首页
语法
变量
函数
技术动态
基础知识库
首页
/
Python爬取
python網絡爬蟲步驟,twisted python_《Python網絡爬蟲與信息提取》筆記(10)
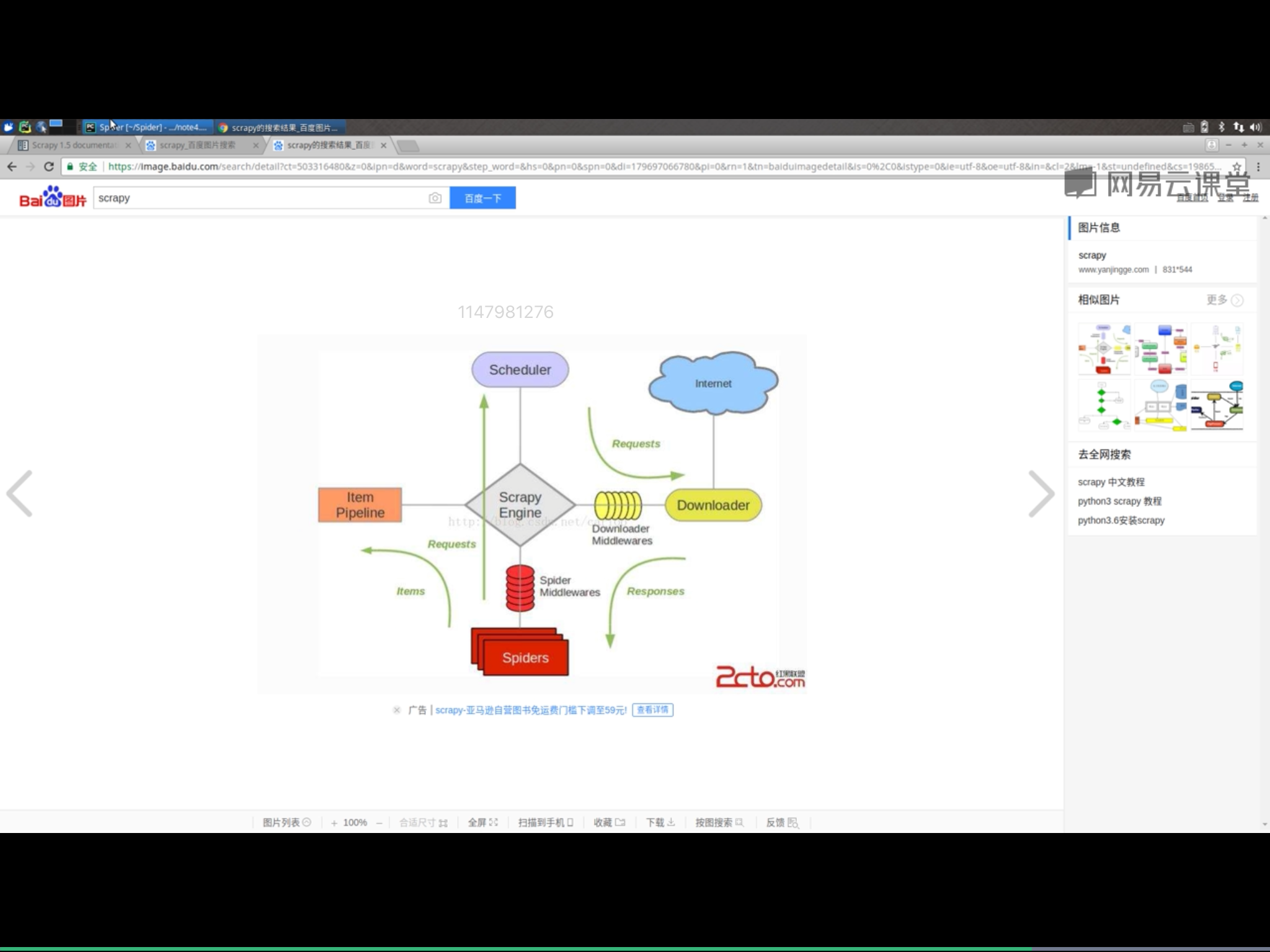
Scrapy爬蟲框架1.Scrapy爬蟲框架介紹python網絡爬蟲步驟,scrapy的安裝:1.安裝wheelpip install wheel2.安裝pywin32pip install pywin32python scrapy、3.安裝twisted從Python Extension Packages for Windows 點擊對應版本下載,cmd進入下載目錄,執行pi
时间:2023-12-10 | 阅读:28
高德爬蟲程序,python爬取地圖地址_python爬取了高德地圖一些地點的數據,爬出來數據大致情況如下:...
python爬取了高德地圖一些地點的數據,爬出來數據大致情況如下:下面是基本流程:1、注冊成為高德地圖API開發者,網址http://lbs.amap.com/(主要是獲取自己的keywords [注冊流程可以參考這個網址?https://lbs.amap.com/api/webservice/guide/create-
时间:2023-11-30 | 阅读:30
python隨機抽取,Python爬蟲 --- 2.2 Scrapy 選擇器的介紹
原文鏈接:www.fkomm.cn/article/201… 在使用Scrapy框架之前,我們必須先了解它是如何篩選數據的 Scrapy提取數據有自己的一套機制,被稱作選擇器(selectors),通過特定的Xpath或者CSS表達式來選擇HTML文件的某個部分, Xpath是專門在XML文件中
时间:2023-10-30 | 阅读:29
用 Python 实现溺水识别
作者 | 李秋键责编 | Carol众所周知随着人工智能智能的发展,人工智能的落地项目也在变得越来越多,尤其是计算机视觉方面。所以今天我们也是做一个计算机视觉方面的训练,用python来判断用户溺水行为,结合姿态识别和图像识别得到结果。其中包括姿态
时间:2023-09-09 | 阅读:17
python爬虫反爬-python爬虫--爬虫与反爬
爬虫与反爬 爬虫:自动获取网站数据的程序,关键是批量的获取。 反爬虫:使用技术手段防止爬虫程序的方法 python淘宝反爬虫,误伤:反爬技术将普通用户识别为爬虫,从而限制其访问,如果误伤过高,反爬效果再好也不能使用(
时间:2023-09-07 | 阅读:20
Python《第一次爬虫遭遇反盗链(上)》
今天想爬取下往上很多人都爬取过的https://www.mzitu.com/ 。 结果很尴尬,只能很浅显地爬取一些首页图片,因为遭遇到了反盗链。 鉴于图片过于那啥,其实我就来搞学习的,也不是什么LSP,老司机之类的,因此,在此就不做解析了哈哈
时间:2023-09-07 | 阅读:25
Python《第一次爬虫遭遇反盗链(下)》
上一篇博文,我遇到了防止盗链的问题, 防盗链原理 http标准协议中有专门的字段记录referer 一来可以追溯上一个入站地址是什么 二来对于资源文件,可以跟踪到包含显示他的网页地址是什么 因此所有防盗链方法都是基于这个Referer字段 防盗链的作用 在很多地
时间:2023-09-07 | 阅读:26
Python爬虫连载16-OCR工具Tesseract、Scrapt初步
一、验证码破解 1.(上承连载15)极验 (1)官网:http://www.geetest.com 破解比较麻烦、可以模拟鼠标移动、一直在进化 二、Tesseract 1.机器视觉领域的基础软件 2.OCR:OpticalCharacterRecognition 3.Tesseract:一个OCR库
时间:2023-09-06 | 阅读:18
阅读排行
2805℃
1
如何防止应用程序泄密?
2790℃
2
AlertDialog禁止返回键
2712℃
3
linux中MySQL密码的恢复方...
2550℃
4
node.js当中net模块的简单...
2295℃
5
我的高质量软件发布心得
2235℃
6
从源码角度看Spark on yar...
2076℃
7
在linux云服务器上运行Jar...
1767℃
8
codevs1521 华丽的吊灯
猜你喜欢
2017年国内开源镜像站点汇总
NFS与NAS谁更适合VMware
九、Citrix服务器虚拟化Xenserver虚拟机模版
vm 安装
jQuery Mobile中jQuery.mobile.changePage方法使用详解
猫都能学会的Unity3D Shader入门指南(二)
单用户及救援模式
如何从rpm包中提取文件
Ajax请求数据与删除数据后刷新页面
2015 年出现的十大流行 Python 库
C# 实现连连看功能
怎样才干成为一名优秀的软件測试人员
热门标签
python3
Spring boot
python有什么用
python和java
java
Springboot教程
python编程
Leetcode
python爬蟲教程
python菜鳥教程
Springboot注解
Mybatis
Springboot框架
Springboot
UNIXLINUX
SpringBootApplication
python为什么叫爬虫
qpython
我要关灯
我要开灯
客户电话
工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
官方微信
扫码二维码
获取最新动态
返回顶部