问题: method:org.apache.hadoop.hdfs.DomainSocketFactory.<init>(DomainSocketFactory.java:69) The short-circuit local reads feature cannot be used because libhadoop cannot be loaded. 不能使用local read的优化策略; 解决: Hadoop的一大
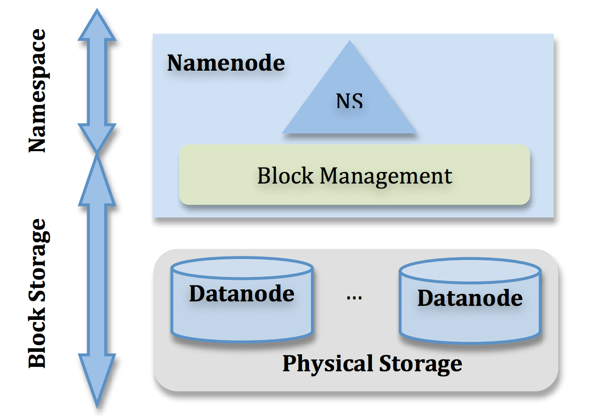
HDFS High Availability Using the Quorum Journal Manager HDFS High Availability Using the Quorum Journal Manager. 1 4.1 目的... 1 4.2 Note: Using the Quorum Journal Manager or Conventional Shared Storage. 2 4.3 background. 2 4.4结构体系... 2 4.5 硬件资源.
![创建与查看hdfs目录,IDEA本地运行Spark项目[演示自定义分区器]并查看HDFS结果文件](/upload/rand_pic/2-406.jpg)

![[HDFS Manual] CH4 HDFS High Availability Using the Quorum Journal Manager](https://images2018.cnblogs.com/blog/122543/201803/122543-20180322130755952-555123355.png)