今天為大家介紹如何將自己喜歡的公眾號的歷史文章轉成 PDF 保存到本地。前幾天還有朋友再問,能不能幫把某某公眾號的文章下載下來,因為他很喜歡這個號的文章,但由于微信上查看歷史文章不能排序,一些較早期的文章翻很長時間才能找到,而且往往沒有一次看不了幾篇,下次還得再重頭翻,想想就很痛苦。
目前我在網上找了找,看到實現的方式大概分為以下三種:
wechatsogou 這個 Python 模塊,去搜索公號后,實現批量下載。整體來看最后一種方式是最簡單的,接下來將以第三種方式為例,為大家介紹如何達到批量下載的目的。
首先我們登陸到公眾號平臺,登陸成功后會跳轉到公眾號管理首頁,如下圖:
python爬取pdf指定內容?
然后我們在當前頁面打開瀏覽器開發者工具,刷新下頁面,在網絡里就能看到各種請求,在這里我們點開一個請求 url,然后就能看到下圖網絡請求信息,里面包含請求的 Cookie 信息。
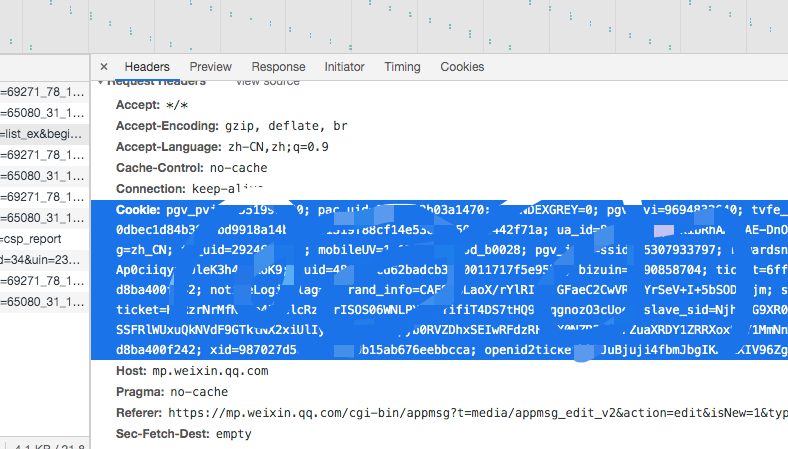
接下來我們需要把 Cookie 信息復制下來轉換成 Json 格式串保存到文本文件里,以供后面請求鏈接時使用。這里需要寫一段 Python 代碼進行處理,新建文件 gen_cookies.py 寫入代碼如下:
# gen_cookies.pyimport json# 從瀏覽器中復制出來的 Cookie 字符串cookie_str = "pgv_pvid=9551991123; pac_uid=89sdjfklas; XWINDEXGREY=0; pgv_pvi=89273492834; tvfe_boss_uuid=lkjslkdf090; RK=lksdf900; ptcz=kjalsjdflkjklsjfdkljslkfdjljsdfk; ua_id=ioje9899fsndfklsdf-DKiowiekfjhsd0Dw=; h_uid=lkdlsodifsdf; mm_lang=zh_CN; ts_uid=0938450938405; mobileUV=98394jsdfjsd8sdf; \……中間部分省略 \ EXIV96Zg=sNOaZlBxE37T1tqbsOL/qzHBtiHUNZSxr6TMqpb8Z9k="cookie = {}# 遍歷 cookie 信息for cookies in cookie_str.split("; "): cookie_item = cookies.split("=") cookie[cookie_item[0]] = cookie_item[1]# 將cookies寫入到本地文件with open('cookie.txt', "w") as file: # 寫入文件 file.write(json.dumps(cookie))好了,將 Cookie 寫入文件后,接下來就來說下在哪里可以找到某公號的文章鏈接。
在公號管理平臺首頁點擊左側素材管理菜單,進入素材管理頁面,然后點擊右側的新建圖文素材按鈕,如下圖:
Python批量提取PDF中的信息、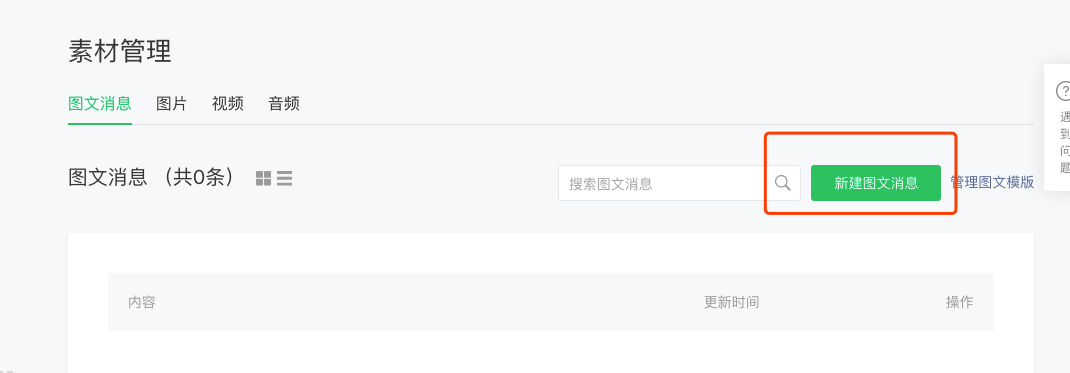
進入新建圖文素材頁面,然后點擊這里的超鏈接:
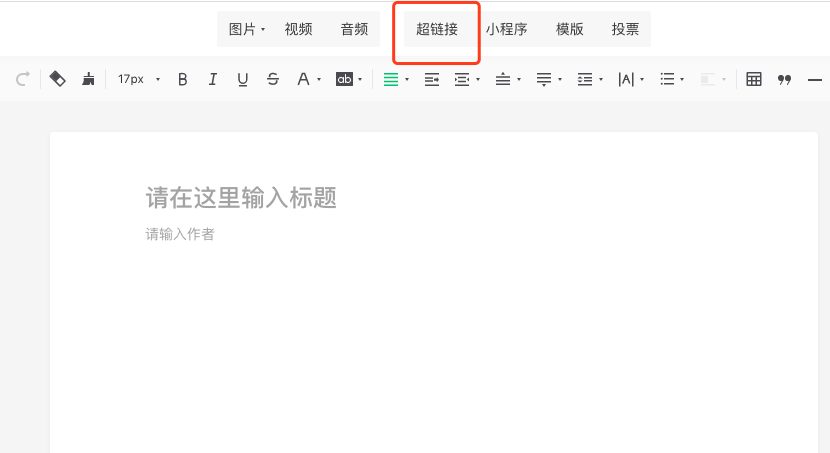
在編輯超鏈接的彈出框里,點擊選擇其他公眾號的連接:
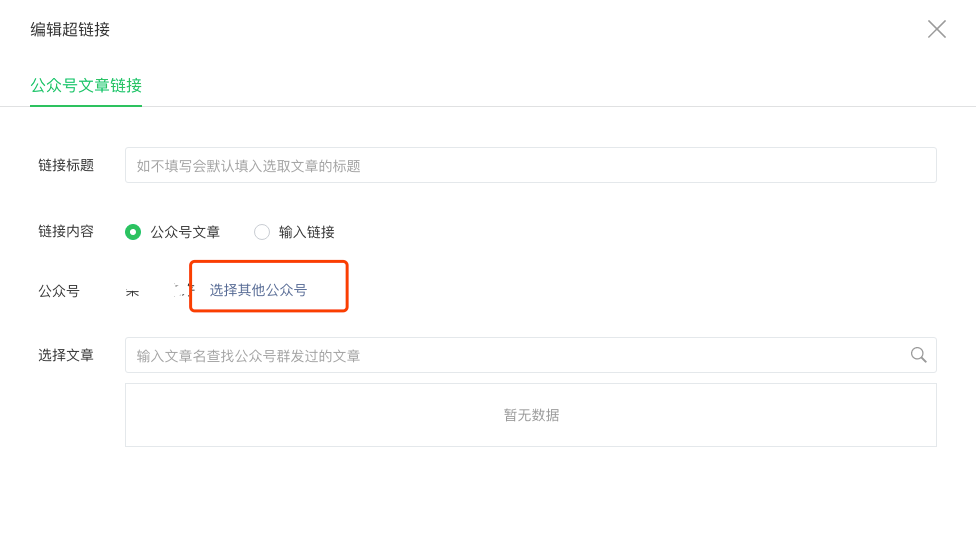
在這里我們就能通過搜索,輸入關鍵字搜索我們想要找到公眾號,比如在這里我們搜索 "Python 技術",就能看到如下搜索結果:
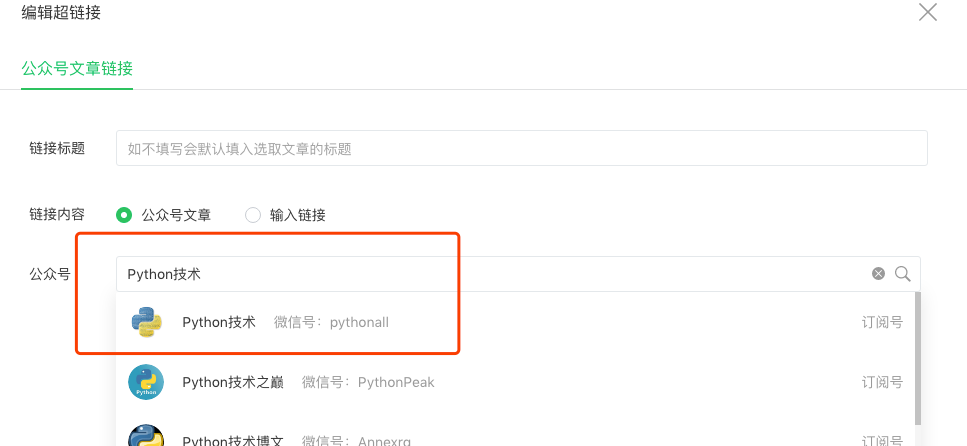
python中response?然后點擊第一個 Python 技術的公眾號,在這里我們就能看到這個公眾號歷史發布過的所有文章:
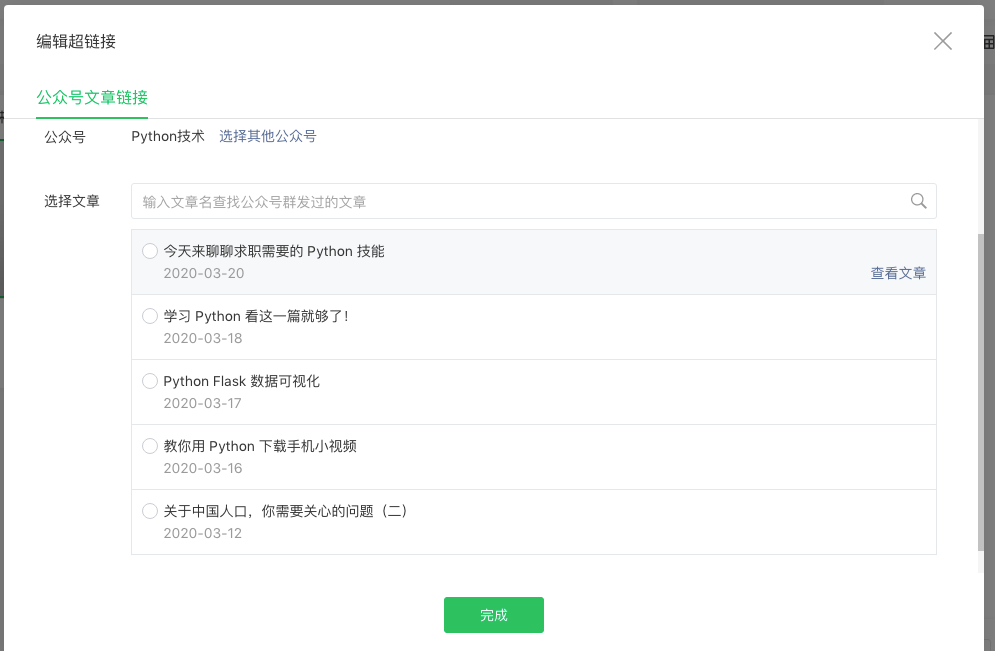
我們看到這里文章每頁只顯示五篇,一共分了31頁,現在我們再打開自帶的開發者工具,然后在列表下面點下一頁的按鈕,在網絡中會看到向服務發送了一個請求,我們分析下這個請求的參數。
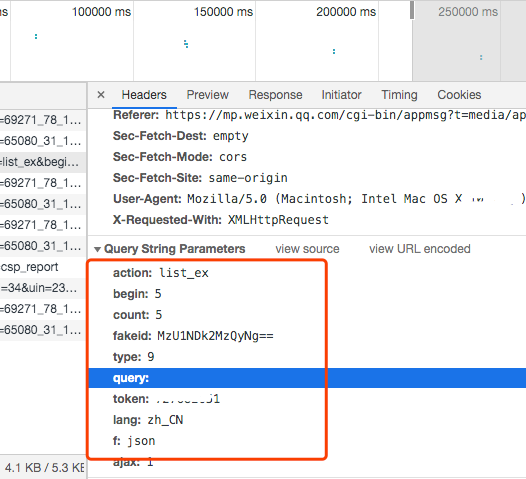
通過請求參數,我們大概可以分析出參數的意義, begin 是從第幾篇文章開始,count 是一次查出幾篇,fakeId 對應這個公號的唯一 Id,token 是通過 Cookie 信息來獲取的。好了,知道這些我們就可以用 Python 寫段代碼去遍歷請求,新建文件 gzh_download.py,代碼如下:
# gzh_download.py# 引入模塊import requestsimport jsonimport reimport randomimport timeimport pdfkit# 打開 cookie.txtwith open("cookie.txt", "r") as file: cookie = file.read()cookies = json.loads(cookie)url = "https://mp.weixin.qq.com"#請求公號平臺response = requests.get(url, cookies=cookies)# 從url中獲取tokentoken = re.findall(r'token=(\d+)', str(response.url))[0]# 設置請求訪問頭信息headers = { "Referer": "https://mp.weixin.qq.com/cgi-bin/appmsg?t=media/appmsg_edit_v2&action=edit&isNew=1&type=10&token=" + token + "&lang=zh_CN", "Host": "mp.weixin.qq.com", "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36",}# 循環遍歷前10頁的文章for j in range(1, 10, 1): begin = (j-1)*5 # 請求當前頁獲取文章列表 requestUrl = "https://mp.weixin.qq.com/cgi-bin/appmsg?action=list_ex&begin="+str(begin)+"&count=5&fakeid=MzU1NDk2MzQyNg==&type=9&query=&token=" + token + "&lang=zh_CN&f=json&ajax=1" search_response = requests.get(requestUrl, cookies=cookies, headers=headers) # 獲取到返回列表 Json 信息 re_text = search_response.json() list = re_text.get("app_msg_list") # 遍歷當前頁的文章列表 for i in list: # 將文章鏈接轉換 pdf 下載到當前目錄 pdfkit.from_url(i["link"], i["title"] + ".pdf") # 過快請求可能會被微信問候,這里進行10秒等待 time.sleep(10)好了,就上面這點代碼就夠了,這里在將 URL 轉成 PDF 時使用的是 pdfkit 的模塊,使用這個需要先安裝 wkhtmltopdf 這個工具,官網地址在文末給出,支持多操作系統,自己下載安裝即可,這里就不再贅述。
python爬蟲教程?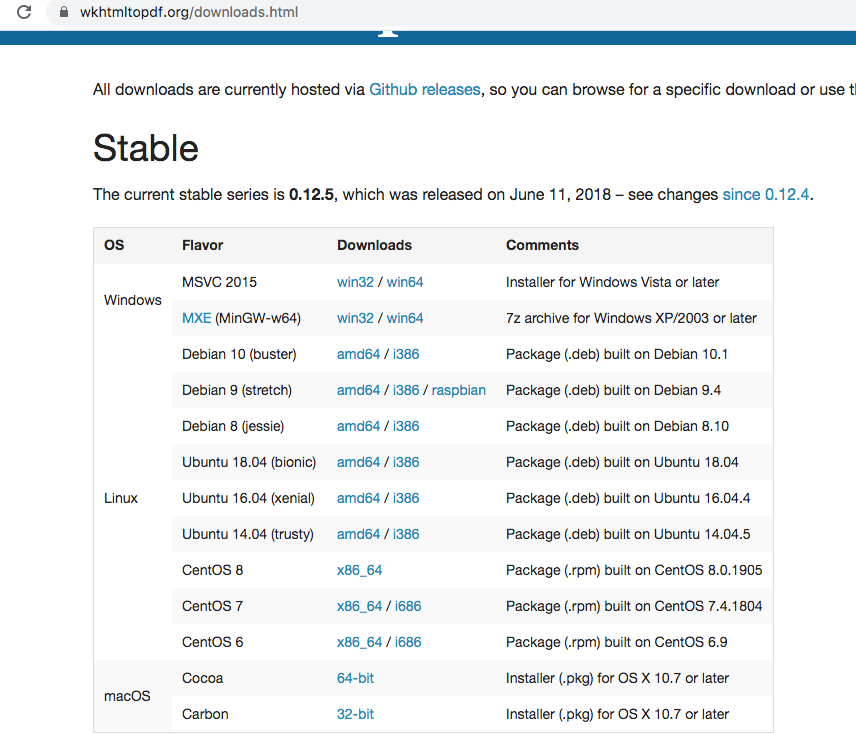
安裝完后,還需要再執行 pip3 install pdfkit 命令安裝這個模塊。安裝好了,現在來執行下 python gzh_download.py 命令啟動程序看下效果怎么樣。

看來是成功了,這個工具還是很強大的。
python django。本文為大家介紹了如何通過分析公眾號平臺的功能,找到可以訪問到某個公眾號所有文章的鏈接,從而可以批量下載某公眾號所有文章,并轉為 PDF 格式保存到本地的目的。這里通過 Python 寫了少量代碼就實現文章的抓取和轉換的工作,如果有興趣你也可以試試。
https://wkhtmltopdf.org/downloads.html

【代碼獲取方式】
識別文末二維碼,回復:666PS:公號內回復「Python」即可進入 Python 新手學習交流群,一起?100天計劃!-END-Python 技術關于 Python 都在這里
版权声明:本站所有资料均为网友推荐收集整理而来,仅供学习和研究交流使用。

工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态