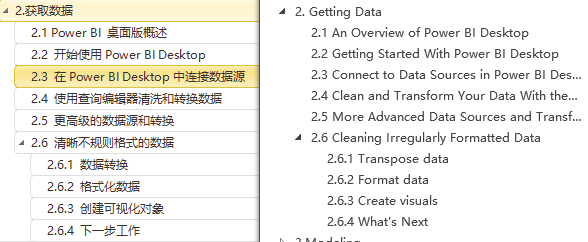
一、3 种模式
r: 只读模式, r+: 读写模式,覆盖开头内容
w: 写模式,全覆盖 (如果是没有的文件则重新创建空文件)
a+: 读写模式,从最开头写,覆盖开头内容 (如果是没有的文件则重新创建空文件)
f=open('陈粒1','r',encoding='utf8') #data=f.read() 光标跑到文件最末尾,之后执行readline,读到的为空 #print(data) print(f.readable()) print('第1行',f.readline(),end='') # 每行读取的文件末尾有一个'\n' print('第2行',f.readline(),end='') print('第3行',f.readline())
使用发送到桌面的方法创建记事本。二、文件处理模式b模式
因为r, w, a模式默认都是读写的 txt 模式的文件,但是有的文件,比如视频文件,就需要2进制模式读写,因此要用rb, wb, ab模式。
f1=open('test11.py','rb') #b的方式不能指定编码 data=f1.read() print(data) # b'11111\r\n22222\r\n33333\r\n44444\r\n55555' windows中的回车为'\r\n' f1.close() # #bytes---------decode---------》'字符串' f2=open('test22.py','wb') #b的方式不能指定编码 f2.write(bytes('1111\n',encoding='utf-8')) #(编码)'字符串'---------encode---------》bytes# 将字符串'1111\n',通过utf-8编码,转换成二进制形式 f2.write('杨件'.encode('utf-8')) f2.close()f3=open('test22.py','ab') #b的方式不能指定编码 f3.write('asdf'.encode('utf-8')) f3.close() # test22的最后内容为: #1111#杨件asdf
三、文件处理方式
# test11.py 的内容是: 11111#22222#333 f = open('test11.py','r+',encoding='utf-8') # tell(),读取当前光标位置,以字节为单位 print(f.tell()) # 0 f.readline() print(f.tell()) # 6 f.readline() print(f.tell()) # 12
# test11.py 的内容是: 1111111111#2222222222#333 f = open('test11.py','r+',encoding='utf-8') # tell(),读取当前光标位置,以字节为单位 print(f.tell()) # 0 seek(n),光标放到第 n 个字节的位置 f.readline() print(f.tell()) # 11 f.seek(2) print(f.tell()) # 2 f.write('你好') f.seek(8) print(f.tell()) # 8 f.write('你好') # 最后test11.py 的内容是: 11你好你好2222222#333 # 因为“你好你好”占了12个字符,所以用去了第一行的回车,和第二行的 3 个‘2’。
# test11.py 的内容是: 1111111111 # 2222222222 # 333 f = open('test11.py','r+',encoding='utf-8') # read(n), 读取n个字符 data = f.read(13) print(data) # 1111111111 # 22 回车代表一个字符
# test11.py 的内容是: 你好 # 2222222222 # 333 f = open('test11.py','r+',encoding='utf-8') # truncate(n), 截取n个字节 f.truncate(9) # 最后test11.py 的内容是: 你好 # 22
seek 的另一种用法:
从上次光标的位置往后推移 n 个字节
f=open('test11.py','rb') # 需要以 b 的方式 seek print(f.tell()) # 0 f.seek(10,1) print(f.tell()) # 10 f.seek(3,1) print(f.tell()) # 13
读取文件的最后一行:
f = open('test11.py','rb') for i in f:offs=-10while True:f.seek(offs,2) # 从文件的末尾往上找10个字节data=f.readlines()if len(data) > 1:print('文件的最后一行是 %s' %(data[-1].decode('utf-8')))breakoffs*=2 f.close()
文件加密怎么设置、四、for循环
for 循环是将 列表、元组、集合、字典、字符串、文件 变为可迭代对象,然后一个一个遍历读出,可以节省内存
x='hello' iter_test=x.__iter__() # 将 x 转换为可迭代对象,“字符串”,“列表”, “元组”,“字典”,“集合”都能转换print(iter_test) print(iter_test.__next__()) # h print(iter_test.__next__()) # e print(iter_test.__next__()) # l print(iter_test.__next__()) # l print(iter_test.__next__()) # o print(iter_test.__next__()) # 报错 y = ('s','d','f') y1 = y.__iter__() print(y1.__next__()) # s 有序 print(y1.__next__()) # d print(y1.__next__()) # f u = {'a','b'} u1 = u.__iter__() print(u1.__next__()) # b 无序 print(u1.__next__()) # a v = {'A':12,'B':34} v1 = v.__iter__() print(v1.__next__()) # B 无序 print(v1.__next__()) # A
while 循环也可实现:
l = ['a','s','d'] index=0 while index < len(l):print(l[index])index+=1
for 循环实际是这样运行的:
l=['die','erzi','sunzi','chongsunzi'] diedai_l = l.__iter__()while True:try:print(diedai_l.__next__())except StopIteration: # print('迭代完毕了,循环终止了')break