首页
语法
变量
函数
技术动态
基础知识库
首页
/
使用urllib庫爬取百度貼吧
python爬取網頁詳細教程,python爬蟲知識點總結(三)urllib庫詳解
一、什么是Urllib? 官方學習文檔:https://docs.python.org/3/library/urllib.html python爬取網頁詳細教程,廖雪峰的網站:https://www.liaoxuefeng.com/wiki/0014316089557264a6b348958f449949df42a6d3a2e542c000/001432002680493d1babda364904ca0a6e28
时间:2023-12-06 | 阅读:40
node 爬蟲,爬蟲-3.urllib請求
urllib模塊基本介紹 ??所謂網頁抓取,就是把URL地址中指定的網絡資源從網絡流中讀取出來,保存到本地。 在Python中有很多庫可以用來抓取網頁,我們先學習urllib。 urllib2 在 python3.x 中被改為urllib.request urlopen() ??urllib.request.urlopen(url, d
时间:2023-10-18 | 阅读:23
阅读排行
2751℃
1
如何防止应用程序泄密?
2746℃
2
AlertDialog禁止返回键
2565℃
3
linux中MySQL密码的恢复方...
2502℃
4
node.js当中net模块的简单...
2253℃
5
我的高质量软件发布心得
2184℃
6
从源码角度看Spark on yar...
2034℃
7
在linux云服务器上运行Jar...
1610℃
8
codevs1521 华丽的吊灯
猜你喜欢
《HTML5和JavaScript Web应用开发》——第 2 章 移动Web 2.1移动优先
Linux路由应用-使用策略路由实现访问控制
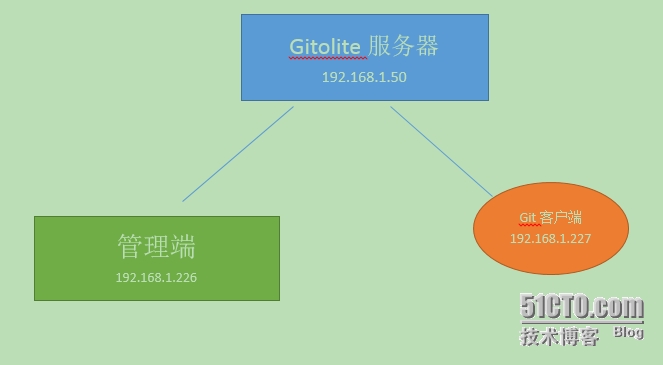
ubuntu Gitolite管理git server代码库权限
杂货 - 收藏集 - 掘金
用JS写的无缝滚动特效
centos7不中断执行命令
Android UI库书签
【iCore1S 双核心板_FPGA】例程十:乘法器实验——乘法器的使用
洛谷——P1478 陶陶摘苹果(升级版)
Apache2月9日邮件:Tomcat请求漏洞(Request Smuggling)
高级文件系统
涉及反射/内省/泛型的优化实践
热门标签
python3
Spring boot
python有什么用
python和java
java
Springboot教程
python编程
Leetcode
python爬蟲教程
python菜鳥教程
Springboot注解
Mybatis
Springboot框架
Springboot
UNIXLINUX
SpringBootApplication
python为什么叫爬虫
qpython
我要关灯
我要开灯
客户电话
工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
官方微信
扫码二维码
获取最新动态
返回顶部