查看表結構索引
Among many different things that can affect SQL Server performance, some are more significant than others. In addition, some changes can be relatively easy to implement, but others are quite painfully:
db2查看索引是否失效, 在可能影響SQL Server性能的許多不同因素中,某些因素比其他因素更為重要。 此外,某些更改可能相對容易實現,但其他更改則非常痛苦:
Through this series we are going to evaluate end to end indexing strategy that helps you improve SQL Server overall performance without affecting others aspects of production systems, like data consistency, client applications behavior or maintenance routines.
通過本系列文章,我們將評估端到端索引策略,該策略可幫助您提高SQL Server的整體性能而又不影響生產系統的其他方面,例如數據一致性,客戶端應用程序行為或維護例程。
靜態查找表和動態查找表的區別,Before SQL Server 2014 we had only two options:a table could be a heap or a b-tree. Now data can also be stored inside in-memory tables or in form of columnstore indexes. Due to the fact that these structures are completely different, the very first step of index strategy is to choose the correct table structure. To help you take informed decision, I’m going to compare available options.
在SQL Server 2014之前,我們只有兩個選擇:表可以是堆或b樹。 現在,數據也可以存儲在內存表中或以列存儲索引的形式存儲。 由于這些結構完全不同, 因此索引策略的第一步就是選擇正確的表結構 。 為了幫助您做出明智的決定,我將比較可用的選項。
Test environment 測試環境Let’s start with a sample database:
查找表結構用以下哪一項? 讓我們從一個示例數據庫開始:
USE [master];
GOIF DATABASEPROPERTYEX (N'Indices', N'Version') > 0
BEGINALTER DATABASE Indices SET SINGLE_USERWITH ROLLBACK IMMEDIATE;DROP DATABASE Indices;
END
GOCREATE DATABASE IndicesCONTAINMENT = NONEON??PRIMARY
( NAME = N'Indices',
FILENAME = N'e:\SQL\Indices.mdf' ,
SIZE = 500MB , FILEGROWTH = 50MB )LOG ON
( NAME = N'Indices_log', FILENAME = N'e:\SQL\Indices_log.ldf' ,
SIZE = 250MB , FILEGROWTH = 25MB )
GOALTER DATABASE Indices SET RECOVERY SIMPLE;
GOUSE Indices
GOIn addition to this, we will need a tool that allows us to simulate and measure user activity(all we need is the ability to execute queries simultaneously and monitor execution times as well as number of read/write pages). You will find a lot of tools such as those in the Internet – I chose SQLQueryStress, a free tool made by Adam Mechanic.
除此之外,我們將需要一個工具來模擬和衡量用戶活動(我們需要的是能夠同時執行查詢并監視執行時間以及讀/寫頁數的功能)。 您會發現很多工具,例如Internet上的工具-我選擇了Adam Mechanic免費提供SQLQueryStress工具。
查找表結構用什么語句?A table without clustered index is a heap — just a set of unordered pages. This is the simplest data structure available, but as you will see definitely not the best one:
沒有聚集索引的表就是一個堆-只是一組無序的頁面。 這是可用的最簡單的數據結構,但是您肯定不會看到最好的數據結構:
?
CREATE TABLE dbo.Heap(
id ?????????? INT ??????????IDENTITY(1,1),
fixedColumns CHAR(200)????CONSTRAINT Col2Default DEFAULT 'This column mimics
all fixed-legth columns',
varColumns ??VARCHAR(200) CONSTRAINT Col3Default DEFAULT 'This column mimics
all length-legth columns',);
GO??Let’s check how long it takes to load 100000 rows into this table using 50 concurrent sessions — for this purpose I’m going to execute simple INSERT INTO dbo.Heap DEFAULT VALUES; statement with number of iteration set to 2000 and number of threads to 50.
innodb索引結構、 讓我們檢查一下使用50個并發會話將100000行加載到該表中需要多長時間-為此,我將執行簡單的INSERT INTO dbo。 迭代次數設置為2000,線程數設置為50的語句。
On my test machine (SQL Server 2014, Intel Pentium i7 with SSD drive), it took 18 seconds, in average. As a result we got these 3300 pages of table:
在我的測試機器(SQL Server 2014,帶SSD驅動器的Intel Pentium i7)上,平均花費了18秒。 結果,我們得到了3300頁的表格:
?
SELECT index_type_desc,avg_page_space_used_in_percent
,avg_fragment_size_in_pages,page_count,record_count,forwarded_record_count,
avg_record_size_in_bytesFROM sys.dm_db_index_physical_stats
(db_id(), OBJECT_ID('dbo.Heap'), NULL, NULL, 'detailed');
GO;
-------------------------------------------------------------------------------------
HEAP 97,2869038794168 300,090909090909 3301 100000 0 258Of course, because there is no ordering whatsoever, the only way to get a row from this table is through a scan:
當然,由于根本沒有排序,因此從該表中獲取行的唯一方法是通過掃描:
?
SET STATISTICS IO ON;SELECT *
FROM??dbo.Heap
WHERE id=2345;
GO
----------------------------------------------------------------------------------------------------------
(1 row(s) affected)
Table 'Heap'. Scan count 1, logical reads 3301, physical reads 0, read-ahead reads 0, lob logical reads 0,
lob physical reads 0, lob read-ahead reads 0.Not only SELECT performance is bad, UPDATEs against heaps are also really slow. In order to see it we need two queries: the first one will return some numbers and will be used for parameter substation, the second one will be executed in 5 concurrent sessions:
不僅SELECT性能很差,而且針對堆的UPDATE確實也很慢。 為了查看它,我們需要兩個查詢:第一個查詢將返回一些數字并將用于參數變電站,第二個查詢將在5個并發會話中執行:
?
SELECT 9 AS nr
UNION
SELECT 13
UNION
SELECT 17
UNION
SELECT 25
UNION
SELECT 29;UPDATE dbo.Heap
SET varColumns = REPLICATE('a',200)
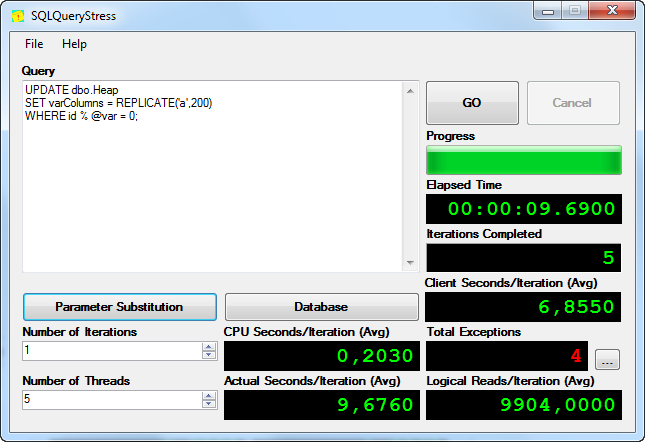
WHERE id % @var = 0;The results are shown in the picture below (4 noticed exceptions were due to deadlocks):
結果如下圖所示(4個異常是由于死鎖引起的):
Altogether 7 700 rows were modified, it means that we achieved about 800 modifications per second.
總共修改了7700行,這意味著我們每秒實現了約800次修改 。
Not only UPDATEs are slow, but they can have a side effect that will affect the performance of queries and will last till the heap is rebuilt. Now I’m talking about forwarded records (if there is not enough space on a page to store new version of a record, the part of it will be saved on a different page, and only forwarding pointer to this page will be stored with the remaining part of this record). In this case more than 3000 forwarded records were created:
不僅UPDATE的速度很慢,而且它們還會產生副作用,這會影響查詢的性能并持續到重建堆為止。 現在,我談論的是轉發記錄(如果頁面上沒有足夠的空間來存儲記錄的新版本,則記錄的一部分將保存在其他頁面上,并且僅指向該頁面的轉發指針將與該記錄的其余部分)。 在這種情況下,創建了3000多個轉發記錄:
?
SELECT index_type_desc,avg_page_space_used_in_percent
,avg_fragment_size_in_pages,page_count,record_count,forwarded_record_count,
avg_record_size_in_bytesFROM sys.dm_db_index_physical_stats
(db_id(), OBJECT_ID('dbo.Heap'), NULL, NULL, 'detailed');
----------------------------------------------------------------------------------------
HEAP 96,9105263157895 316,090909090909 3477 103160 3160 262,446The remaining operations, DELETEs, also have unwanted side effects — space taken by deleted records will not be reclaim automatically:
其余操作DELETE也會產生有害的副作用-刪除的記錄所占用的空間將不會自動回收:
?
DELETE??dbo.Heap
WHERE id % 31 = 0;SELECT index_type_desc,avg_page_space_used_in_percent
,avg_fragment_size_in_pages,page_count,record_count,forwarded_record_count,
avg_record_size_in_bytesFROM sys.dm_db_index_physical_stats
(db_id(), OBJECT_ID('dbo.Heap'), NULL, NULL, 'detailed');
GO
----------------------------------------------------------------------------------------
HEAP 93,8075858660736 316,090909090909 3477 99827 3052 262,461At this point the only way of reclaiming this space and getting rid of forwarded records is to rebuild a table:
此時,回收此空間并擺脫轉發記錄的唯一方法是重建表:
?
ALTER TABLE dbo.Heap
REBUILD;SELECT index_type_desc,avg_page_space_used_in_percent
,avg_fragment_size_in_pages,page_count,record_count,forwarded_record_count,
avg_record_size_in_bytesFROM sys.dm_db_index_physical_stats
(db_id(), OBJECT_ID('dbo.Heap'), NULL, NULL, 'detailed');
----------------------------------------------------------------------------------------
HEAP 97,7820607857672 195,647058823529 3326 96775 0 270,076Because of suboptimal SELECT performance, and side effects of UPDATE and DELETE statements, heaps are sometimes used for logging and stage tables — in first case, rows are almost always only inserted into a table, in the second one we try maximize data load by inserting rows into a heap and after moving them to a destination, indexed table. But even for those scenarios heaps are not necessary the best (more on this topic in upcoming articles). So, the first step our indexing strategy is to find heaps. Quite often these tables will be unused, so they will have no or minimal impact on performance. This is why you should concentrate on active heaps — one of the standard ways of finding them in current database is to execute this query:
由于SELECT性能欠佳,以及UPDATE和DELETE語句的副作用,因此有時會將堆用于日志記錄和階段表-在第一種情況下,行幾乎總是只插入到表中,在第二種情況下,我們嘗試通過插入來最大化數據負載行到堆中,然后將它們移到目標索引表中。 但是即使對于那些場景,也不一定是最好的堆(有關更多信息,請參見后續文章)。 因此,我們的索引策略的第一步是查找堆。 這些表經常不被使用,因此它們對性能沒有影響或影響很小。 這就是為什么您應該專注于活動堆的原因-在當前數據庫中查找活動堆的標準方法之一是執行以下查詢:
?
SELECT t.name, ius.user_seeks, ius.user_scans, ius.user_lookups, ius.user_updates,
ius.last_user_scanFROM sys.indexes i
INNER JOIN sys.objects o ON i.object_id = o.object_id
INNER JOIN sys.tables t ON o.object_id = t.object_id
INNER JOIN sys.partitions p ON i.object_id = p.object_id AND i.index_id = p.index_id
LEFT OUTER JOIN sys.dm_db_index_usage_stats ius ON i.object_id = ius.object_id AND i.index_id = ius.index_id
WHERE i.type_desc = 'HEAP' AND COALESCE(ius.user_seeks, ius.user_scans, ius.user_lookups, ius.user_updates) IS NOT
NULL AND o.is_ms_shipped = 0 AND o.type <> 'S';
----------------------------------------------------------------
Heap 0 1 0 0 2014-09-24 15:42:38.923With this list in hand you should start asking serious question why these tables are heaps. And if no excuses were given, covert them into different structures.
有了這個列表,您應該開始問一個嚴肅的問題,為什么這些表是堆。 如果沒有借口,則將其隱藏為不同的結構。
In the next article two new table structures (in-memory tables and columnstore indexes) will be described and compared with heaps.
在下一篇文章中,將描述兩個新的表結構(內存表和列存儲索引)并將其與堆進行比較。
翻譯自: https://www.sqlshack.com/index-strategies-part-1-choosing-right-table-structure/
查看表結構索引
版权声明:本站所有资料均为网友推荐收集整理而来,仅供学习和研究交流使用。

工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态










{kind=link}