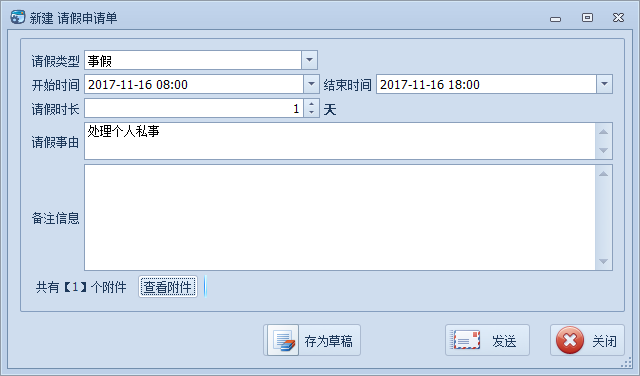
理解SQL Server中索引的概念,原理
摘自:http://51even.iteye.com/blog/1490412
簡介
?
??? 在SQL Server中,索引是一種增強式的存在,這意味著,即使沒有索引,SQL Server仍然可以實現應有的功能。但索引可以在大多數情況下大大提升查詢性能,在OLAP中尤其明顯.要完全理解索引的概念,需要了解大量原理性的知識,包括B樹,堆,數據庫頁,區,填充因子,碎片,文件組等等一系列相關知識,這些知識寫一本小書也不為過。所以本文并不會深入討論這些主題。
?
索引是什么
??? 索引是對數據庫表中一列或多列的值進行排序的一種結構,使用索引可快速訪問數據庫表中的特定信息。
??? 精簡來說,索引是一種結構.在SQL Server中,索引和表(這里指的是加了聚集索引的表)的存儲結構是一樣的,都是B樹,B樹是一種用于查找的平衡多叉樹.理解B樹的概念如下圖:
sql中索引怎么使用,????
??? 理解為什么使用B樹作為索引和表(有聚集索引)的結構,首先需要理解SQL Server存儲數據的原理.
??? 在SQL SERVER中,存儲的單位最小是頁(PAGE),頁是不可再分的。就像細胞是生物學中不可再分的,或是原子是化學中不可再分的最小單位一樣.這意味著,SQL SERVER對于頁的讀取,要么整個讀取,要么完全不讀取,沒有折中.
??? 在數據庫檢索來說,對于磁盤IO掃描是最消耗時間的.因為磁盤掃描涉及很多物理特性,這些是相當消耗時間的。所以B樹設計的初衷是為了減少對于磁盤的掃描次數。如果一個表或索引沒有使用B樹(對于沒有聚集索引的表是使用堆heap存儲),那么查找一個數據,需要在整個表包含的數據庫頁中全盤掃描。這無疑會大大加重IO負擔.而在SQL SERVER中使用B樹進行存儲,則僅僅需要將B樹的根節點存入內存,經過幾次查找后就可以找到存放所需數據的被葉子節點包含的頁!進而避免的全盤掃描從而提高了性能.
??? 下面,通過一個例子來證明:
???? 在SQL SERVER中,表上如果沒有建立聚集索引,則是按照堆(HEAP)存放的,假設我有這樣一張表:
數據庫索引的概念、?????
???? 現在這張表上沒有任何索引,也就是以堆存放,我通過在其上加上聚集索引(以B樹存放)來展現對IO的減少:
?????
?
?
?
理解聚集和聚集索引
sql中的索引是什么意思,??? 在SQL SERVER中,最主要的兩類索引是聚集索引和非聚集索引。可以看到,這兩個分類是圍繞聚集這個關鍵字進行的.那么首先要理解什么是聚集.
??? 聚集在索引中的定義:
????為了提高某個屬性(或屬性組)的查詢速度,把這個或這些屬性(稱為聚集碼)上具有相同值的元組集中存放在連續的物理塊稱為聚集。
??? 簡單來說,聚集索引就是:
????
??? 在SQL SERVER中,聚集的作用就是將某一列(或是多列)的物理順序改變為和邏輯順序相一致,比如,我從adventureworks數據庫的employee中抽取5條數據:
mysql聯合索引的原理?????
??? 當我在ContactID上建立聚集索引時,再次查詢:
????
??? 在SQL SERVER中,聚集索引的存儲是以B樹存儲,B樹的葉子直接存儲聚集索引的數據:
????
??? 因為聚集索引改變的是其所在表的物理存儲順序,所以每個表只能有一個聚集索引.
sqlserver 索引,?
非聚集索引
???? 因為每個表只能有一個聚集索引,如果我們對一個表的查詢不僅僅限于在聚集索引上的字段。我們又對聚集索引列之外還有索引的要求,那么就需要非聚集索引了.
???? 非聚集索引,本質上來說也是聚集索引的一種.非聚集索引并不改變其所在表的物理結構,而是額外生成一個聚集索引的B樹結構,但葉子節點是對于其所在表的引用,這個引用分為兩種,如果其所在表上沒有聚集索引,則引用行號。如果其所在表上已經有了聚集索引,則引用聚集索引的頁.
???? 一個簡單的非聚集索引概念如下:
?????
???? 可以看到,非聚集索引需要額外的空間進行存儲,按照被索引列進行聚集索引,并在B樹的葉子節點包含指向非聚集索引所在表的指針.
什么是索引,???? MSDN中,對于非聚集索引描述圖是:
?????
???? 可以看到,非聚集索引也是一個B樹結構,與聚集索引不同的是,B樹的葉子節點存的是指向堆或聚集索引的指針.
???? 通過非聚集索引的原理可以看出,如果其所在表的物理結構改變后,比如加上或是刪除聚集索引,那么所有非聚集索引都需要被重建,這個對于性能的損耗是相當大的。所以最好要先建立聚集索引,再建立對應的非聚集索引.
?
聚集索引 VS 非聚集索引
????? 前面通過對于聚集索引和非聚集索引的原理解釋.我們不難發現,大多數情況下,聚集索引的速度比非聚集索引要略快一些.因為聚集索引的B樹葉子節點直接存儲數據,而非聚集索引還需要額外通過葉子節點的指針找到數據.
索引的目的?????? 還有,對于大量連續數據查找,非聚集索引十分乏力,因為非聚集索引需要在非聚集索引的B樹中找到每一行的指針,再去其所在表上找數據,性能因此會大打折扣.有時甚至不如不加非聚集索引.
????? 因此,大多數情況下聚集索引都要快于非聚集索引。但聚集索引只能有一個,因此選對聚集索引所施加的列對于查詢性能提升至關緊要.
?
索引的使用
???? 索引的使用并不需要顯式使用,建立索引后查詢分析器會自動找出最短路徑使用索引.
???? 但是有這種情況.當隨著數據量的增長,產生了索引碎片后,很多存儲的數據進行了不適當的跨頁,會造成碎片(關于跨頁和碎片以及填充因子的介紹,我會在后續文章中說到)我們需要重新建立索引以加快性能:
???? 比如前面的test_tb2上建立的一個聚集索引和非聚集索引,可以通過DMV語句查詢其索引的情況:
SELECT index_type_desc,alloc_unit_type_desc,avg_fragmentation_in_percent,fragment_count,avg_fragment_size_in_pages,page_count,record_count,avg_page_space_used_in_percent
FROM sys.dm_db_index_physical_stats(DB_ID('AdventureWorks'),OBJECT_ID('test_tb2'),NULL,NULL,'Sampled') b樹索引原理??
?????
??? 我們可以通過重建索引來提高速度:
ALTER INDEX idx_text_tb2_EmployeeID ON test_tb2 REBUILD
?
?
??? 還有一種情況是,當隨著表數據量的增大,有時候需要更新表上的統計信息,讓查詢分析器根據這些信息選擇路徑,使用:
UPDATE STATISTICS 表名
簡述索引的概念和分類。?? 那么什么時候知道需要更新這些統計信息呢,就是當執行計劃中估計行數和實際表的行數有出入時:
???
?
使用索引的代價
??? 我最喜歡的一句話是”everything has price”。我們通過索引獲得的任何性能提升并不是不需要付出代價。這個代價來自幾方面.
??? 1.通過聚集索引的原理我們知道,當表建立索引后,就以B樹來存儲數據.所以當對其進行更新插入刪除時,就需要頁在物理上的移動以調整B樹.因此當更新插入刪除數據時,會帶來性能的下降。而對于聚集索引,當更新表后,非聚集索引也需要進行更新,相當于多更新了N(N=非聚集索引數量)個表。因此也下降了性能.
??? 2.通過上面對非聚集索引原理的介紹,可以看到,非聚集索引需要額外的磁盤空間。
普通索引概念,??? 3.前文提過,不恰當的非聚集索引反而會降低性能.
????所以使用索引需要根據實際情況進行權衡.通常我都會將非聚集索引全部放到另外一個獨立硬盤上,這樣可以分散IO,從而使查詢并行.