首页
语法
变量
函数
技术动态
基础知识库
首页
/
python 爬虫库
正则验证,Python之爬虫(七)正则的基本使用
什么是正则表达式 正则表达式是对字符串操作的一种逻辑公式,就是 事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符”,这个“规则字符” 来表达对字符的一种过滤逻辑。 正则并不是python独有的,其他语言也都有正则python中的
时间:2023-09-28 | 阅读:49
Python爬虫 Day 3
一.Selenium剩余部分1.元素交互操作 - 点击、清除 click clear - ActionChains 是一个动作链对象,需要把driver驱动传给它 动作链对象可以操作一系列设定好的动作 - frame的切换 - 执行js代码 ''' 点击、清除 ''' from selenium import webdr
时间:2023-09-19 | 阅读:27
Python爬虫_数据存储
文章目录HTML正文抽取多媒体文件抽取Email提醒 HTML正文抽取 HTML正文存储主要分为两种格式:JSON和CSV 储存为JSON 需求:抽取小说标题、章节、章节名称和链接 爬虫python?首先使用Requests访问http://seputu.com/,获取HTML文档内容,并打印文档内
时间:2023-09-10 | 阅读:24
Python爬虫_HTTP标准
文章目录简介HTTP请求过程HTTP状态码含义HTTP头部信息Cookie状态管理HTTP请求方式 简介 HTTP协议(超文本传输协议)是用于从WWW服务器传输超文本到本地浏览器的传送协议。它可以使浏览器更加高效,减少网络传输。它不仅保证计算机正确快速地传输超文本文档
时间:2023-09-10 | 阅读:25
Python 爬虫-BeautifulSoup
2017-07-26 10:10:11 Beautiful Soup可以解析html 和 xml 格式的文件。 Python爬虫,BeautifulSoup库是解析、遍历、维护“标签树”的功能库。使用BeautifulSoup库非常简单,只需要两行代码,就可以完成BeautifulSoup类的创建,这里命名为soup,接下来就可以
时间:2023-09-10 | 阅读:28
python伪装浏览器什么意思_python爬虫伪装浏览器出现问题求助
运行报错:: 'str' object has no attribute 'items'#-*-coding:utf-8-*-importurllib.requestdefsaveFile(data):path="E:\\123\\douban.out"python为什么叫爬虫、f=open(path,"wb")f.write(data)f.close()url="http:
时间:2023-09-09 | 阅读:32
python requests form data_Python爬虫:Request Payload和Form Data的简单区别说明
Request Payload 和 Form Data 请求头上的参数差别在于:Content-TypeForm DataPost表单请求代码示例headers = {高级爬虫、"Content-Type": "application/x-www-form-urlencoded"}requests.post(url, data=data, headers=headers)Request
时间:2023-09-07 | 阅读:25
Python爬虫的requests模块你真的学会了吗?来看看这些高级用法!
1. 文件上传 我们知道requests可以模拟提交一些数据。假如有的网站需要上传文件,我们也可以用它来实现,这非常简单,示例如下: 很多人学习python,不知道从何学起。 很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例
时间:2023-09-06 | 阅读:24
Python爬虫-- Scrapy框架
Scrapy框架 Scrapy使用了Twisted作为框架,Twisted有些特殊的地方是它是事件驱动的,并且比较适合异步的代码。对于会阻塞线程的操作包含访问文件、数据库或者Web、产生新的进程并需要处理新进程的输出(如运行shell命令)、执行系统层次操作的代码(如等待系统队列)
时间:2023-09-05 | 阅读:414
阅读排行
2750℃
1
如何防止应用程序泄密?
2745℃
2
AlertDialog禁止返回键
2564℃
3
linux中MySQL密码的恢复方...
2501℃
4
node.js当中net模块的简单...
2252℃
5
我的高质量软件发布心得
2183℃
6
从源码角度看Spark on yar...
2033℃
7
在linux云服务器上运行Jar...
1608℃
8
codevs1521 华丽的吊灯
猜你喜欢
2016物联网大趋势搞不懂?别担心,CES为你指点迷津
Git 相关使用命令
人类可以轻易" alt="用层进表面预测来重建三维物体">
用层进表面预测来重建三维物体
JAVA IO系列----ObjectInputStream和ObjectOutputStream类
使用IPMI工具实现对服务器的远程管理
政府安全资讯精选 2017年第十三期 网信办发布《互联网新闻信息服务新技术新应用安全评估管理规定》;Facebook颁布新广告政策,加强内容安全...
javascript--DOM概念
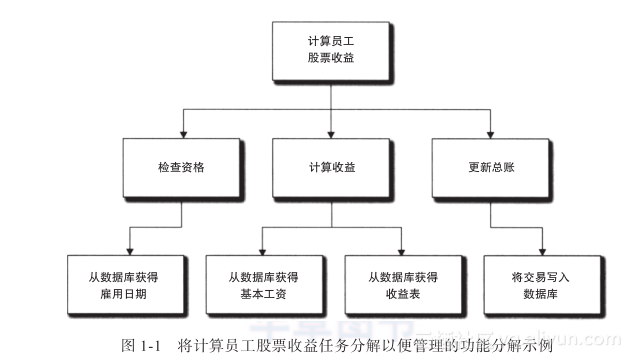
《基于模型的软件开发》——1.2 结构化开发
Laravel 中asset 函数支持https 协议
中矿新生赛 H 璐神看岛屿【BFS/DFS求联通块/连通块区域在边界则此连通块无效】...
苹果新款iPad或将于下月在新总部发布
71.Ext.form.ComboBox 完整属性
热门标签
python3
Spring boot
python有什么用
python和java
java
Springboot教程
python编程
Leetcode
python爬蟲教程
python菜鳥教程
Springboot注解
Mybatis
Springboot框架
Springboot
UNIXLINUX
SpringBootApplication
python为什么叫爬虫
qpython
我要关灯
我要开灯
客户电话
工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
官方微信
扫码二维码
获取最新动态
返回顶部