首页
语法
变量
函数
技术动态
基础知识库
首页
/
sparksql调优
如何优化sql,spark sql 性能优化
一 设置shuffle的并行度 我们可以通过属性spark.sql.shuffle.partitions设置shuffle并行度 二 Hive数据仓库建设的时候,合理设置数据类型,比如你设置成INT的就不要设置成BIGINT,减少数据类型不必要的内存开销 三 SQL优化 四 并行的处理查询结果 对于S
时间:2023-09-24 | 阅读:25
spark,spark 性能优化
一 性能优化点 # 提升并行度,就意味着有更多的分区,也就意味着有更多的task.当然不是越多越好,结合实际情况 spark,# 对多次使用的RDD进行缓存,可以减少不必要的计算 # 使用序列化的持久化机制,这样可以减少内存占用以及GC开销 # Java虚拟
时间:2023-09-24 | 阅读:26
hive sql 优化
Hive是将符合SQL语法的字符串解析生成可以在Hadoop上执行的MapReduce的工具。 使用Hive尽量按照分布式计算的一些特点来设计sql,和传统关系型数据库有区别, 所以需要去掉原有关系型数据库下开发的一些固有思维。 基本原则: 1:尽量尽早地过滤数据
时间:2023-09-05 | 阅读:84
阅读排行
2720℃
1
如何防止应用程序泄密?
2718℃
2
AlertDialog禁止返回键
2537℃
3
linux中MySQL密码的恢复方...
2377℃
4
node.js当中net模块的简单...
2225℃
5
我的高质量软件发布心得
2159℃
6
从源码角度看Spark on yar...
2013℃
7
在linux云服务器上运行Jar...
1574℃
8
codevs1521 华丽的吊灯
猜你喜欢
用JS写的无缝滚动特效
HDU 6178 Monkeys
BigDecimal与Long、int之间的互换
苏宁易购唱共享之歌,共享干衣、共享数据、共享快递盒为哪般?
编写了一个文件编码转换器。
从源码角度看Spark on yarn client cluster模式的本质区别
jquery源码抽丝剥茧--把jquery最小化
C++ 以对象管理资源
BZOJ 4421: [Cerc2015] Digit Division 排列组合
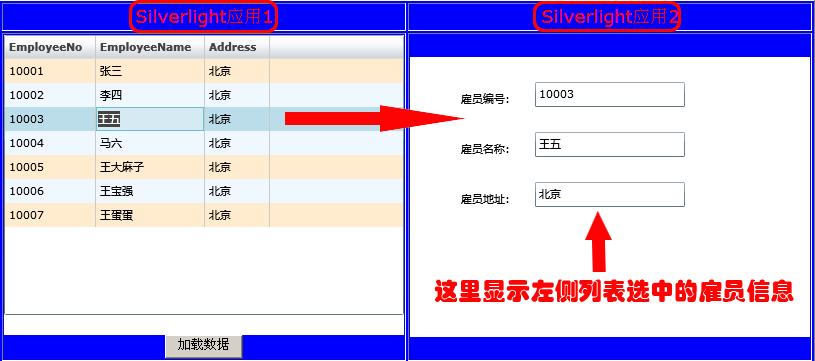
在两个Silverlight应用间数据通信(包括与Flash通信)
eclipse-Java compiler level does not match the version of the installed Java pro
货车运输 vijos 1843 NOIP2013 D1T3 最大生成树,并查集,(伪·LCA)
热门标签
python3
Spring boot
python有什么用
python和java
java
Springboot教程
python编程
Leetcode
python爬蟲教程
python菜鳥教程
Springboot注解
Mybatis
Springboot框架
Springboot
UNIXLINUX
SpringBootApplication
python为什么叫爬虫
qpython
我要关灯
我要开灯
客户电话
工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
官方微信
扫码二维码
获取最新动态
返回顶部











![BZOJ 4421: [Cerc2015] Digit Division 排列组合](/upload/rand_pic/2-1461.jpg)