首页
语法
变量
函数
技术动态
基础知识库
首页
/
python爬蟲scrapy框架
python爬蟲scrapy框架,python中scrapy框架項目_Python -- Scrapy 框架簡單介紹(Scrapy 安裝及項目創建)
Python -- Scrapy 框架簡單介紹最近在學習python 爬蟲,先后了解學習urllib、urllib2、requests等,后來發現爬蟲也有很多框架,而推薦學習最多就是Scrapy框架了,所以這里我也小試牛刀一下。python爬蟲scrapy框架、開始自己的Scrapy 框架學習之路。一
时间:2023-12-25 | 阅读:38
爬蟲python,Scrapy創建zentao爬蟲
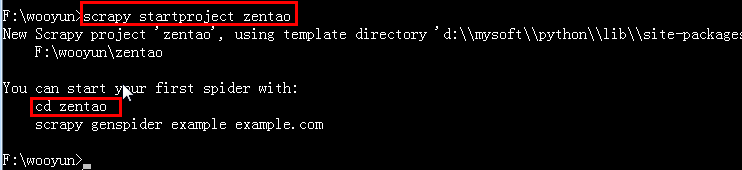
1.安裝好Scrapy爬蟲框架 2.切換到F盤的wooyun目錄下執行:scrapy startproject zentao 這個命令會在當前目錄下創建一個新目錄zentao,它的結構如下: 爬蟲python、 3.通過tree /f命令查看目錄結果 這些文件主要是: scrapy.cfg: 項目配置文件zentao/
时间:2023-11-19 | 阅读:25
scrapy redis,Learning Scrapy筆記(五)- Scrapy登錄網站
摘要:介紹了使用Scrapy登錄簡單網站的流程,不涉及驗證碼破解 簡單登錄 很多時候,你都會發現你需要爬取數據的網站都有一個登錄機制,大多數情況下,都要求你輸入正確的用戶名和密碼。現在就模擬這種情況,在瀏覽器打開網頁:ht
时间:2023-10-06 | 阅读:30
python爬取天氣數據,手把手教你使用Python+scrapy爬取山東各城市天氣預報
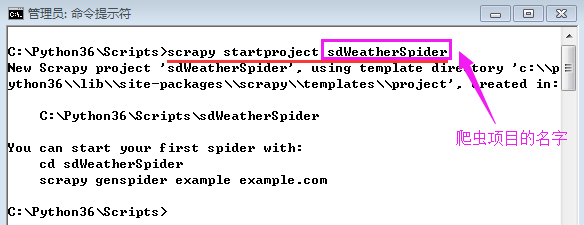
1、在命令提示符環境使用pip install scrapy命令安裝Python擴展庫scrapy,詳見Python使用Scrapy爬蟲框架爬取天涯社區小說“大宗師”全文2、使用下圖中的命令創建爬蟲項目3、進入爬蟲項目文件夾,執行下面的命令創建爬蟲python爬取天氣數據,現在,爬蟲項目
时间:2023-10-04 | 阅读:31
零基礎學python爬蟲,python爬蟲框架源碼_python爬蟲的基本框架
1.爬蟲的基本流程: 零基礎學python爬蟲?通過requests庫的get方法獲得網站的url 瀏覽器打開網頁源碼分析元素節點 通過BeautifulSoup或者正則表達式提取想要的數據 儲存數據到本地磁盤或者數據庫 2.正式開工啦 url = “http://www.jianshu.com” page = reques
时间:2023-10-04 | 阅读:32
python常用框架有哪些,python pipeline框架_爬蟲(十六):Scrapy框架(三) Spider Middleware、Item Pipeli
https://www.xin3721.com/eschool/pythonxin3721/ 1. Spider Middleware Spider Middleware是介入到Scrapy的Spider處理機制的鉤子框架。 當Downloader生成Response之后,Response會被發送給Spider,在發送給Spider之前,Response會首先經過Spider Middlewa
时间:2023-10-02 | 阅读:24
python %什么運算,python快速排序最簡單寫法_面試官:來,這位精神小伙,簡簡單單寫個快速排序吧...
當你的才華還撐不起你的野心時,你應該靜下心去學習 。面試現場,終于到了緊張刺激的手撕代碼環節,你忐忑的心情隨著考官的一句話歸于平靜。python %什么運算、你簡直不敢相信眼前這個穿著格子襯衫,牛仔褲角有些發白,頭發在風中有些凌亂但仍
时间:2023-10-01 | 阅读:23
阅读排行
2751℃
1
如何防止应用程序泄密?
2746℃
2
AlertDialog禁止返回键
2565℃
3
linux中MySQL密码的恢复方...
2502℃
4
node.js当中net模块的简单...
2253℃
5
我的高质量软件发布心得
2184℃
6
从源码角度看Spark on yar...
2034℃
7
在linux云服务器上运行Jar...
1610℃
8
codevs1521 华丽的吊灯
猜你喜欢
ABBYY FineReader中的OCR选项怎样运用好
Android 6.0 设备强制要求开启全盘加密
Nginx站点缓存设置
Atitit .h5文件上传 v3
jenkins的svn路径中文问题
6.9冲刺
Yii2 理解Validator
部署Docker----解决删除none镜像问题
CA的搭建与申请
Servlet JSP : web.xml 配置学习
从地理围栏看物联网安防
PieChart 饼图
热门标签
python3
Spring boot
python有什么用
python和java
java
Springboot教程
python编程
Leetcode
python爬蟲教程
python菜鳥教程
Springboot注解
Mybatis
Springboot框架
Springboot
UNIXLINUX
SpringBootApplication
python为什么叫爬虫
qpython
我要关灯
我要开灯
客户电话
工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
官方微信
扫码二维码
获取最新动态
返回顶部