1 需要換新盤的情況
1.1 一塊盤grub損壞修復(可通過另一塊盤進入系統的情況)
更換硬盤的方式,可以熱插拔,也可以服務器斷電后更換,但如果是熱插拔,可能會導致盤符變更。壞了一塊硬盤的情況下,軟raid1恢復方法(以sdb為新更換的硬盤為例):
1.1.1 拷貝正常的那塊硬盤分區信息到新的硬盤
sfdisk -d /dev/sda | sfdisk -f /dev/sdb
1.1.2 查看sdb的分區與sda是否一致
[root@HN-SS1 ~]# fdisk -l /dev/sdb
Disk /dev/sdb: 300.0 GB, 300000000000 bytes
255 heads, 63 sectors/track, 36472 cylinders
Units = cylinders of 16065 * 512 = 8225280 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk identifier: 0x00000000
Device Boot ?????Start ????????End ?????Blocks ??Id ?System
/dev/sdb1 ??????????????1 ????????523 ????4194304 ??82 ?Linux swap / Solaris
Partition 1 does not end on cylinder boundary.
/dev/sdb2 ??* ????????523 ??????36473 ??288773120 ??fd ?Linux raid autodetect
[root@HN-SS1 ~]# fdisk -l /dev/sda
Disk /dev/sda: 300.0 GB, 300000000000 bytes
255 heads, 63 sectors/track, 36472 cylinders
Units = cylinders of 16065 * 512 = 8225280 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk identifier: 0x000dafc6
Device Boot ?????Start ????????End ?????Blocks ??Id ?System
/dev/sda1 ??????????????1 ????????523 ????4194304 ??82 ?Linux swap / Solaris
Partition 1 does not end on cylinder boundary.
/dev/sda2 ??* ????????523 ??????36473 ??288773120 ??fd ?Linux raid autodetect
1.1.3 讓內核重載分區表(若可以重啟服務器不需執行此部)
partprobe /dev/sdb
1.1.4 把第二塊盤加入raid1中
mdadm /dev/md0 -a /dev/sdb2
等數據同步到SDB 完成之后執行
1.1.5 復制操作系統的前512字節的引導程序到新的硬盤
(最關鍵一步,否則開機無法正常引導,現場軟raid同步后沒法啟動就是這個原因)
dd if=/dev/sda of=/dev/sdb bs=512 count=1
ps:硬盤上第0磁道第一個扇區被稱為MBR,也就是Master Boot Record,即主引導記錄,它的大小是512字節,里面卻存放了預啟動信息、分區表信息。
系統找到BIOS所指定的硬盤的MBR后,就會將其復制到0×7c00地址所在的物理內存中。被復制到物理內存的內容就是Boot Loader,即grub。
1.1.6 添加新盤swap
mkswap
/dev/sdb1
swapon
/dev/sdb1
上面命令只在未重啟時生效
1.1.7 修改fstab中已經被換掉的硬盤的UUID為新swap的UUID,保證swap重啟服務器可以生效
cat
/etc/fstab
UUID可通過blkid查看
1.2 兩塊盤grub均損壞(無法進入系統)
有一些之前已經換過系統盤,沒有按照上面的操作,然后另一塊也壞了,此時兩塊硬盤都沒法進入系統,采用如下方法:
掛載光盤,進應急模式修復
Bash-4.1# chroot /mnt/sysimage
Sh-4.1# grub
Grub > root (hd0,1)
Grub> setup (hd0)
Grub> quit
Sh-4.1# exit
Bash-4.1# reboot
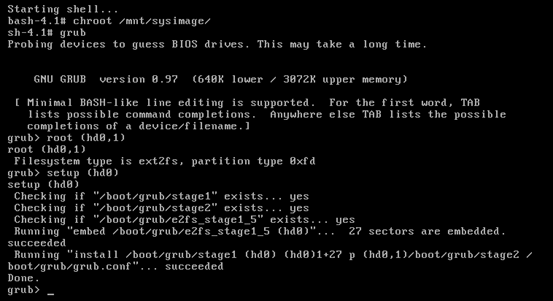
成功

2 不換盤
現場存在硬盤沒問題,但是掉raid的情況(大部分是這種情況)
檢測方法
2.1 檢查硬盤的是否正常
2.1.1 smartctl -a /dev/sdb

注意上面得輸出,標注位置沒有錯誤,表示硬盤沒問題
2.1.2
smartctl -H /dev/sdb(一般用這個查就可以了),health為ok即表示硬盤沒問題

2.1.3 badblocks -sv /dev/sdb
全盤掃,很慢,不建議
2.2若硬盤沒問題,重新同步即可
2.2.1 檢查raid狀態
[root@GD-QY1-BY1-SE3 fonsview]# mdadm -D /dev/md0
/dev/md0:
Version : 1.0
Creation Time : Tue Apr 29 15:19:50 2014
Raid Level : raid1
Array Size : 288772984 (275.40 GiB 295.70 GB)
Used Dev Size : 288772984 (275.40 GiB 295.70 GB)
Raid Devices : 2
Total Devices : 2
Persistence
: Superblock is persistent
Intent Bitmap : Internal
Update Time : Mon Jul? 4 15:05:56
2016
State : active, degraded
Active Devices : 1
Working Devices : 1
Failed Devices : 1
Spare Devices : 0
Name : example.sz.fonsview.com:0
UUID : 8c78cdee:b6be167c:85cce8f9:9e2fe8e8
Events : 26915749
Number?? Major?? Minor
RaidDevice State
0?????? 0??????? 0
0????? removed
1?????? 8?????? 18
1????? active sync?? /dev/sdb2
0?????? 8??????? 2
-????? faulty
spare?? /dev/sda2
若紅色字體部分為faulty,執行:
mdadm /dev/md0 -r /dev/sdb
mdadm /dev/md0? -a /dev/sda2
若紅色字體部分為remove,執行:
mdadm /dev/md0? -a /dev/sda2
2.2.1 查看同步狀態
cat /proc/mdstat
版权声明:本站所有资料均为网友推荐收集整理而来,仅供学习和研究交流使用。

工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态






![[vijos1162]波浪数](https://images.cnblogs.com/OutliningIndicators/ContractedBlock.gif)
