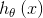长期以来,我避免在数据新闻工作中使用GNU Make,部分原因是该文档过于晦涩,以至于我看不到Make(提取提取转换加载(ETL)流程之一)如何对我的日常工作有所帮助。日数据报告。 但是今年,要构建The Money Game ,我每天需要加载1.4GB的伊利诺伊州政治捐款和支出数据,而ETL流程要花费数小时,所以我给了Make一个机会。
现在,相同的过程不到30分钟。
这是全部的工作原理,但是如果您想直接跳到代码, 我们已经在这里开源了 。
从根本上说,Make让您说:
这种“从文件Y开始获取文件X”的模式是数据新闻业的日常现实,使用Make加载政治捐款和支出数据是一个很好的用例。 数据相当大,可以通过慢速的FTP服务器进行访问,格式古怪,完整性问题足以使事情变得有趣,并且需要与旧版代码库兼容。 为了解决这个问题,我需要从头开始。
我们使用的财务披露数据来自伊利诺伊州选举委员会,但伊利诺伊州阳光项目已发布了开源代码(不再可用)来处理ETL流程和筹款计算。 使用他们的代码,ETL流程在健壮的硬件上运行大约需要两个小时,而在我们的服务器上则花费了五个小时以上,有时由于我从未完全理解的原因,它可能会失败。 我需要它更好地工作和更快地工作。
该过程如下所示:
清理步骤必须在将任何数据加载到数据库之前进行,因此我们可以利用PostgreSQL高效的导入工具。 如果单行在期望整数的列中有一个字符串,则整个操作将失败。
GNU Make非常适合此任务。 Make的模型围绕描述ETL流程应生成的输出文件以及从一组原始源文件到一组输出文件所需的操作而构建。
与任何ETL流程一样,目标是保留原始数据,使操作保持原子性并提供可以反复运行的简单且可重复的流程。
让我们检查一些步骤:
看一下这个片段,它可以是一个独立的Makefile:
data/download/%.txt :
aria2c -x5 -q -d data/download --ftp-user="$(ILCAMPAIGNCASH_FTP_USER)" --ftp-passwd="$(ILCAMPAIGNCASH_FTP_PASSWD)"
ftp://ftp.elections.il.gov/CampDisclDataFiles/$*.txtdata/processed/%.csv : data/download/%.txt
python processors/clean_isboe_tsv.py $< $* > $@ 此代码段首先通过FTP下载文件,然后使用Python处理该文件。 例如,如果“ Expenditures.txt”是我的源数据文件之一,则可以运行make data/processed/Expenditures.csv来下载和处理支出数据。
这里有两件事要注意。
首先是我们使用Aria2处理FTP职责。 该脚本的早期版本使用了其他的FTP客户端,这些客户端的速度很慢或难以使用。 经过反复试验,我发现Aria2的工作比lftp(快速但繁琐)或旧的ftp(慢而繁琐)更好。 我还发现一些咒语使下载时间从大约一个小时减少到不到20分钟。
其次,清理步骤对于该数据集至关重要。 它使用一个简单的基于类的Python验证方案,您可以在此处看到 。 需要注意的重要一点是,尽管Python通常很慢,但Python 3足够快。 而且,只要您仅逐行处理,而不会在内存中累积任何对象或进行任何额外的磁盘写入操作,即使在资源匮乏的机器(例如ProPublica集群中的服务器)上,性能也不错。怪癖。
Make是围绕文件输入和输出构建的。 但是,如果我们的数据无论是在文件和数据库中的表会发生什么? 这是我将数据库表集成到Makefile中学习到的一些宝贵技巧:
每个表/转换一个SQL文件 :Make既喜欢文件又喜欢简单的映射,因此我为每个表或任何其他原子表级操作创建了具有模式定义的单个文件。 表名称与SQL文件名匹配,SQL文件名与源数据文件名匹配。 您可以在这里看到它们。
使用退出代码魔术使表格看起来像要制作的文件 :DataMade的Hannah Cushman和Forrest Gregg 向我介绍了Twitter上的此技巧 。 如果在表级命令之前加上发出适当退出代码的命令,则可以使Make像对待文件一样对待表。 如果存在表,则发出成功的代码。 如果不是,则发出错误。
除此之外,加载仅包含高效的PostgreSQL \copy命令。 尽管COPY命令更加高效,但它在Amazon RDS中不能很好地发挥作用。 即使ProPublica转移到其他数据库提供者,我也将继续使用\copy进行可移植性,除非提高性能对任务至关重要。
最后一个问题是:加载步骤将数据导入到称为raw的PostgreSQL模式中,以便我们可以进一步对数据进行完全转换。 Postgres的模式提供一个单一的数据库内的数据分段的有效途径-而不是用像桌的单一命名空间raw_contributions和clean_contributions ,你可以让事情变得简单,并具有几乎类似文件夹的结构清除raw.contributions和public.contributions 。
由于可用性和性能的原因,伊利诺伊州Sunshine代码还重命名了列并略微重塑了数据。 列别名对最终用户很有用,并且需要中间表才能与旧版代码兼容。
在这种情况下,加载程序将导入到一个称为raw的模式中,该模式与人类尽可能接近源数据。
然后,通过创建原始表的实例化视图来转换数据,该视图重命名列并进行一些轻松的后处理。 这足以满足我们的目的,但是可以进行更精细的转换,而不会牺牲清晰度或模糊源数据。 以下是这些视图定义之一的摘要:
CREATE MATERIALIZED VIEW d2_reports ASSELECTid as id,committeeid as committee_id,fileddocid as filed_doc_id,begfundsavail as beginning_funds_avail,indivcontribi as individual_itemized_contrib,indivcontribni as individual_non_itemized_contrib,xferini as transfer_in_itemized,xferinni as transfer_in_non_itemized,# ….FROM raw.d2totals
WITH DATA;这些转换非常简单,但是对于最终用户而言,简单地使用更具可读性的列名是一个很大的改进。
与表架构定义一样,每个表都有一个文件描述转换后的视图。 我们使用实例化视图,因为它是廉价的并且比传统SQL视图要快,所以它们还是本质上是标准SQL视图的持久缓存版本。
您会注意到我们使用的环境变量在运行命令时会内联扩展。 这对于调试很有用,并有助于可移植性。 但这不是一个好主意,如果您认为日志文件或终端输出可能会受到威胁,或者不知道这些机密的人可以访问日志或共享系统。 为了提高安全性,您可以使用PostgreSQL pgconf文件之类的系统并删除环境变量引用。
我在Make上唯一的经验是15年前参加了计算数学课程,这是一个令人沮丧且解释不充分的脚注。 晦涩的文档,我在学校的糟糕经历以及一个已经可靠的框架相结合,使我远离了。 另外,我的shell脚本和Python Fabric / Invoke代码在基于可靠的数据处理管道方面做得很好,这些管道基于我正在做的小型,快速周转项目的相同原理。
但是在为该项目尝试Make之后,我对结果印象深刻。 简洁明了。 它可以执行原子操作,但是会以处理部分构建的简单方式奖励它们,这在开发过程中非常重要,当您真的不想重复昂贵的操作来测试单个组件时。 结合PostgreSQL快速导入工具,模式和实例化视图,我能够在很短的时间内加载数据。 同样重要的是,新过程的性能对变化的系统资源不太敏感。
如果您想开始使用Make,这里还有一些其他资源:
最后,最佳的构建/处理系统是任何永不更改源数据,清晰显示转换,使用版本控制并且可以轻松地反复运行的系统。 Grunt,Gulp,Rake,Make,Invoke……您可以选择。 只要您喜欢并认真使用它,您的工作就会受益。
ProPublica是获得普利策奖的调查性新闻编辑室。 订阅他们的时事通讯 。
经ProPublica.org许可转载。 知识共享许可(CC BY-NC-ND 3.0)
href="https://www.propublica.org/nerds/gnu-make-illinois-campaign-finance-data-david-eads-propublica-illinois" rel="canonical">翻译自: https://opensource.com/article/18/8/how-propublica-illinois-uses-gnu-make
版权声明:本站所有资料均为网友推荐收集整理而来,仅供学习和研究交流使用。

工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态