项目实现:主要获得通识选修、个性选课、英语体育选课的课程信息
python网络爬虫与信息提取?核心:
1、实现网页登陆
2、爬取课程信息
from selenium import webdriver
import os
import time
import json
import csv
import pandas as pd
def Login():Name = "*****"Password = "*****"# 输入账号time.sleep(4)driver.find_element_by_id("username").send_keys(Name)# 输入密码driver.find_element_by_id("password").send_keys(Password)time.sleep(4)# 点击登录按钮driver.find_element_by_id("submit_id").click()time.sleep(4)# 打开谷歌浏览器
driver = webdriver.Chrome()
url = 'http://sso.jwc.whut.edu.cn/Certification/toIndex.do'driver.get(url)
Login()
time.sleep(5)
driver.get("http://*******/Course")
time.sleep(15)
print("sucess login")
def saveinfotofile(infos,csvpath):with open(csvpath,"w") as csvfile:writer = csv.writer(csvfile)writer.writerow(["课程名称","上课老师","上课时间","上课地点","容量","选上","本轮已选","任务类型","学分","备注","双语"])for info in infos:writer.writerows(info)print("当前课程信息保存成果")
def getCourseInfo(iindex):print("whutjwc爬虫开始....")## 获得选课的按钮xuanke = driver.find_elements_by_xpath('//*[@id="sidebar"]/div[2]/div[2]/ul/li')courseName = xuanke[iindex]## 文件保存的路径 courseName.textfilepath = "./result/" + courseName.text + ".csv"print("当前爬取的课程类型:" + courseName.text)## 展开课程大类的信息courseName.click()time.sleep(5)## 得到该课程下的所有大类课程courseButtons = driver.find_elements_by_xpath('//*[@id="navTab"]/div[2]/div[2]/div/div/div[1]/ul/li')## plusplus所有课程信息courseinfoplus = []## 进入课程类别for button in courseButtons:time.sleep(2)## 展开大类课程button.click()time.sleep(5)## 找到当前大类下的所有课程courses = button.find_elements_by_tag_name('li')print("开始爬取 " + button.text[:4] + " 下的课程信息...")## plus保存当前大类下的所有课程信息courseinfo = []for course in courses:## 点击进入课程详情course.click()time.sleep(5)## 获取当前课程开课情况1-5coursetr = course.find_elements_by_xpath('//*[@id="gxkxk_wxkc_tb"]/tbody/tr')## 保存该课程的课程信息for coursetd in coursetr:coursetd = coursetd.find_elements_by_tag_name("td")## 保存具体的课程信息infodet=[]for index in range(1,12):infodet.append(coursetd[index].text)courseinfo.append(infodet)print("当前爬取课程: "+ infodet[0])courseinfoplus.append(courseinfo)## 保存课程信息saveinfotofile(courseinfoplus,filepath)## 返回到课程模块板块back = driver.find_elements_by_xpath('//*[@id="sidebar_s"]/div/div')back[0].click()print("课程数据爬取结束.....")通过课程类型的索引爬取相关的课程信息
## 通识选修课程索引2 个性课索引3 英语专业选课索引7
getCourseInfo(2)
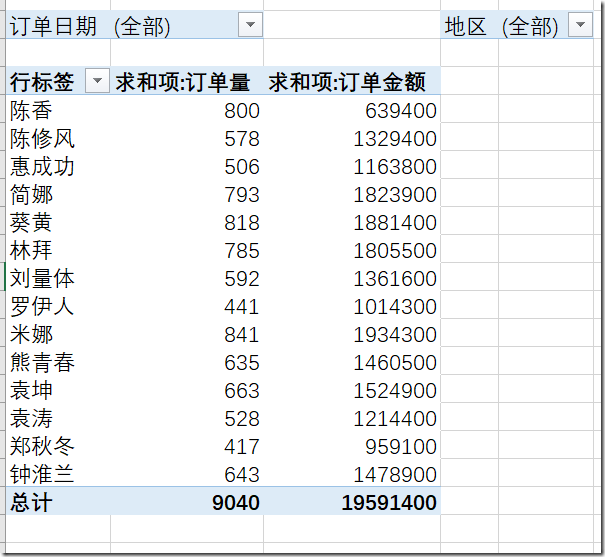
爬虫可以做什么项目?查看爬取得数据
datacourse = pd.read_csv("./result/通识选修课选课.csv",header=0)
datacourse
driver.quit()


高级爬虫速成课程、以上可以爬取学校教务系统的课程信息,将爬取得过程简单总结一下。
版权声明:本站所有资料均为网友推荐收集整理而来,仅供学习和研究交流使用。

工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态





![[20170508]listagg拼接显示字段.txt](/upload/rand_pic/2-429.jpg)