sql 鍵查找 索引查找
數據庫謂詞是什么? It is common assumption that an Index Seek operation in a query plan is optimal when returning a low number of output rows. In a scenario involving residual predicates, an Index Seek operation could be reading a lot more rows than it needs into the memory, then each row is evaluated and discarded in memory based on the residual predicate and returns low number of output rows.
通常假設在返回少量輸出行時查詢計劃中的索引查找操作是最佳的。 在涉及殘留謂詞的場景中,索引查找操作可能會向內存中讀取比其所需數量更多的行,然后,根據殘留謂詞對每一行進行評估并丟棄到內存中,并返回少量的輸出行。
sqlserver刪除索引的sql語句? This article will explain the concept and the impact of Residual Predicates in a SQL Server Index Seek operation.
本文將解釋SQL Server索引查找操作中殘留謂詞的概念和影響。
SQL Server accesses a table or an index via the mean of a lookup, scan or a seek operation. In an index seek operation, a Seek Predicate is when SQL Server is able to get the exact filtered result. In the case of an index seek on multi-column, SQL Server may introduce a Predicate in the Index Seek operation. This Predicate is often referred as residual predicate because SQL Server performs additional filtering on the resultset from the index seek operation.
SQL Server通過查找,掃描或查找操作的方式訪問表或索引。 在索引查找操作中,“查找謂詞”是指SQL Server能夠獲得準確的篩選結果。 在多列上進行索引查找的情況下,SQL Server可能在索引查找操作中引入謂詞。 該謂詞通常稱為殘差謂詞,因為SQL Server對來自索引查找操作的結果集執行附加篩選。
To understand the behaviour of residual predicate in SQL Server, we will walk-through two scenarios
若要了解殘留謂詞在SQL Server中的行為,我們將演練兩種情況
The scenarios will utilize WideWorldImportersDW database on SQL Server 2016 Developer Edition Service Pack 1.
這些方案將利用SQL Server 2016 Developer Edition Service Pack 1上的WideWorldImportersDW數據庫。
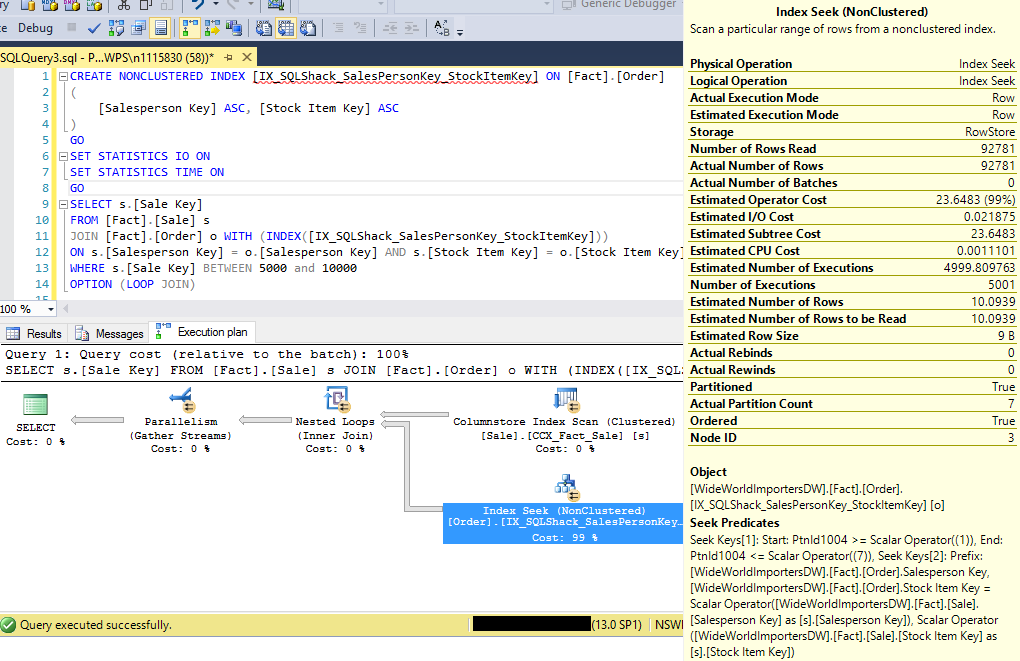
This scenario will walkthrough a common index seek predicate operation. First, we will create a non-clustered index on [Fact].[Order] table as below
此場景將演練通用索引查找謂詞操作。 首先,我們將在[Fact]。[Order]表上創建一個非聚集索引,如下所示
?
USE WideWorldImportersDW
GO
CREATE NONCLUSTERED INDEX IX_SQLShack_StockItemKey ON [Fact].[Order] ([Salesperson Key])
INCLUDE ([Stock Item Key])We will now execute the query below and look at the query plan and the I/O statistics
現在,我們將在下面執行查詢,并查看查詢計劃和I / O統計信息
A total of 2,585 rows returned and the logical reads incurred are 22 reads.
總共返回了2585行,并且發生的邏輯讀取是22次讀取。
We need to pay attention to a new SQL Server XML attribute Number of Rows Read in the query plan which was introduced in the SQL Server Service Pack level listed below to diagnose query plan which involved predicate pushdown.
我們需要注意查詢計劃中新SQL Server XML屬性“已讀取行數” ,該屬性在下面列出SQL Server Service Pack級別中引入,用于診斷涉及謂詞下推的查詢計劃。
The XML attribute will not appear your query plan if the service pack level is lower than the list above or on a SQL Server version lower than SQL Server 2012.
如果Service Pack級別低于上面的列表或SQL Server版本低于SQL Server 2012,則XML屬性將不會出現在您的查詢計劃中。
Estimated Number of Rows to be Read is another new XML attributed introduced in SQL Server 2016 Service Pack 1. But to diagnose query plan with residual predicate, this article will focus on the XML attribute Number of Rows Read.
預計要讀取的行數是SQL Server 2016 Service Pack 1中引入的另一個新XML屬性。但是,為了診斷帶有殘留謂詞的查詢計劃,本文將重點介紹XML屬性“已讀取行數” 。
| XML attribute | Description |
| Number of Rows Read (**New) | Number of actual rows accessed by SQL Server. In this example, SQL Server read 2,585 rows |
| Actual Number of Rows | Number of rows output from the index seek operation. In the example, all the 2,585 rows satisfies the condition in the index seek |
| XML屬性 | 描述 |
| 讀取的行數(**新) | SQL Server訪問的實際行數。 在此的示例SQL Server讀取2,585行 |
| 實際行數 | 索引查找操作輸出的行數。 在該示例中,所有2,585行都滿足索引查找中的條件 |
In this scenario where there is no residual predicate, the Index Seek operator properties shows that SQL Server reads and outputs the same number of rows. It means that SQL Server only reads the rows that it requires and spool the rows to the next operator.
在沒有剩余謂詞的這種情況下,“索引查找”運算符屬性顯示SQL Server讀取并輸出相同數量的行。 這意味著SQL Server僅讀取其所需的行,并將其后臺處理到下一個運算符。
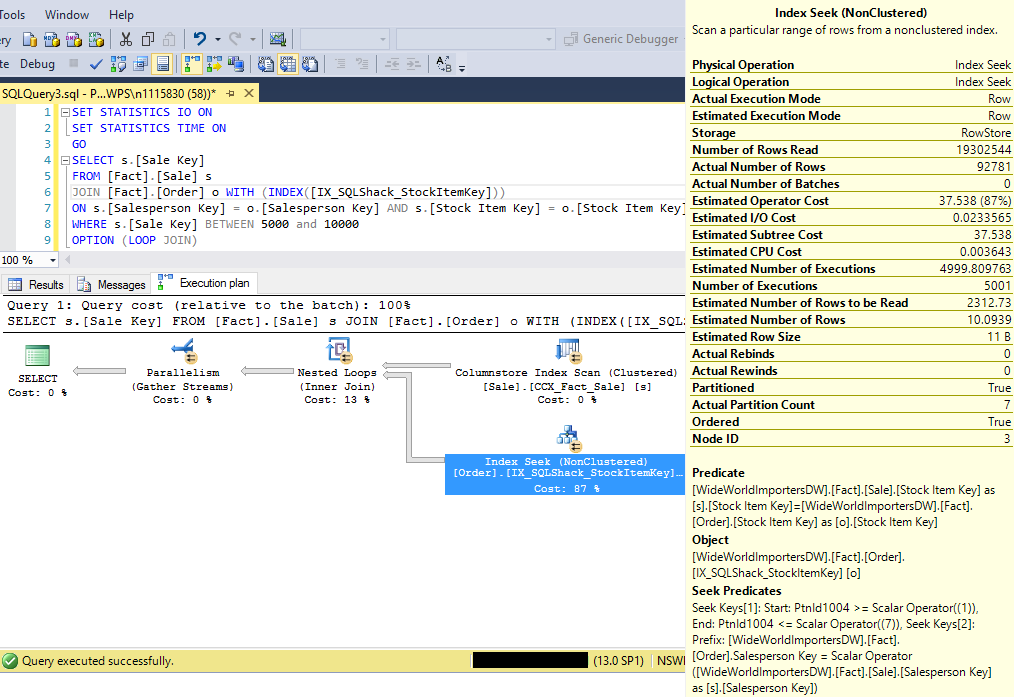
The first scenario is an Index Seek with Seek Predicates. We will now modify the query slightly and introduce a second predicate on column [Stock Item Key] into the query. Since this column is an included column in the index definition IX_SQLShack_StockItemKey, SQL Server would still be able to perform an index seek on the same non-clustered index.
第一種情況是帶有搜索謂詞的索引搜索。 現在,我們將稍微修改查詢,并在查詢中的[Stock Item Key]列上引入第二個謂詞。 由于此列是索引定義IX_SQLShack_StockItemKey中的包含列,因此SQL Server仍將能夠對同一非聚集索引執行索引查找。
The query plan looks the same as before and the logical reads incurred are still 22 reads. The query returns 13 rows, but the statistics I/O reads is same as if 2,585 rows were read.
查詢計劃看起來與以前相同,并且發生的邏輯讀取仍然是22個讀取。 該查詢返回13行,但是統計信息I / O讀取與讀取2585行相同。
Looking at the Index Seek operator properties, SQL Server read 2,585 rows (indicated by the new XML attribute Actual Number of Rows), then performs a filtering based on the Predicate ([Stock Item Key] = 173) and the actual rows spooled to the next operator is only 13 rows (indicated by the Actual Number of Rows).
查看“索引查找”運算符屬性,SQL Server讀取2,585行(由新的XML屬性“ 實際行數”表示 ),然后根據謂詞([Stock Item Key] = 173)和后臺處理的實際行執行篩選。 next運算符只有13行(由實際行數指示)。
We can learn a bit more about residual predicate behaviour using an undocumented trace flag 9130. Before SQL Server introduced Number of Rows Read attribute, trace flag 9130 is the workaround to troubleshoot queries which contains residual predicate.
我們可以使用未記錄的跟蹤標志9130了解有關殘余謂詞行為的更多信息。在SQL Server引入“讀取的行數”屬性之前,跟蹤標志9130是解決包含殘余謂詞的查詢的變通方法。
We will use the trace flag as a query option as below.
如下所示,我們將使用跟蹤標志作為查詢選項。
What the trace flag shows us is that SQL Server first reads all the 2,585 rows into memory, then evaluate each row and discard rows which do not satisfy the condition in the Filter operator based on the second predicate. This explains why the same I/O reads were incurred by both queries in the two scenarios.
跟蹤標志向我們顯示的是SQL Server首先將所有2,585行讀取到內存中,然后評估第二行并基于第二個謂詞丟棄不滿足Filter運算符中條件的行。 這就解釋了為什么在兩種情況下兩個查詢都會產生相同的I / O讀取。
We now move on to an example to compare the query performance of an Index Seek with and without residual.
現在我們來看一個示例,比較帶有和不帶有殘差的索引搜索的查詢性能。
We will use the query below as an example. One of the reasons to use query hint LOOP JOIN is the ease in demonstrating a scenario where residual predicate can really hurt query performance.
我們將使用以下查詢作為示例。 使用查詢提示LOOP JOIN的原因之一是很容易地說明殘余謂詞確實會損害查詢性能的情況。
The query incurred 127,851 logical reads on [Fact].[Order] table and took almost 3 seconds to complete execution. The Index Seek properties indicate that SQL Server read over 19 million rows into memory, but really only requires 92,781 rows.
該查詢對[Fact]。[Order]表進行了127,851次邏輯讀取,并花費了近3秒鐘來完成執行。 索引查找屬性指示SQL Server將超過1900萬行讀入內存,但實際上僅需要92,781行。
We will now create another index definition and forces the query to use this index instead.
現在,我們將創建另一個索引定義,并強制查詢使用該索引。
This query incurred 40,332 logical reads on [Fact].[Order] table and took less than half second to complete execution. This query is 6 times faster without residual. In this scenario, SQL Server pushes the filter down to the table access operator itself and only read exactly 98,781 rows that it needs.
該查詢在[Fact]。[Order]表上進行了40,332個邏輯讀取,并且不到半秒即可完成執行。 此查詢速度快了6倍,沒有殘留。 在這種情況下,SQL Server將篩選器下推到表訪問運算符本身,并且僅準確讀取它需要的98,781行。
Predicate pushdown is important because you would want SQL Server to filter the results as early as possible in the query plan. The more rows that SQL Server operator has to access, the longer the operation will take.
謂詞下推很重要,因為您希望SQL Server在查詢計劃中盡早篩選結果。 SQL Server操作員必須訪問的行越多,操作所需的時間就越長。
A Residual predicate scenario can occur in many forms and scenarios other than the examples in this article. Understanding the behaviour of residual predicates will allow better analysis in relation to performance tuning and troubleshooting.
除本文中的示例以外,殘留謂詞方案可以多種形式出現。 了解殘差謂詞的行為將允許在性能調整和故障排除方面進行更好的分析。
In addition, SQL Server now has introduced new XML attributes to better diagnose query plans that involve residual predicate pushdown.
此外,SQL Server現在引入了新的XML屬性,以更好地診斷涉及殘留謂詞下推的查詢計劃。
翻譯自: https://www.sqlshack.com/the-impact-of-residual-predicates-in-a-sql-server-index-seek-operation/
sql 鍵查找 索引查找
版权声明:本站所有资料均为网友推荐收集整理而来,仅供学习和研究交流使用。

工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态











{kind=link}
{kind=link}