上一篇主要談了一些基本理念,本篇將談談我個人總結的一些IOCP編程技巧。
?
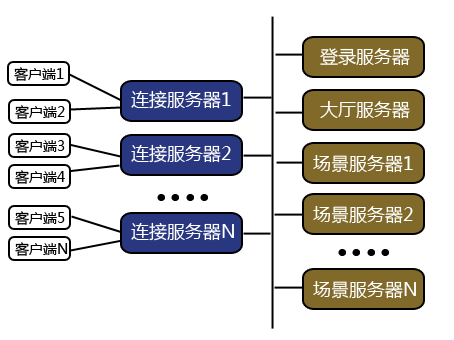
網絡游戲前端服務器的需求和設計
oj編程是什么意思、 首先介紹一下這個服務器的技術背景。在分布式網絡游戲服務器中,前端連接服務器是一種很常見的設計。他的職責主要有:
1. 為客戶端和后端的游戲邏輯服務器提供一個軟件路由 —— 客戶端一旦和前端服務器建立TCP連接以后就可以通過這個連接和后端的游戲服務器進行通訊,而不再需要和后端的服務器再建立新的連接。
2. 承擔來自客戶端的IO壓力 —— 一組典型的網絡游戲服務器需要服務少則幾千多則上萬(休閑游戲則可以多達幾十萬)的游戲客戶端,這個IO處理的負載相當可觀,由一組前端服務器承載這個IO負擔可以有效的減輕后端服務器的IO負擔,并且讓后端服務器也只需要關心游戲邏輯的實現,有效的實現IO和業務邏輯的解耦。
iocp是異步io嗎、 架構如圖:
?
對于網絡游戲來說,客戶端與服務器之間需要進行頻繁的通訊,但是每個數據包的尺寸基本都很小,典型的大小為幾個字節到幾十個字節不等,同時用戶上行的數據量要比下行數據量小的多。不同的游戲類型對延遲的要求不太一樣,FPS類的游戲希望延遲要小于50ms,MMO類型的100~400ms,一些休閑類的棋牌游戲1000ms左右的延遲也是可以接受的。因此,網絡游戲的通訊是以優化延遲的同時又必須兼顧小包的合并以防止網絡擁塞,哪個因素為主則需要根據具體的游戲類型來決定。
技術背景就介紹這些,后面介紹的IOCP連接服務器就是以這些需求為設計目標的。
編程代碼的小結。?
對IOCP服務器框架的考察
在動手實現這個連接服務器之前,我首先考察了一些現有的開源IOCP服務器框架庫,老牌的如ACE,整個庫太多龐大臃腫,代碼也顯老態,無好感。boost.asio據說是個不錯的網絡框架也支持IOCP,我編譯運行了一下他的例子,然后嘗試著閱讀了一下asio的代碼,感覺非常恐怖,完全弄不清楚內部是怎么實現的,于是放棄。asio秉承了boost一貫的變態作風,將C++的語言技巧凌駕于設計和代碼可讀性之上,這是我非常反對的。其他一些不入流的IOCP框架也看了一些,真是寫的五花八門什么樣的實現都有,總體感覺下來IOCP確實不太容易把握和抽象,所以才導致五花八門的實現。最后,還是決定自己重新造輪子。
?
服務框架的抽象
中作小結? 任何的服務器框架從本質上說都是封裝一個事件(Event)消息循環。而應用層只要向框架注冊事件處理函數,響應事件并進行處理就可以了。一般的同步IO處理框架是先收到IO事件然后再進行IO操作,這類的事件處理框架我們稱之為Reactor。而IOCP的特殊之處在于用戶是先發起IO操作,然后接收IO完成的事件,次序和Reactor是相反的,這類的事件處理框架我們稱之為Proactor。從詞根Re和Pro上,我們也可以容易的理解這兩者的差別。除了網絡IO事件之外,服務器應該還可以響應Timer事件及用戶自定義事件。框架做的事情就是把這些事件統統放到一個消息隊列里,然后從隊列中取出事件,調用相應的事件處理函數,如此循環往復。
IOCP為我們提供了一個系統級的消息隊列(稱之為完成隊列),事件循環就是圍繞著這個完成隊列展開的。在發起IO操作后系統會進行異步處理(如果能立刻處理的話也會直接處理掉),當操作完成后自動向這個隊列投遞一條消息,不管是直接處理還是異步處理,最后總會投遞完成消息。
順便提一下:這里存在一個性能優化的機會:當IO操作能夠立刻完成的話,如果讓系統不要再投遞完成消息,那么就可以減少一次系統調用(這至少可以節省幾個微秒的開銷),做法是調用SetFileCompletionNotificationModes(handle, FILE_SKIP_COMPLETION_PORT_ON_SUCCESS),具體的可以查閱MSDN。
ios 子線程、 對于用戶自定義事件可以使用Post來投遞。對于Timer事件,我的做法則是實現一個TimerHeap的數據結構,然后在消息循環中定期檢查這個TimerHeap,對超時的Timer事件進行調度。
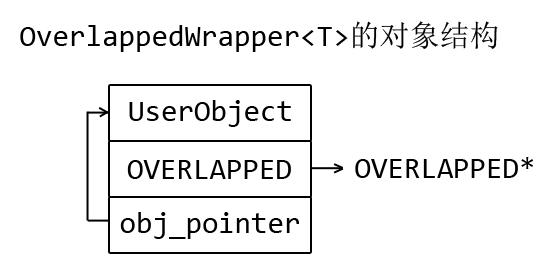
IOCP完成隊列返回的消息是一個OVERLAPPED結構體和一個ULONG_PTR complete_key。complete_key是在用戶將Socket handle關聯到IOCP的時候綁定的,其實用性不是很大,而OVERLAPPED結構體則是在用戶發起IO操作的時候設置的,并且OVERLAPPED結構可以由用戶通過繼承的方式來擴展,因此如何用好OVERLAPPED結構在螺絲殼里做道場,就成了封裝好IOCP的關鍵。
這里,我使用了一個C++模板技巧來擴展OVERLAPPED結構,先看代碼:
{
????virtual?void?Complete(ULONG_PTR?key,?DWORD?size)?=?0;
????virtual?void?OnError(ULONG_PTR?key,?DWORD?error){}
????virtual?void?Destroy()?=?0;
};
struct?Overlapped?:?public?OVERLAPPED
{
????IOCPHandler*?handler;
};
template<class?T>
struct?OverlappedWrapper?:?T
{
????Overlapped?overlap;
????OverlappedWrapper(){
????????ZeroMemory(&overlap,?sizeof(overlap));
????????overlap.handler?=?this;
????}
????operator?OVERLAPPED*(){return?&overlap;}
};
c語言雙重指針。 IOCPHandler是用戶對象的接口,用戶擴展這個接口來實現IO完成事件的處理。然后通過一個OverlappedWrapper<T>的模板類將用戶對象和OVERLAPPED結構封裝成一個對象,T類型就是用戶擴展的對象,由于用戶對象位于OVERLAPPED結構體的前面,因此我們會將OVERLAPPED的指針傳遞給IO操作的API,同時我們在OVERLAPPED結構的后面還放置了一個用戶對象的指針,當GetQueuedCompletionStatus接收到OVERLAPPED結構體指針后,我們通過這個指針就可以找到用戶對象的位置了,然后調用虛函數Complete或者OnError就可以了。
圖解一下對象結構:
ULONG_PTR?key;
Overlapped*?overlap;
BOOL?ret?=?::GetQueuedCompletionStatus(_iocp,?&size,?&key,?(LPOVERLAPPED*)&overlap,?dt);
if(ret){
????if(overlap?==?0){
????????OnExit();
????????break;
????}
????overlap->handler->Complete(key,?size);
????overlap->handler->Destroy();
}
else?{
????DWORD?err?=?GetLastError();
????if(err?==?WAIT_TIMEOUT)
????????UpdateTimer();
????else?if(overlap)?{
????????overlap->handler->OnError(key,?err);
????????overlap->handler->Destroy();
????}
}
? 在這里利用我們利用了C++的多態來擴展OVERLAPPED結構,在框架層完全不用關心接收到的是什么IO事件,只需要應用層自己關心就夠了,同時也避免了使用丑陋的難于擴展的switch..case結構。
ioc注解? 對于異步操作來說,最讓人痛苦的事情就是需要把原本順序邏輯的代碼強行拆分成多塊來回調,這使得代碼中原本蘊含的順序邏輯被打散,并且在各個代碼塊里的上下文變量無法共享,必須另外生成一個對象放置這些上下文變量,而這又引發一個對象生存期管理的問題,對于沒有GC的C++來說尤其痛苦。解決異步邏輯的痛苦之道目前有兩種方案:一種是用coroutine(協作式線程)將異步邏輯變成同步邏輯,在Windows上可以使用Fiber來實現coroutine;另一種方案是使用閉包,閉包原本是函數式語言的特性,在C++里并沒有,不過幸運的是我們可以通過一個稍微麻煩一點的方法來模擬閉包行為。coroutine在解決異步邏輯方面是最拿手的,特別是一個函數里需要依次進行多個異步操作的時候尤其強大(在這種情況下閉包也相形見拙),但是另一方面coroutine的實現比較復雜,線程的手工調度常常把人繞暈,對于IOCP這種異步操作比較有限的場景有點殺雞用牛刀的感覺。因此最后我還是決定使用C++來模擬閉包行為。
這里演示一個典型的異步IO用法,看代碼:?

 一個異步發送的例子:
一個異步發送的例子:{
????const?char*?buf?=?AllocSendBuffer(data,?size);
????struct?SendHandler?:?public?IOCPHandler
????{
????????Client*?client;
????????int?????cookie;
????????virtual?void?Destroy(){????delete?this;?}
????????virtual?void?Complete(ULONG_PTR?key,?DWORD?size){
????????????if(!client->CheckAvaliable(cookie))
????????????????return;
????????????client->EndSend(size);
????????}
????????virtual?void?OnError(ULONG_PTR?key,?DWORD?error){
????????????if(!client->CheckAvaliable(cookie))
????????????????return;
????????????client->OnError(E_SocketError,?error);
????????}
????};
????OverlappedWrapper<SendHandler>*?handler?=?new?OverlappedWrapper<SendHandler>();
????handler->cookie?=?_clientId;
????handler->client?=?this;
????int?sent?=?0;
????Error?e?=?_socket.AsyncSend(buf,?size,?*handler,?&sent);
????if(e.Check()){
????????LogError2("SendAsync?Failed.?%s",?FormatAPIError(_socket.CheckError()).c_str());
????????handler->Destroy();
????????OnError(E_SocketError,?_socket.CheckError());
????}
????else?if(sent?==?size){
????????handler->Destroy();
????????EndSend(size);
????}
}
? 這個例子中,我們在函數內部定義了一個SendHandler對象,模擬出了一個閉包的行為,我們可以把需要用到的上下文變量放置在SendHandler內,當下次回調的時候就可以訪問到這些變量了。本例中,我們在SendHandler里記了一個cookie,其作用是當異步操作返回時,可能這個Client對象已經被回收了,這個時候如果再調用EndSend必然會導致錯誤的結果,因此我們通過cookie來判斷這個Client對象是否是那個異步操作發起時的Client對象。
使用閉包雖然沒有coroutine那樣漂亮的順序邏輯結構,但是也足夠方便你把各個異步回調代碼串起來,同時在閉包內共享需要用到的上下文變量。另外,最新版的C++標準對閉包有了原生的支持,實現起來會更方便一些,如果你的編譯器足夠新的話可以嘗試使用新的C++特性。
?
IO工作線程 單線程vs多線程
在絕大多數講解IOCP的文章中都會建議使用多個工作線程來處理IO事件,并且把工作線程數設置為CPU核心數的2倍。根據我的印象,這種說法的出處來自于微軟早期的官方文檔。不過,在我看來這完全是一種誤導。IOCP的設計初衷就是用盡可能少的線程來處理IO事件,因此使用單線程處理本身是沒有問題的,這可以使實現簡化很多。反之,用多線程來處理的話,必須處處小心線程安全的問題,同時也會涉及到加鎖的問題,而不恰當的加鎖反而會使性能急劇下降,甚至不如單線程程序。有些同學可能會認為使用多線程可以發揮多核CPU的優勢,但是目前CPU的速度足夠用來處理IO事件,一般現代CPU的單個核心要處理一塊千兆網卡的IO事件是綽綽有余的,最多的可以同時處理2塊網卡的IO事件,瓶頸往往在網卡上。如果是想通過多塊網卡提升IO吞吐量的話,我的建議是使用多進程來橫向擴展,多進程不但可以在單臺物理服務器上進行擴展,并且還可以擴展到多臺物理服務器上,其伸縮性要比多線程更強。
當時微軟提出的這個建議我想主要是考慮到在IO線程中除了IO處理之外還有業務邏輯需要處理,使用多線程可以解決業務邏輯阻塞的問題。但是將業務邏輯放在IO線程里處理本身不是一種好的設計模式,這沒有很好的做到IO和業務解耦,同時也限制了服務器的伸縮性。良好的設計應該將IO和業務解耦,使用多進程或者多線程將業務邏輯放在另外的進程或者線程里進行處理,而IO線程只需要負責最簡單的IO處理,并將收到的消息轉發到業務邏輯的進程或者線程里處理就可以了。我的前端連接服務器也是遵循了這種設計方法。
?
關閉發送緩沖區實現自己的nagle算法
IOCP最大的優勢就是他的靈活性,關閉socket上的發送緩沖區就是一例。很多人認為關閉發送緩沖的價值是可以減少一次內存拷貝的開銷,在我看來這只是撿了一粒芝麻而已。主流的千兆網卡其最大數據吞吐量不過區區120MB/s,而內存數據拷貝的吞吐量是10GB/s以上,多一次120MB/s數據拷貝,僅消耗1%的內存帶寬,意義非常有限。
在普通的Socket編程中,我們只有打開nagle算法或者不打開的選擇,策略的選擇和參數的微調是沒有辦法做到的。而當我們關閉發送緩沖之后,每次Send操作一定會等到數據發送到對方的協議棧里并且收到ACK確認才會返回完成消息,這就給了我們一個實現自定義的nagle算法的機會。對于網絡游戲這種需要頻繁發送小數據包,打開nagle算法可以有效的合并發送小數據包以降低網絡IO負擔,但另一方面也加大了延遲,對游戲性造成不利影響。有了關閉發送緩沖的特性之后,我們就可以自行決定nagle算法的實現細節,在上一個send操作沒有結束之前,我們可以決定是立刻發送新的數據(以降低延遲),還是累積數據等待上一個send結束或者超時后再發送。更復雜一點的策略是可以讓服務器容忍多個未結束的send操作,當超出一個閾值后再累積數據,使得在IO吞吐量和延遲上達到一個合理的平衡。
?
發送緩沖的分配策略
前面提到了關閉socket的發送緩沖,那么就涉及到我們自己如何來分配發送緩沖的問題。
一種策略是給每個Socket分配一個固定大小的環形緩沖區。這會存在一個問題:當緩沖區內累積的未發送數據加上新發送的數據大小超出了緩沖區的大小,這個時候就會碰上麻煩,要么阻塞以等待前面的數據發送完畢(但是IO線程不可以阻塞),要么干脆直接把Socket關閉,一個妥協的辦法是盡可能把發送緩沖區設置的大一些,但這又會白白浪費很多內存。
另一種策略是讓所有的客戶端socket共享一個非常大的環形緩沖區,假設我們保留一個1G的內存區域給這個環形緩沖區,每次需要向客戶端發送數據時就從這個環形緩沖區分配內存,當緩沖區分配到底了再繞到開頭重新分配。由于這個緩沖區非常大,1G的內存對千兆網卡來說至少需要花費10s才能發送完,并且在實際應用中這個時間會遠超10s。因此當新的數據從頭開始分配的時候,老的數據早已經發送掉了,不用擔心將老的數據覆蓋,即使碰到網絡阻塞,一個數據包超過10s還未發送掉的話,我們也可以通過超時判斷主動關閉這個socket。
?
socket池和對象池的分配策略
允許socket重用是IOCP另一個優勢,我們可以在server啟動時,根據我們對最大服務人數的預計,將所有的socket資源都分配好。一般來說每個socket必需對應一個client對象,用來記錄一些客戶端的信息,這個對象池也可以和socket綁定并預先分配好。在服務運行前將所有的大塊對象的內存資源都預先分配好,用一個FreeList來做對象池的分配,在客戶端下線之后再將資源回收到池中。這樣就可以避免在服務運行過程中動態的分配大的對象,而一些需要臨時分配的小對象(例如OVERLAPPED結構),我們可以使用諸如tcmalloc之類的通用內存分配器來做,tcmalloc內部使用小對象池算法,其分配性能和穩定性非常好,并且他的接口是非侵入式的,我們仍然可以在代碼里保留malloc/free及new/delete。很多服務在長期運行之后出現運行效率降低,內存占用過大等問題,都跟頻繁的分配和釋放內存導致出現大量的內存碎片有關。所以做好服務器的內存分配管理是至關重要的一環。
?
待續....
?
下一篇將通過幾個壓力測試和profiling的例子,來分析服務器的性能和瓶頸所在,請大家關注。
?













