1.安裝好Scrapy爬蟲框架
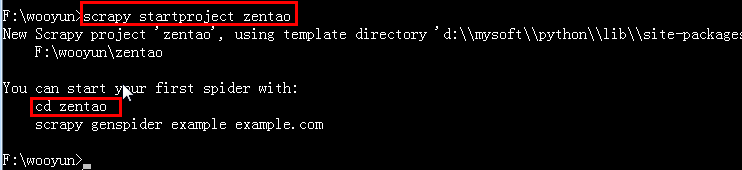
2.切換到F盤的wooyun目錄下執行:scrapy startproject zentao
這個命令會在當前目錄下創建一個新目錄zentao,它的結構如下:
爬蟲python、
3.通過tree /f命令查看目錄結果


這些文件主要是:
- scrapy.cfg: 項目配置文件
- zentao/: 項目python模塊, 呆會代碼將從這里導入
- zentao/items.py: 項目items文件
- zentao/pipelines.py: 項目管道文件
- zentao/settings.py: 項目配置文件
- zentao/spiders: 放置spider的目錄
python寫爬蟲。?
定義Item
Items是將要裝載抓取的數據的容器,它工作方式像python里面的字典,但它提供更多的保護,比如對未定義的字段填充以防止拼寫錯誤。
它通過創建一個scrapy.item.Item類來聲明,定義它的屬性為scrpy.item.Field對象,就像是一個對象關系映射(ORM).
我們通過將需要的item模型化,來控制從dmoz.org獲得的站點數據,比如我們要獲得站點的名字,url和網站描述,我們定義這三種屬性的域。要做到這點,我們編輯在tutorial目錄下的items.py文件,我們的Item類將會是這樣
from scrapy.item import Item, Field
class DmozItem(Item):title = Field() link = Field() ??? desc = Field() 剛開始看起來可能會有些困惑,但是定義這些item能讓你用其他Scrapy組件的時候知道你的 items到底是什么。