我們分別通過Golang、Python、Java三門語言,分別實現對Boss直聘網站的招聘數據進行爬取。
首先打開Boss直聘網站:
然后我們在職位類型中輸入Go或者Golang關鍵字:
網絡爬蟲抓取個人信息、
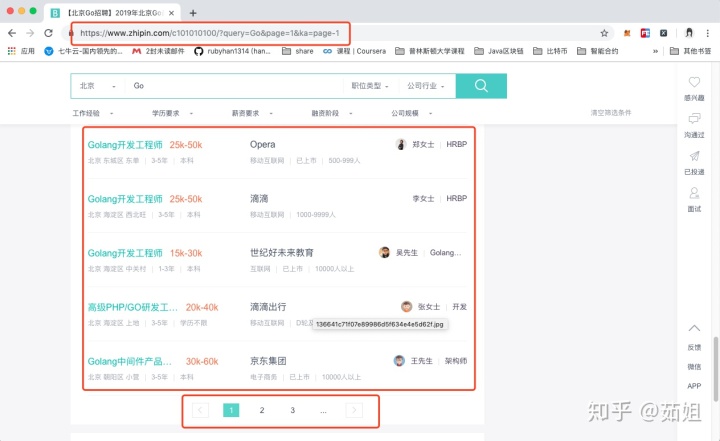
然后我們可以看到一個列表,和Go語言相關的各種招聘職位,還可以不停的下一頁。。
那我們現在就來爬取這些數據:我們比較關心這里的職位名稱,薪資待遇,工作地點,對于工作經驗的要求,學歷的要求,公司名稱,公司類型,公司發展階段,公司規模等等。。
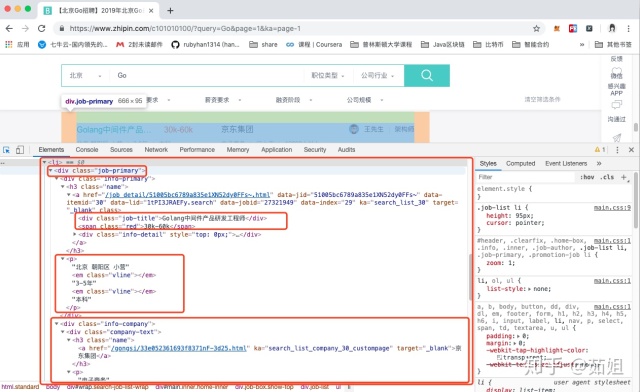
我們通過分析頁面的結構發現,頁面的職位列表,其實都位于一個ul中的li里,每個頁面有30個職位,所以有30個li標簽:
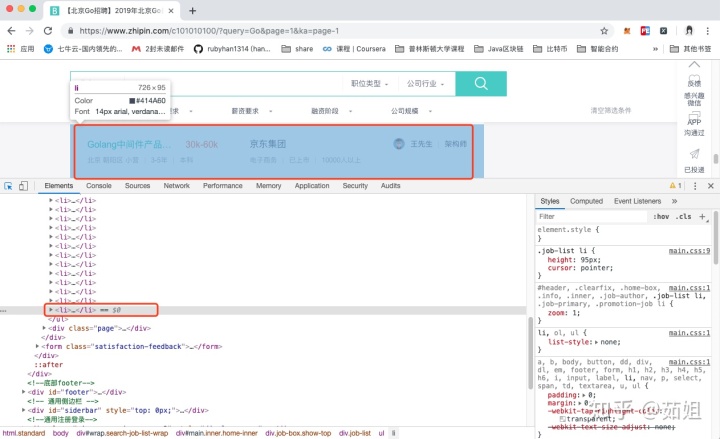
打開這個li標簽后,里面是div標簽嵌套,包括了招聘信息和公司信息:
java可以寫爬蟲嗎?
接下來我們就可以通過代碼來爬取這些數據了,首先我們要確定要爬取的第一個url:
https://www.zhipin.com/c101010100/?query=Go&page=1
一共有10頁數據,分別通過page=1、2、3。。。來實現,
所以接下來要爬取的url:
https://www.zhipin.com/c101010100/?query=Go&page=2
java爬蟲是什么。https://www.zhipin.com/c101010100/?query=Go&page=3
。。。
https://www.zhipin.com/c101010100/?query=Go&page=10
爬取到的數據,我們也不需要處理,打印輸出即可。。因為我們只是想看一下幾門語言爬取數據在實現上有什么不同。。
好了,現在讓我們來開開心心的擼代碼吧。。
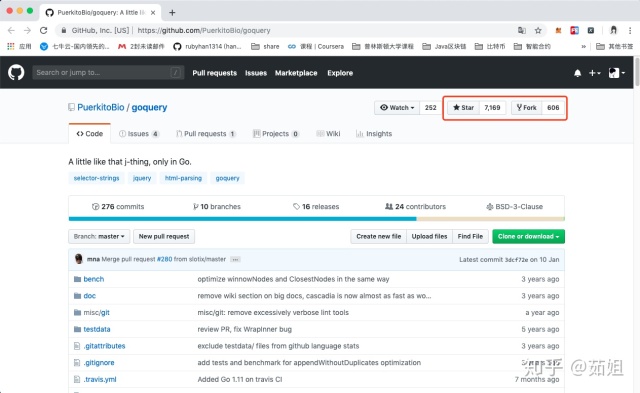
使用Go語言來爬取這個頁面,github里搜了下,發現goquery這個爬蟲包用的人還挺多的,7000多個star,而且是BSD開源協議,于是毫不猶豫的拿來用了。
python爬蟲教程、
goquery的使用還是比較簡單,按照文檔說明一步一步來就可以了:
首先:需要安裝
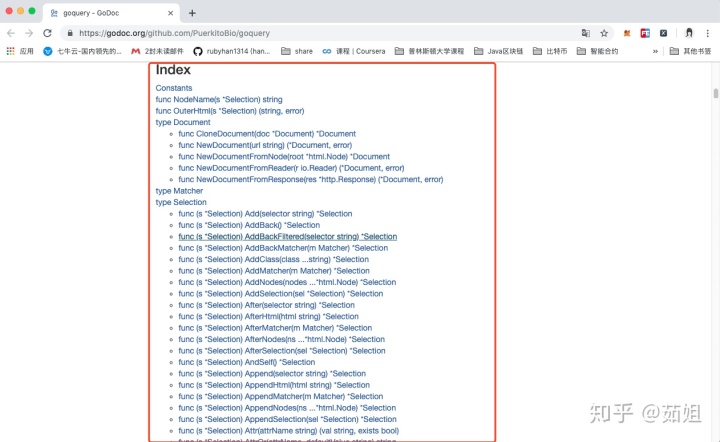
localhost:~ ruby$ go get github.com/PuerkitoBio/goquery其次:就是去看看goquery的API,先了解一下常用的方法:
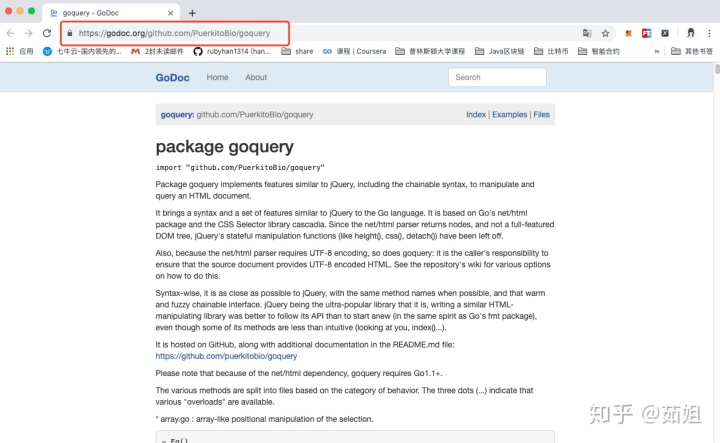
https://godoc.org/github.com/PuerkitoBio/goquery
javascript爬取網頁數據?
然后就可以開始寫代碼了:
打開Goland,新建一個go文件:
package 一共也就這些代碼,加上注釋78行。
然后可以運行:(注:由于執行結果過長,為增加可閱讀性部分執行結果已經刪除處理)
GOROOT=/usr/local/go #gosetup
GOPATH=/Users/ruby/go #gosetup
/usr/local/go/bin/go build -i -o /private/var/folders/kt/nlhsnpgn6lgd_q16f8j83sbh0000gn/T/___go_build_boss_go /Users/ruby/go/src/boss/boss.go #gosetup
/private/var/folders/kt/nlhsnpgn6lgd_q16f8j83sbh0000gn/T/___go_build_boss_go #gosetup
============== 千鋒教育Go語言開發教學部 職位信息分析 ================
第 0 頁的數據:
職位序號:第1個職位
職位名稱:Golang
職位薪酬:25k-50k
工作地點:北京
職位所需工作經歷:5-10年
學歷要求:本科
公司名稱:京東集團
公司類型:電子商務
公司發展階段:已上市
公司規模:10000人以上
================================================================職位序號:第2個職位
職位名稱:Golang
職位薪酬:20k-35k
工作地點:北京 朝陽區 亮馬橋
職位所需工作經歷:3-5年
學歷要求:本科
公司名稱:平安科技
公司類型:互聯網
公司發展階段:不需要融資
公司規模:1000-9999人
================================================================職位序號:第3個職位
職位名稱:Golang
職位薪酬:20k-30k
工作地點:北京 海淀區 知春路
職位所需工作經歷:3-5年
學歷要求:本科
公司名稱:騰訊科技(北京)公司
公司類型:移動互聯網
公司發展階段:已上市
公司規模:10000人以上
================================================================職位序號:第4個職位
職位名稱:Golang
職位薪酬:20k-40k
工作地點:北京 海淀區 中關村
職位所需工作經歷:3-5年
學歷要求:本科
公司名稱:曠視科技
公司類型:移動互聯網
公司發展階段:C輪
公司規模:1000-9999人
================================================================職位序號:第5個職位
職位名稱:Golang
職位薪酬:20k-40k
工作地點:北京 海淀區 上地
職位所需工作經歷:3-5年
學歷要求:本科
公司名稱:Aibee
公司類型:互聯網
公司發展階段:A輪
公司規模:100-499人
================================================================
.
省略
.
注:由于執行結果過長,為增加可閱讀性部分執行結果已經刪除處理
.
省略
.
================================================================
職位序號:第25個職位
職位名稱:Golang
職位薪酬:20k-35k
工作地點:北京 海淀區 上地
職位所需工作經歷:3-5年
學歷要求:本科
公司名稱:滴滴出行
公司類型:移動互聯網
公司發展階段:D輪及以上
公司規模:1000-9999人
================================================================職位序號:第26個職位
職位名稱:高級軟件工程師(Golang)
職位薪酬:30k-50k
工作地點:北京 海淀區 五道口
職位所需工作經歷:3-5年
學歷要求:學歷不限
公司名稱:魔門塔科技
公司類型:計算機軟件
公司發展階段:B輪
公司規模:500-999人
================================================================職位序號:第27個職位
職位名稱:京東云golang后端開發工程師
職位薪酬:20k-40k
工作地點:北京 朝陽區 小營
職位所需工作經歷:5-10年
學歷要求:本科
公司名稱:京東集團
公司類型:電子商務
公司發展階段:已上市
公司規模:10000人以上
================================================================職位序號:第28個職位
職位名稱:Golang開發工程師
職位薪酬:15k-25k
工作地點:北京 海淀區 航天橋
職位所需工作經歷:1-3年
學歷要求:本科
公司名稱:央視網
公司類型:互聯網
公司發展階段:不需要融資
公司規模:1000-9999人
================================================================職位序號:第29個職位
職位名稱:Golang開發工程師
職位薪酬:5k-9k
工作地點:北京 海淀區 大鐘寺
職位所需工作經歷:1年以內
學歷要求:本科
公司名稱:卿燁科技
公司類型:互聯網
公司發展階段:A輪
公司規模:100-499人
================================================================職位序號:第30個職位
職位名稱:Golang開發工程師
職位薪酬:30k-60k
工作地點:北京 海淀區 萬柳
職位所需工作經歷:3-5年
學歷要求:本科
公司名稱:費曼咨詢
公司類型:互聯網
公司發展階段:未融資
公司規模:0-20人
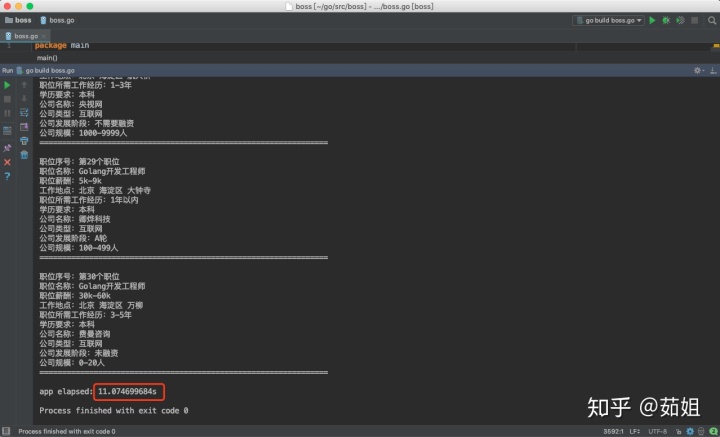
================================================================app elapsed: 11.074699684sProcess finished with exit code 0
我們可以看到一共花費了11s的時間,但是我們為了防止boss反爬,在程序中設置了,每隔1s中再爬取下個頁面,所以減掉9s,真正的爬數據的時間也就2s:
java抓取網頁數據。
python在爬蟲方面還是比較強大的,我選了一個最時髦的框架:scrapy
這個框架雖然說功能很強大,但是用起來還稍微有點麻煩的,不說別的,創建項目就得用終端的scrapy命令創建,而不是IDE直接創建。
所以打開終端,進入python的workspace,輸入以下命令:
localhost:~ ruby$ scrapy startproject bossspider然后通過Pycharm打開這個項目:
先編寫items.py文件,就是我們要爬取的數據,需要先在此處定義,然后每一條數據就是一個item:
# -*- coding: utf-8 -*-
java爬取數據?然后我們打開spiders目錄:新建一個py文件:bossspider.py,這里寫爬取數據的代碼:
# -*- coding: utf-8 -*-
然后修改setting.py文件,設置請求頭等等:
# -*- coding: utf-8 -*-
為了能夠在爬取數據的時候,統計程序耗時,我們還可以修改scrapy的包文件:corestats.py
def 然后運行一下程序,打開終端,輸入以下命令:
hanru-3:bossspider ruby$ scrapy crawl bossspider或者:
hanru-3:bossspider ruby$ scrapy crawl bossspider -o boss.json表示把爬取的數據導出到boss.json文件中。
爬蟲數據抓取。
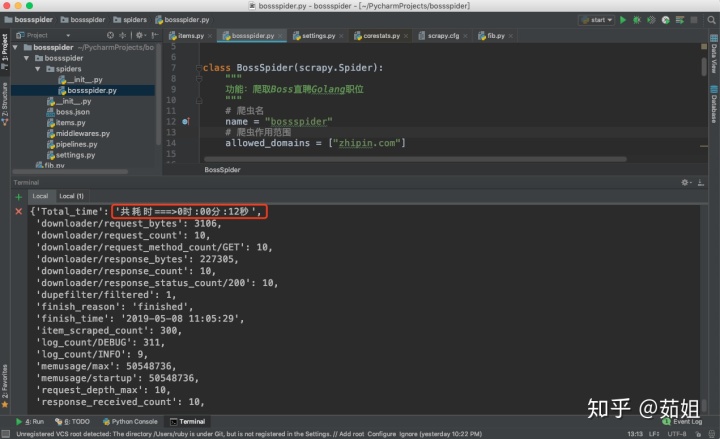
共耗時12s,同樣也是減掉9s的睡眠時間,耗時3s。
Java的爬蟲,我們可以通過Jsoup庫來輔助我們實現Java語言的編程實現)。
先創建Java工程,然后下載Jsoup.jar源碼庫并添加到Java工程中的libs中,并添加成為library。
接著創建Item類,因為Java是面向對象的語言,所以我們先創建一個類,用于封裝下載后的數據:
package 然后我們創建一個帶main()的java文件,來編寫爬蟲的代碼:
package java實現爬蟲。因為我們對數據沒有什么處理,所以邊封裝就邊打印查看了。
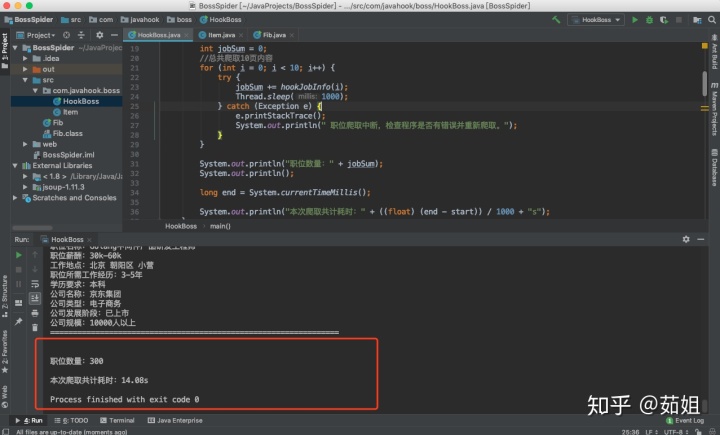
這個速度還是有點意思的。。
從代碼量上可以看得出來Go語言是最少的,尤其的簡潔。。
從運行速度上可以看出來Go語言是執行最快的,耗時最短。。
然后每個語言也都有著不同的優缺點,所以也有著各自的發展領域。
版权声明:本站所有资料均为网友推荐收集整理而来,仅供学习和研究交流使用。

工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态