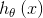要開始系統地學習 NLP 課程?cs224d,今天先來一個課程概覽。
課程一共有16節,先對每一節中提到的模型,算法,工具有個總體的認識,知道都有什么,以及它們可以做些什么事情。
NLP:
Natural Language Processing (自然語言處理)的目的,就是讓計算機能‘懂得’人類對它‘說’的話,然后去執行一些指定的任務。
Easy:
? Spell Checking--拼寫檢查
? Keyword Search--關鍵詞提取&搜索
? Finding Synonyms--同義詞查找&替換
Medium:
? Parsing information from websites, documents, etc.--從網頁中提取有用的信息例如產品價格,日期,地址,人名或公司名等
Hard:
? Machine Translation (e.g. Translate Chinese text to English)--自動的或輔助的翻譯技術
? Semantic Analysis (What is the meaning of query statement?)--市場營銷或者金融交易領域的情感分析
? Coreference (e.g. What does "he" or "it" refer to given a document?)
? Question Answering (e.g. Answering Jeopardy questions).--復雜的問答系統
Deep Learning:
深度學習是機器學習的一個分支,嘗試自動的學習合適的特征及其表征,嘗試學習多層次的表征以及輸出。
它在NLP的一些應用領域上有顯著的效果,例如機器翻譯,情感分析,問答系統等。
和傳統方法相比,深度學習的重要特點,就是用向量表示各種級別的元素,傳統方法會用很精細的方法去標注,深度學習的話會用向量表示 單詞,短語,邏輯表達式和句子,然后搭建多層神經網絡去自主學習。
這里有簡明扼要的對比總結。
向量表示:
詞向量:
One-hot 向量:
記詞典里有 |V| 個詞,每個詞都被表示成一個 |V| 維的向量,設這個詞在字典中相應的順序為 i,則向量中 i 的位置上為 1,其余位置為 0.
詞-文檔矩陣:
構建一個矩陣 X,每個元素 Xij 代表 單詞 i 在文檔 j 中出現的次數。
詞-詞共現矩陣:
構建矩陣 X,每個元素 Xij 代表 單詞 i 和單詞 j 在同一個窗口中出現的次數。
word2vec:
word2vec是一套能將詞向量化的工具,Google在13年將其開源,代碼可以見?https://github.com/burness/word2vec?,它將文本內容處理成為指定維度大小的實數型向量表示,并且其空間上的相似度可以用來表示文本語義的相似度。
Word2vec的原理主要涉及到統計語言模型(包括N-gram模型和神經網絡語言模型),continuousbag-of-words 模型以及 continuous skip-gram 模型。


其神經網絡的目的是要學習:


CBOW是通過上下文來預測中間的詞,如果窗口大小為k,則模型預測:

其神經網絡就是用正負樣本不斷訓練,求解輸出值與真實值誤差,然后用梯度下降的方法求解各邊權重參數值的。

結構為:

應用:
Glove:
Global Vectors 的目的就是想要綜合前面講到的 word-document 和 word-windows 兩種表示方法,做到對word的表示即 sementic 的表達效果好,syntactic 的表達效果也好:


softmax:
softmax 模型是 logistic 模型在多分類問題上的推廣, logistic 回歸是針對二分類問題的,類標記為{0, 1}。在softmax模型中,label可以為k個不同的值。
Neural Networks:
神經網絡是受生物學啟發的分類器,可以學習更復雜的函數和非線性決策邊界。
UFLDL:Unsupervised Feature Learning and Deep Learning
Gradient Checking(梯度檢測):
反向傳播因為細節太多,往往會導致一些小的錯誤,尤其是和梯度下降法或者其他優化算法一起運行時,看似每次 J(Θ) 的值在一次一次迭代中減小,但神經網絡的誤差可能會大過實際正確計算的結果。
針對這種小的錯誤,有一種梯度檢驗(Gradient checking)的方法,通過數值梯度檢驗,你能肯定確實是在正確地計算代價函數(Cost Function)的導數。
GC需要對params中的每一個參數進行check,也就是依次給每一個參數一個極小量。
overfitting:

就是訓練誤差Ein很小,但是實際的真實誤差就可能很大,也就是模型的泛化能力很差(bad generalization)
發生overfitting 的主要原因是:(1)使用過于復雜的模型(dvc 很大);(2)數據噪音;(3)有限的訓練數據。
regularization:
為了提高模型的泛化能力,最常見方法便是:正則化,即在對模型的目標函數(objective function)或代價函數(cost function)加上正則項。
Tensorflow:
Tensorflow 是 python 封裝的深度學習庫,非常容易上手,對分布式系統支持比 Theano 好,同時還是 Google 提供資金研發的
在Tensorflow里:
TensorFlow 算是一個編程系統,它使用圖來表示計算任務,圖中的節點被稱之為operation(可以縮寫成op),一個節點獲得0個或者多個張量(tensor,下文會介紹到),執行計算,產生0個或多個張量。
RNN:
在深度學習領域,傳統的前饋神經網絡(feed-forward neural net,簡稱FNN)具有出色的表現。
在前饋網絡中,各神經元從輸入層開始,接收前一級輸入,并輸入到下一級,直至輸出層。整個網絡中無反饋,可用一個有向無環圖表示。
不同于傳統的FNNs,RNNs引入了定向循環,能夠處理那些輸入之間前后關聯的問題。定向循環結構如下圖所示:


傳統的RNN在訓練 long-term dependencies 的時候會遇到很多困難,最常見的便是 vanish gradient problem。期間有很多種解決這個問題的方法被發表,大致可以分為兩類:一類是以新的方法改善或者代替傳統的SGD方法,如Bengio提出的 clip gradient;另一種則是設計更加精密的recurrent unit,如LSTM,GRU。
LSTMs:
長短期內存網絡(Long Short Term Memory networks)是一種特殊的RNN類型,可以學習長期依賴關系。
LSTMs 刻意的設計去避免長期依賴問題。記住長期的信息在實踐中RNN幾乎默認的行為,但是卻需要很大的代價去學習這種能力。
LSTM同樣也是鏈式結構,但是重復的模型擁有不同的結構,它與單個的神經網層不同,它有四個, 使用非常特別方式進行交互。

GRUs:
Gated Recurrent Unit 也是一般的RNNs的改良版本,主要是從以下兩個方面進行改進。
一是,序列中不同的位置處的單詞(已單詞舉例)對當前的隱藏層的狀態的影響不同,越前面的影響越小,即每個前面狀態對當前的影響進行了距離加權,距離越遠,權值越小。
二是,在產生誤差error時,誤差可能是由某一個或者幾個單詞而引發的,所以應當僅僅對對應的單詞weight進行更新。

Recursive neural networks:
和前面提到的 Recurrent Neural Network 相比:
recurrent: 時間維度的展開,代表信息在時間維度從前往后的的傳遞和積累,可以類比markov假設,后面的信息的概率建立在前面信息的基礎上。
recursive: 空間維度的展開,是一個樹結構,就是假設句子是一個樹狀結構,由幾個部分(主語,謂語,賓語)組成,而每個部分又可以在分成幾個小部分,即某一部分的信息由它的子樹的信息組合而來,整句話的信息由組成這句話的幾個部分組合而來。
Convolutional neural networks:
卷積神經網絡是一種特殊的深層的神經網絡模型,它的特殊性體現在兩個方面,一方面它的神經元間的連接是非全連接的, 另一方面同一層中某些神經元之間的連接的權重是共享的(即相同的)。它的非全連接和權值共享的網絡結構使之更類似于生物 神經網絡,降低了網絡模型的復雜度,減少了權值的數量。

Seq2Seq:
seq2seq 是一個機器翻譯模型,解決問題的主要思路是通過深度神經網絡模型(常用的是LSTM,長短記憶網絡,一種循環神經網絡)將一個作為輸入的序列映射為一個作為輸出的序列,這一過程由編碼輸入與解碼輸出兩個環節組成。

Encoder:

Decoder:

注意機制是Seq2Seq中的重要組成部分:

應用領域有:機器翻譯,智能對話與問答,自動編碼與分類器訓練等。
Large Scale DL:
為了讓 Neural Networks 有更好的效果,需要更多的數據,更大的模型,更多的計算。
Jeff Dean On Large-Scale Deep Learning At Google
dynamic memory network (DMN):
利用 dynamic memory network(DMN)框架可以進行 QA(甚至是 Understanding Natural Language)。
這個框架是由幾個模塊組成,可以進行 end-to-end 的 training。其中核心的 module 就是Episodic Memory module,可以進行 iterative 的 semantic + reasoning processing。

有了一個總體的了解,看的熱血沸騰的,下一次開始各個擊破!
Day 1.?深度學習與自然語言處理 主要概念一覽
Day 2.?TensorFlow 入門
Day 3.?word2vec 模型思想和代碼實現
Day 4.?怎樣做情感分析
Day 5.?CS224d-Day 5: RNN快速入門
Day 6.?一文學會用 Tensorflow 搭建神經網絡
Day 7.?用深度神經網絡處理NER命名實體識別問題
Day 8.?用 RNN 訓練語言模型生成文本
Day 9.?RNN與機器翻譯
Day 10.?用 Recursive Neural Networks 得到分析樹
Day 11.?RNN的高級應用
版权声明:本站所有资料均为网友推荐收集整理而来,仅供学习和研究交流使用。

工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态