今天這篇是機器學習專題的第24篇文章,我們來聊聊回歸樹模型。
所謂的回歸樹模型其實就是用樹形模型來解決回歸問題,樹模型當中最經典的自然還是決策樹模型,它也是幾乎所有樹模型的基礎。雖然基本結構都是使用決策樹,但是根據預測方法的不同也可以分為兩種。第一種,樹上的葉子節點就對應一個預測值和分類樹對應,這一種方法稱為回歸樹。第二種,樹上的葉子節點對應一個線性模型,最后的結果由線性模型給出。這一種方法稱為模型樹。
今天我們先來看看其中的回歸樹。
回歸樹模型的核心算法,也就是構建決策樹的算法,就是我們上篇文章所講的CART算法。如果有生疏或者是遺漏的同學,可以通過下方傳送門回顧一下:
機器學習十大經典算法之一——決策樹CART算法
CART算法的核心精髓就是我們每次選擇特征對數據進行拆分的時候,永遠對數據集進行二分。無論是離散特征還是連續性特征,一視同仁。CART還有一個特點是使用GINI指數而不是信息增益或者是信息增益比來選擇拆分的特征,但是在回歸問題當中用不到這個。因為回歸問題的損失函數是均方差,而不是交叉熵,很難用熵來衡量連續值的準確度。
在分類樹當中,我們一個葉子節點代表一個類別的預測值,這個類別的值是落到這個葉子節點當中訓練樣本的類別的眾數,也就是出現頻率最高的類別。在回歸樹當中,葉子節點對應的自然就是一個連續值。這個連續值是落到這個節點的訓練樣本的均值,它的誤差就是這些樣本的均方差。
另外,之前我們在選擇特征的劃分閾值的時候,對閾值的選擇進行了優化,只選擇了那些會引起預測類別變化的閾值。但是在回歸問題當中,由于預測值是一個浮點數,所以這個優化也不存在了。整體上來說,其實回歸樹的實現難度比分類樹是更低的。
我們首先來加載數據,我們這次使用的是scikit-learn庫當中經典的波士頓房價預測的數據。關于房價預測,kaggle當中也有一個類似的比賽,叫做:house-prices-advanced-regression-techniques。不過給出的特征更多,并且存在缺失等情況,需要我們進行大量的特征工程。感興趣的同學可以自行研究一下。
首先,我們來獲取數據,由于sklearn庫當中已經有數據了,我們可以直接調用api獲取,非常簡單:
import numpy as npimport pandas as pdfrom sklearn.datasets import load_bostonboston = load_boston()X, y = boston.data, boston.target我們輸出前幾條數據查看一下:
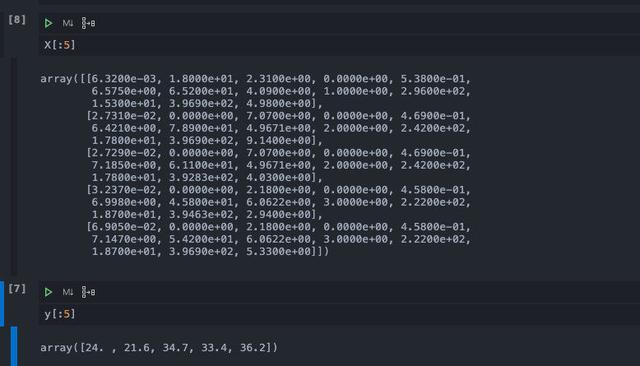
這個數據質量很高,sklearn庫已經替我們做完了數據篩選與特征工程,直接拿來用就可以了。為了方便我們傳遞數據,我們將X和y合并在一起。由于y是一維的數組形式是不能和二維的X合并的,所以我們需要先對y進行reshape之后再進行合并。
y = y.reshape(-1, 1)X = np.hstack((X, y))hstack函數可以將兩個np的array橫向拼接,與之對應的是vstack,是將兩個array縱向拼接,這個也是常規操作。合并之后,y作為新的一列添加在了X的后面。數據搞定了,接下來就要輪到實現模型了。
在實現決策樹的主體部分之前,我們先來實現兩個輔助函數。第一個輔助函數是計算一批樣本的方差和,第二個輔助函數是獲取樣本的均值,也就是子節點的預測值。
def node_mean(X): return np.mean(X[:, -1])def node_variance(X): return np.var(X[:, -1]) * X.shape[0]這個搞定了之后,我們繼續實現根據閾值拆分數據的函數。這個也可以復用之前的代碼:
from collections import defaultdictdef split_dataset(X, idx, thred): split_data = defaultdict(list) for x in X: split_data[x[idx] < thred].append(x) return list(split_data.values()), list(split_data.keys())接下來是兩個很重要的函數,分別是get_thresholds和split_variance。顧名思義,第一個函數用來獲取閾值,前面說了由于我們做的是回歸模型,所以理論上來說特征的每一個取值都可以作為切分的依據。但是也不排除可能會存在多條數據的特征值相同的情況,所以我們對它進行去重。第二個函數是根據閾值對數據進行拆分,返回拆分之后的方差和。
def get_thresholds(X, i): return set(X[:, i].tolist())# 每次迭代方差優化的底線MINIMUM_IMPROVE = 2.0# 每個葉子節點最少樣本數MINIMUM_SAMPLES = 10def split_variance(dataset, idx, threshold): left, right = [], [] n = dataset.shape[0] for data in dataset: if data[idx] < threshold: left.append(data) else: right.append(data) left, right = np.array(left), np.array(right) # 預剪枝 # 如果拆分結果有一邊過少,則返回None,防止過擬合 if len(left) < MINIMUM_SAMPLES or len(right) < MINIMUM_SAMPLES: return None # 拆分之后的方差和等于左子樹的方差和加上右子樹的方差和 # 因為是方差和而不是均方差,所以可以累加 return node_variance(left) + node_variance(right)這里我們用到了MINIMUM_SAMPLES這個參數,它是用來預剪枝用的。由于我們是回歸模型,如果不對決策樹的生長加以限制,那么很有可能得到的決策樹的葉子節點和訓練樣本的數量一樣多。這顯然就陷入了過擬合了,對于模型的效果是有害無益的。所以我們要限制每個節點的樣本數量,這個是一個參數,我們可以根據需要自行調整。
接下來,就是特征和閾值篩選的函數了。我們需要開發一個函數來遍歷所有可以拆分的特征和閾值,對數據進行拆分,從所有特征當中找到最佳的拆分可能。
def choose_feature_to_split(dataset): n = len(dataset[0])-1 m = len(dataset) # 記錄最佳方差,特征和閾值 var_ = node_variance(dataset) bestVar = float('inf') feature = -1 thred = None for i in range(n): threds = get_thresholds(dataset, i) for t in threds: # 遍歷所有的閾值,計算每個閾值的variance v = split_variance(dataset, i, t) # 如果v等于None,說明拆分過擬合了,跳過 if v is None: continue if v < bestVar: bestVar, feature, thred = v, i, t # 如果最好的拆分效果達不到要求,那么就不拆分,控制子樹的數量 if var_ - bestVar < MINIMUM_IMPROVE: return None, None return feature, thred和上面一樣,這個函數當中也用到了一個預剪枝的參數MINIMUM_IMPROVE,它衡量的是每一次生成子樹帶來的收益。當某一次生成子樹帶來的收益小于某個值的時候,說明收益很小,并不劃算,所以我們就放棄這次子樹的生成。這也是預剪枝的一種。
這些都搞定了之后,就可以來建樹了。建樹的過程和之前類似,只是我們這一次的數據當中沒有特征的name,所以我們去掉特征名稱的相關邏輯。
def create_decision_tree(dataset): dataset = np.array(dataset) # 如果當前數量小于10,那么就不再繼續劃分了 if dataset.shape[0] < MINIMUM_SAMPLES: return node_mean(dataset) # 記錄最佳拆分的特征和閾值 fidx, th = choose_feature_to_split(dataset) if fidx is None: return th node = {} node['feature'] = fidx node['threshold'] = th # 遞歸建樹 split_data, vals = split_dataset(dataset, fidx, th) for data, val in zip(split_data, vals): node[val] = create_decision_tree(data) return node我們來完整測試一下建樹,首先我們需要對原始數據進行拆分。將原始數據拆分成訓練數據和測試數據,由于我們的場景比較簡單,就不設置驗證數據了。
拆分數據不用我們自己實現,sklearn當中提供了相應的工具,我們直接調用即可:
from sklearn.model_selection import train_test_splitX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=23)我們一般用到的參數就兩個,一個是test_size,它可以是一個整數也可以是一個浮點數。如果是整數,代表的是測試集的樣本數量。如果是一個0-1.0的浮點數,則代表測試集的占比。random_state是生成隨機數的時候用到的隨機種子。
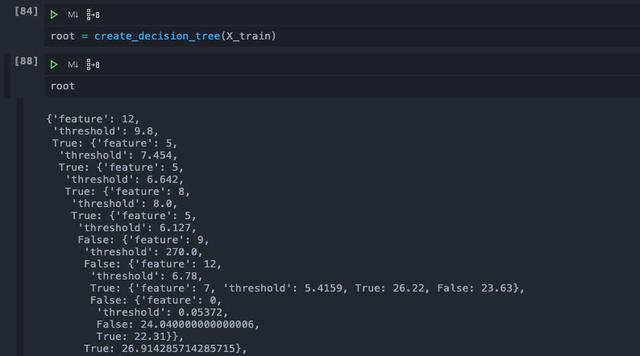
我們輸出一下生成的樹,由于數據量比較大,可以看到一顆龐大的樹結構。建樹的部分實現了之后,最后剩下的就是預測的部分了。
預測部分的代碼和之前分類樹相差不大,整體的邏輯完全一樣,只是去掉了feature_names的相關邏輯。
def classify(node, data): key = node['feature'] pred = None thred = node['threshold'] if isinstance(node[data[key] < thred], dict): pred = classify(node[data[key] < thred], data) else: pred = node[data[key] < thred] # 放置pred為空,挑選一個葉子節點作為替補 if pred is None: for key in node: if not isinstance(node[key], dict): pred = node[key] break return pred由于這個函數一次只能接受一條數據,如果我們想要批量預測的話還不行,所以最好的話再實現一個批量預測的predict函數比較好。
def predict(node, X): y_pred = [] for x in X: y = classify(node, x) y_pred.append(y) return np.array(y_pred)后剪枝的英文原文是post-prune,但是翻譯成事后剪枝也有點奇怪。anyway,我們就用后剪枝這個詞好了。
在回歸樹當中,我們利用的思想非常樸素,在建樹的時候建立一棵盡量復雜龐大的樹。然后在通過測試集對這棵樹進行修剪,修剪的邏輯也非常簡單,我們判斷一棵子樹存在分叉和沒有分叉單獨成為葉子節點時的誤差,如果修剪之后誤差更小,那么我們就剪去這棵子樹。
整個剪枝的過程和建樹的過程一樣,從上到下,遞歸執行。
整個邏輯很好理解,我們直接來看代碼:
def is_dict(node): return isinstance(node, dict)def prune(node, testData): testData = np.array(testData) if testData.shape[0] == 0: return node # 拆分數據 split_data, _ = split_dataset(testData, node['feature'], node['threshold']) # 對左右子樹遞歸修剪 if is_dict(node[0]): node[0] = prune(node[0], split_data[0]) if is_dict(node[1]) and len(split_data) > 1: node[1] = prune(node[1], split_data[1]) # 如果左右都是葉子節點,那么判斷當前子樹是否需要修剪 if len(split_data) > 1 and not is_dict(node[0]) and not is_dict(node[1]): # 計算修剪前的方差和 baseError = np.sum(np.power(np.array(split_data[0])[:, -1] - node[0], 2)) + np.sum(np.power(np.array(split_data[1])[:, -1] - node[1], 2)) # 計算修剪后的方差和 meanVal = (node[0] + node[1]) / 2 mergeError = np.sum(np.power(meanVal - testData[:, -1], 2)) if mergeError < baseError: return meanVal else: return node return node最后,我們對修剪之后的效果做一下驗證:
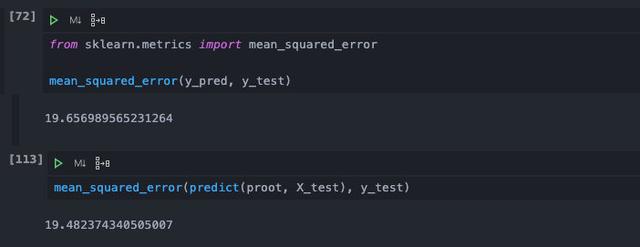
從圖中可以看到,修剪之前我們在測試數據上的均方差是19.65,而修剪之后降低到了19.48。從數值上來看是有效果的,只是由于我們的訓練數據比較少,同時進行了預剪枝,影響了后剪枝的效果。但是對于實際的機器學習工程來說,一個方法只要是有明確效果的,在代價可以承受的范圍內,它就是有價值的,千萬不能覺得提升不明顯,而隨便否定一個方法。
這里計算均方差的時候用到了sklearn當中的一個庫函數mean_square_error,從名字當中我們也可以看得出來它的用途,它可以對兩個Numpy的array計算均方差。
關于回歸樹模型的相關內容到這里就結束了,我們不僅親手實現了模型,而且還在真實的數據集上做了實驗。如果你是親手實現的模型的代碼,相信你一定會有很多收獲。
雖然從實際運用來說我們幾乎不會使用樹模型來做回歸任務,但是回歸樹模型本身是非常有意義的。因為在它的基礎上我們發展出了很多效果更好的模型,比如大名鼎鼎的GBDT。因此理解回歸樹對于我們后續進階的學習是非常重要的。在深度學習普及之前,其實大多數高效果的模型都是以樹模型為基礎的,比如隨機森林、GBDT、Adaboost等等。可以說樹模型撐起了機器學習的半個時代,這么說相信大家應該都能理解它的重要性了吧。
今天的文章就到這里,如果喜歡本文,可以的話,請點個關注,給我一點鼓勵,也方便獲取更多文章。
本文始發于公眾號:TechFlow
版权声明:本站所有资料均为网友推荐收集整理而来,仅供学习和研究交流使用。

工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态