負責人/資深架構師 尹正軍
本次研究目標是讓大家了解聯通大數據背后的DataOps平臺整體架構演進,包括數據采集交換加工過程、數據治理體系、數據安全管控、能力開放平臺運營和大規模集群治理等核心實踐內容。那么2020年5月29日,我們在北京不見不散。

版权声明:本站所有资料均为网友推荐收集整理而来,仅供学习和研究交流使用。

工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态