windows7 +2.7.5
我的源代碼:
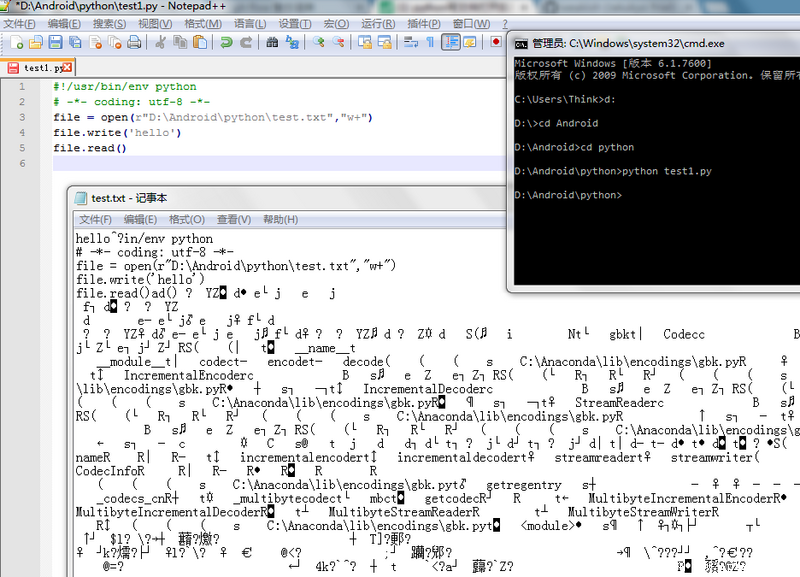
#!/usr/bin/env python
python循環寫入excel。# -*- coding: utf-8 -*-
file = open(r"D:\Android\python\test.txt","w+")
file.write('hello')
file.read()
python運行出現亂碼、python test1.py后,用記事本打開文件顯示亂碼,請問這是怎么回事啊?
Windows下的編碼是個大坑,別用記事本了,換nodepad++吧。
請特別閱讀 @依云 的答案。分析上游代碼和文檔,這才是真正堅不可摧的力量。
同仁們,誤入歧途了啊!!!別在ASCII的文件上這么深入的追究編碼問題啊!!!
python向excel寫入數據、我試了一下,果然爽翻:#!/usr/bin/env python
# -*- coding: utf-8 -*-
f = open(r"C:\Users\776\test.txt","w+")
# 注:w+ truncates the file - 因此文件無論存在與否,結果一致
python文件寫入亂碼,f.write('hello')
print(f.read())
f.close()
# 結果不貼了,同樣不忍直視,傳送門:http://paste.openstack.org/show/61806/
python寫入excel。我沒有深入的究其原因,不過大概能猜到理由是什么:文件的指針位置。
open()以w+模式開啟了一個讀寫模式的文件,由于是w,所以文件被廢棄清空(truncate),此時的文件內容為[EOF],開啟時的指針為0。此時如果做read(),則Python發現指針位置就是EOF,讀取到空字符串。
在寫入hello之后,指針的位置是5,文件在內存中是hello[EOF]。
但看起來read()的時候,Python仍然去試圖在磁盤的文件上,將指針從文件頭向后跳5,再去讀取到EOF為止。
也就是說,你實際上是跳過了該文件真正的EOF,為硬盤底層的數據做了一個dump,一直dump到了一個從前文件的[EOF]為止。所以最后得到了一些根本不期待的隨機亂字符(這里根本不是編碼問題造成的亂碼!)。
(看起來似乎還暴露了一些以前文件的內容呢,C:\Anaconda\神馬的 :D)
解決這個問題,你需要在讀文件之前,用file對象的flush()方法,將已修改的文件內容可靠寫盤:#!/usr/bin/env python
# -*- coding: utf-8 -*-
f = open(r"C:\Users\776\test.txt","w+")
# 注:w+ truncates the file - 因此文件無論存在與否,結果一致
f.write('hello') # 此時指針=5,內存內容=`hello[EOF]`
f.flush() # 此時硬盤內容=`hello[EOF]`
print(f.read()) # 此時指針=5,正好在[EOF]上,正確輸出''
f.seek(0) # 指針歸0
print(f.read()) # 正確從頭讀出全部內容'hello'
f.close()
這并不是完美的解決方法,因為我總覺得flush()應該是真正決定寫盤之前才做的,而不是read()一次就flush()一次。read()似乎還是優先讀取內存緩沖區更有道理。
但總之至少猜測到了一個原因,并一定程度解決問題,更好的方法有待補充吧?
亂碼應該是報錯信息,讀文件之前先打開,最后還最好要 close
試試下面這個#!/usr/bin/env python
# -*- coding: utf-8 -*-
file = open(r"D:\Android\python\test.txt","w+")
file.write('hello')
file = open("D:\Android\python\test.txt")
file.read()
file文件的讀寫,一定要注意,在寫完之后,必須要seek(0),把文件指針重新指向文件開頭,然后再讀,否則就會從緩沖區讀取一大堆亂碼——順便,這是不是一個潛在的緩沖區溢出漏洞啊。
更新:
我在路上就在想,這么底層的一個特性,為什么 Python 沒有為程序員處理掉呢?都用 Python 了,誰會為了那么大的便利犧牲一丁點性能呢?一回來我就做了測試。
經測試,Python 2.7.5 on Windows XP 重現此情況,Python 3.3.2 on Windows XP 沒有重現。這說明 Python 2 確實該換了!
再次更新:
找到原因之后我就覺得這問題在哪里見過,今天終于找出來了, python-cn 郵件列表里討論過的。
真正的答案來啦~~我在 MSDN 里找得好苦哦 QAQ
真正的原因不在于 Python 怎么樣了,而在于 Windows 怎么樣了。經查源碼(Python 2.7.6)Objects/fileobject.c:2837,Python 是使用 fopen/fread/fwrite 這系列函數來讀寫文件的。MSDN 說:
所以會有 @沙渺 發現添加 flush() 調用后正確的結果。
Linux 下沒有重現。man 3 fopen 說:
所以 Windows 的這種行為是符合 ANSI C 標準的,但是 Linux 并不(總是)需要這樣做。(并且,跨平臺的方案是使用文件定位函數而不是 fflush()。)
玩蛇網文章,轉載請注明出處和文章網址:https://www.iplaypy.com/wenda/wd19887.html
相關文章 Recommend
版权声明:本站所有资料均为网友推荐收集整理而来,仅供学习和研究交流使用。

工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态