最近開始學深度學習框架pytorch,從最簡單的卷積神經網絡開始了解pytorch的框架。以下涉及到的代碼完整版請查看https://github.com/XieHanS/CPSC_ECGHbClassify_demo.git
基于pytorch的DL主要分為三個模塊,數據塊,模型塊,和訓練塊。具體如下:
pytorch提供有專門的數據下載,數據處理包,使用這些包可以極大地提高開發效率
torch.utils.data工具包
該包中有兩個常用的類,分別為Dataset和DataLoader
pytorch訓練自己的數據集,Dataset 一個抽象類,抽象類只能作為基類派生新類使用,不能創建抽象類對象。其他數據集需要繼承這個類,并覆寫其中的兩個方法:
__getitem__ 和 __len__
from torch.utils.data import Dataset, DataLoaderclass MyDataset(Dataset):def __init__(self, data, label):self.data = dataself.label = labeldef __getitem__(self, index):return (torch.tensor(self.data[index], dtype=torch.float), torch.tensor(self.label[index], dtype=torch.long))def __len__(self):return len(self.data)調用__getitem__只返回一個樣本,因此需要一個批量讀取的工具,pytorch為我們提供了另外一個類DataLoader。DataLoader 定義一個新的迭代器,實現批量讀取,打亂數據并提供并行加速等功能
loader = torch.utils.data.DataLoader(dataset = datasets, #加載的數據集batch_size = BATCH_SIZE, #批大小shuffle = True, #是否將數據打亂,默認為falsenum_workers=2,#使用多進程加載的進程數,0代表不使用多進程使用的時候只需要調用這兩個類即可
#繼承Dataset類,自定義數據集以及對應的標簽dataset = MyDataset(X_train, Y_train)dataset_test = MyDataset(X_test, Y_test)#裝載數據,實現批量讀取dataloader = DataLoader(dataset, batch_size=batch_size)dataloader_test = DataLoader(dataset_test, batch_size=batch_size, drop_last=False)#訓練模型時候的數據循環for epoch in range(n_epoch):model.train()for batch_idx, batch in enumerate(dataloader):input_x, input_y = tuple(batch)pred = model(input_x)[0]pytorch中自定義的模型往往繼承自nn.Model,包括兩個函數,初始化函數__init__()和forward()。__init__()定義了卷積層和其他層的參數,forward()規定了網絡執行的順序。例如下面的網絡:
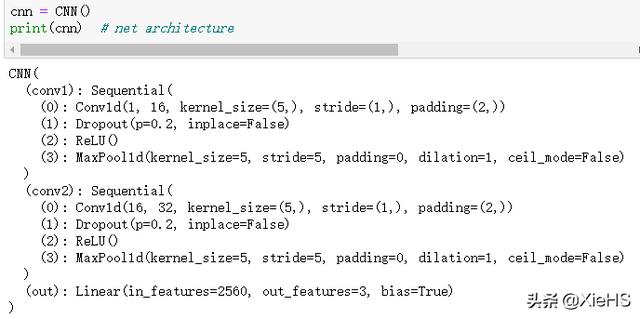
__init__()定義了兩個卷積層conv1和conv2,和一個全連接層out層,兩個卷積層里面分別包含了一維卷積,DropOut,ReLU激活和最大池化層。
deeplearning4j缺點,forward()定義了執行順序。首先conv1,接著conv2,最后out層。由于上下層連接的問題,往往init里面會按照順序撰寫,而真正的執行順序是forward里面的順序。
class CNN(nn.Module): def __init__(self): super(CNN, self).__init__() self.conv1 = nn.Sequential( # input shape (1, 1, 2000) nn.Conv1d( in_channels=1, # input height out_channels=16, # n_filters kernel_size=5, # filter size stride=1, # filter movement/step padding=2, ), # output shape (16, 1, 2000) nn.Dropout(0.2),#扔到0.2 nn.ReLU(), nn.MaxPool1d(kernel_size=5), # choose max value in 1x5 area, output shape (16, 1, 400)2000/5 ) self.conv2 = nn.Sequential( # input shape (16, 1, 400) nn.Conv1d(16, 32, 5, 1, 2),# output shape (32, 1, 400) nn.Dropout(0.2),#扔掉0.2 nn.ReLU(), nn.MaxPool1d(kernel_size=5),# output shape (32, 1, 400/5=80) ) self.out = nn.Linear(32 * 80, 3) # fully connected layer, output 3 classes def forward(self, x): x = self.conv1(x) x = self.conv2(x) x = x.view(x.size(0), -1) output = self.out(x) return output, x 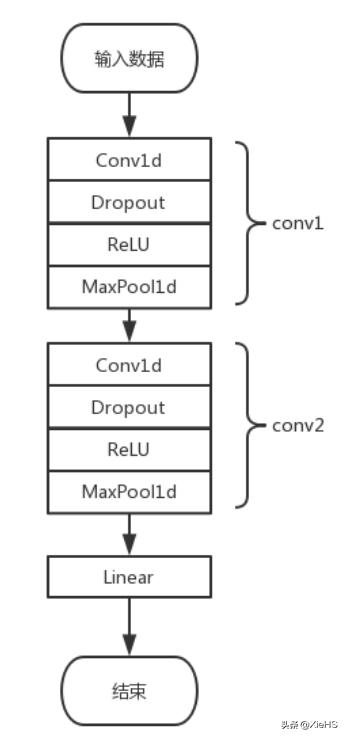
我們打印出模型如下:
1) 讀數據,裝載數據,隨機批量分配
2) 初始化自定義的模型類
3) 定義優化器【SGD,自適應優化算法(RMSProp,Adam,Adadelta)】和損失函數【MSE(回歸),crossEntropy(分類)】
4) 定義epoch數量,for循環訓練模型
# 初始化自定義的模型類 model = CNN() model.verbose = False#運行的時候不顯示詳細信息 # 定義優化器和損失函數 LR = 0.001 optimizer = torch.optim.Adam(model.parameters(), lr=LR) loss_func = torch.nn.CrossEntropyLoss() for epoch in range(n_epoch): model.train() for batch_idx, batch in enumerate(dataloader): input_x, input_y = tuple(batch) pred = model(input_x)[0] loss = loss_func(pred, input_y) optimizer.zero_grad()#梯度置零 loss.backward() #optimizer.step()是大多數optimizer所支持的簡化版本。一旦梯度被如backward()之類的函數計算好后,就可以調用這個函數更新所有的參數。 optimizer.step() step += 1 # test model.eval()#為了固定BN和dropout層,使得偏置參數不隨著發生變化pytorch distributed,訓練需要注意的幾點:
1) 反向傳播之前,優化器的梯度需要置零
2) optimizer.step()是大多數optimizer所支持的簡化版本。一旦梯度被如backward()之類的函數計算好后,就可以調用這個函數更新所有的參數
3) model.eval()#訓練完train_datasets之后,model要用來測試樣本,model.eval()為了固定BN和dropout層,使得偏置參數不隨著發生變化
完整的代碼https://github.com/XieHanS/CPSC_ECGHbClassify_demo.git
版权声明:本站所有资料均为网友推荐收集整理而来,仅供学习和研究交流使用。

工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态