azure
The real-life requirement
現實生活中的需求
Disclaimer: I assume dear Reader, that you are more than familiar with the general concept of partitioning and star schema modeling. The intended audience is people who used to be called BI developers in the past (with a good amount of experience), but they have all sorts of different titles nowadays that I can’t keep up with… I won’t provide a full Visual Studio solution that you can download and just run without any changes or configuration, but I will give you code can be used after parameterizing according to your own environment.
免責聲明:親愛的讀者,我想您對分區和星型模式建模的一般概念非常熟悉。 目標受眾是過去曾經被稱為BI開發人員( 具有豐富的經驗 )的人,但是如今他們擁有各種各樣的頭銜,我無法跟上……我不會提供完整的Visual您可以下載Studio解決方案,并且無需進行任何更改或配置即可直接運行它,但是我將為您提供可以根據您自己的環境進行參數化后使用的代碼。
So, with that out of the way, let’s start with some nostalgia: who wouldn’t remember all the nice and challenging partitioning exercises for OLAP cubes? 🙂 If you had a huge fact table with hundreds of millions of rows it was at least not an efficient option to do a full process on the measure group every time, but more often it was out of the question.
因此,從某種意義上說,讓我們從懷舊開始:誰不記得OLAP多維數據集所有出色而富挑戰性的分區練習了? 🙂如果您有一個龐大的事實表,其中包含成千上萬的行,那么,這至少不是每次對度量值組執行完整過程的有效選擇,但更多時候是不可能的。
In this example, I have a fact table with 500M+ rows that is updated hourly and I created monthly partitions. It is a neat solution and the actual processing takes about 3-4 minutes every hour, mostly because some big degenerate dimensions I couldn’t push out of scope. The actual measure group processing is usually 1-2 minutes and mostly involves 1-3 partitions.
在此示例中,我有一個包含500M +行的事實表,該表每小時更新一次,并創建每月分區。 這是一個很好的解決方案,實際處理每小時大約需要3-4分鐘,這主要是因為我無法排除某些較大的退化尺寸。 實際的度量值組處理通常為1-2分鐘,并且主要涉及1-3個分區。
I know OLAP is not dead (so it is said) but not really alive either. One thing is for sure: it is not available as PaaS (Platform as a Service) in Azure. So, if you want SSAS in the Cloud, that’s tabular. I assume migration/redesign from on-premise OLAP Cubes to Azure Tabular models is not uncommon. In the case of a huge table with an implemented partitioning solution, that should be ported as well.
我知道OLAP并沒有死(據說),但也沒有真正存活。 可以肯定的是:它在Azure中不能作為PaaS(平臺即服務)使用。 因此,如果您想在云中使用SSAS,那就是表格 。 我認為從本地OLAP多維數據集到Azure Tabular模型的遷移/重新設計并不少見。 對于具有已實現分區解決方案的大型表,也應將其移植。
Where Visual Studio provided a decent GUI for partitioning in the OLAP world, it’s not the case for tabular. It feels like a beta development environment that has been mostly abandoned because the focus has been shifted to other products (guesses are welcome, I’d say it’s Power BI but I often find the Microsoft roadmap confusing especially with how intensely Azure is extending and gaining an ever growing chunk in Microsoft’s income).
Visual Studio在OLAP世界中為分區提供了不錯的GUI,而表格格式則不是這種情況。 感覺就像是一個Beta開發環境,由于重點已轉移到其他產品而被放棄了( 歡迎猜測,我想說的是Power BI,但我經常發現Microsoft的路線圖令人困惑,尤其是與Azure的擴展和獲取程度有多大的困惑。微軟收入中不斷增長的一塊 )。
In short: let’s move that dynamic partitioning solution from OLAP into Azure Tabular!
簡而言之:讓我們將動態分區解決方案從OLAP遷移到Azure Tabular!
Goal
目標
The partitioning solution should accommodate the following requirements:
分區解決方案應滿足以下要求:
The process of Dynamic Partitioning
動態分區的過程
Used technology
二手技術
My solution consists of the below components:
我的解決方案包含以下組件:
C# scripts inside SSIS utilizing TOM (Tabular Object Model) – used in this solution
SSIS中利用TOM(表格對象模型)的 C#腳本–在此解決方案中使用
No, the second one is not Jerry 🙂 I am not sure the two methods would get on well in that cat-mouse relationship…
不,第二個不是杰里(Jerry)🙂我不確定這兩種方法在貓鼠關系中能否相得益彰……
Let’s get to it, going through the steps from the diagram one-by-one!
讓我們開始吧,一步一步地完成圖中的步驟!
Overview
總覽
The below objects are used in the solution.
解決方案中使用了以下對象。
| Object name | Type | ?Functionality |
| ETL_Tabular_Partition_Config | Table | Stores metadata for partitions that are used when defining the new ones |
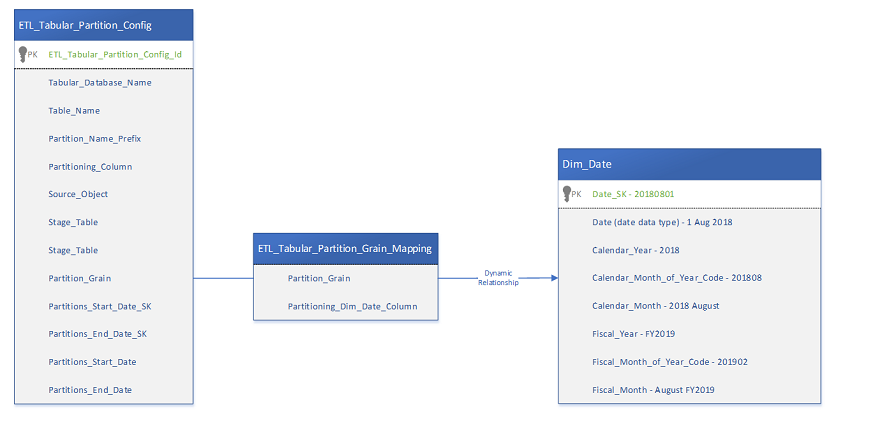
| ETL_Tabular_Partition_Grain_Mapping | Table | A simple mapping table between conceptual partition periods (e.g. Fiscal Month) and the corresponding Dim_Date column (e.g. Fiscal_Month_Code), this allows to tune partitioning periods dynamically |
| Dim_Date | Table | A fairly standard, pre-populated date table |
| ETL_Tabular_Partitions_Required | Table | The master list of changes for partitions, including all that needs to be created / deleted / processed (updated) |
| pr_InsertTabularPartitionsRequired | Stored procedure | That’s the heart of the SQL side of dynamic partitioning (details below) |
| ETL_Tabular_Partitions_Existing | Table | A simple list of partitions that currently exist in the deployed database |
| pr_InsertTabularPartitionsExisting | Stored procedure | A simple procedure that inserts a row into ETL_Tabular_Partitions_Existing and is called from a C# enumerator that loops through the existing partitions of the tabular database |
| Tabular_Partition.dtsx | SSIS package | This SSIS package is used as an orchestration of the different components of the project. In this 1st step the pr_InsertTabularPartitionsRequired stored procedure is called |
| 對象名稱 | 類型 | 功能性 |
| ETL_Tabular_Partition_Config | 表 | 存儲定義新分區時使用的分區的元數據 |
| ETL_Tabular_Partition_Grain_Mapping | 表 | 概念分區周期(例如,財政月)和相應的Dim_Date列(例如,Fiscal_Month_Code)之間的簡單映射表,這允許動態調整分區周期 |
| 點心日期 | 表 | 相當標準的預填充日期表 |
| ETL_Tabular_Partitions_Required | 表 | 分區更改的主列表,包括所有需要創建/刪除/處理(更新)的更改 |
| pr_InsertTabularPartitionsRequired | 存儲過程 | 這是動態分區SQL方面的核心(詳細信息如下) |
| ETL_Tabular_Partitions_Existing | 表 | 部署數據庫中當前存在的分區的簡單列表 |
| pr_InsertTabularPartitions現有 | 存儲過程 | 一個簡單的過程,將一行插入到ETL_Tabular_Partitions_Existing中,并從C#枚舉器調用,該循環遍歷表格數據庫的現有分區 |
| Tabular_Partition.dtsx | SSIS套件 | 此SSIS包用作項目不同組件的編排。 在該1 個工序中的pr_InsertTabularPartitionsRequired存儲過程被稱為 |
Date configuration
日期配置
For the date configuration, I use the ETL_Tabular_Partition_Config, the ETL_Tabular_Partition_Grain_Mapping and the Dim_Date table. A simplified version for demo purposes:
對于日期配置,我使用ETL_Tabular_Partition_Config,ETL_Tabular_Partition_Grain_Mapping和Dim_Date表。 出于演示目的的簡化版本:
TOM – Tabular Object Model
TOM –表格對象模型
I chose C# for this script’s language and the TOM (Tabular Object Model) objects are required to interact with tabular servers and their objects. To use them some additional references are needed on the server (if you use ADF and SSIS IR in the cloud, these are available according to the Microsoft ADF team) that are part of the SQL Server 2016 Feature Pack. You can find more info about how to install it here:
我選擇C#作為該腳本的語言,并且TOM(表格對象模型)對象是與表格服務器及其對象進行交互所必需的。 要使用它們,服務器上需要一些其他引用( 如果您在云中使用ADF和SSIS IR,根據Microsoft ADF團隊的要求,這些引用是SQL Server 2016 Feature Pack的一部分。 您可以在此處找到有關如何安裝的更多信息:
Install, distribute, and reference the Tabular Object Model
安裝,分發和引用表格對象模型
And the official TOM Microsoft reference documentation can be very handy:
官方的TOM Microsoft參考文檔可能非常方便:
Understanding Tabular Object Model (TOM) in Analysis Services AMO
了解Analysis Services AMO中的表格對象模型(TOM)
The part that is related specifically to the partitions:
與分區特別相關的部分:
Create Tables, Partitions, and Columns in a Tabular model
在表格模型中創建表,分區和列
Variables
變數
The below variables are needed to be passed from the package to the script:
需要將以下變量從包傳遞到腳本:
Make sure you include the above variables, so they can be used in the script later on:
確保包括上述變量,以便稍后可以在腳本中使用它們:
The syntax for referencing them (as it’s not that obvious) is documented here:
引用它們的語法(不太明顯)在此處記錄:
Using Variables in the Script Task
在腳本任務中使用變量
Main functionality
主要功能
The script itself does nothing else but loops through all existing partitions and calls a stored procedure row-by-row that inserts the details of that partition into a SQL table.
該腳本本身不執行其他任何操作,而是循環遍歷所有現有分區并逐行調用存儲過程,該存儲過程將該分區的詳細信息插入到SQL表中。
All this logic is coded into pr_InsertTabularPartitionsRequired (feel free to use a better name if you dislike this one) and in high level it does the following:
所有這些邏輯都編碼為pr_InsertTabularPartitionsRequired(如果您不喜歡此名稱,請隨意使用更好的名稱),并在較高級別執行以下操作:
Gray means T-SQL, white is C# (see the previous section), dark grey is putting everything together.
灰色表示T-SQL,白色表示C#( 請參閱上一節 ),深灰色表示將所有內容組合在一起。
Here is the code of my procedure, it works assuming you have the three tables defined previously and you configured the values according to your databases / tables / columns.
這是我的過程的代碼,假設您已預先定義了三個表,并且已根據數據庫/表/列配置了值,則該代碼可以正常工作。
pr_InsertTabularPartitionsRequired.sql
pr_InsertTabularPartitionsRequired.sql
It is mostly self-explanatory, and the inline comments can guide you as well. Some additional comments:
它主要是不言自明的,內聯注釋也可以指導您。 一些其他評論:
Additionally, a WHERE clause for each partition is defined which can be used later when it is time to actually create them.
另外,為每個分區定義了一個WHERE子句,稍后可以在實際創建它們時使用。
Again, back to the C# realm.
再次回到C#領域。
Code Confusion
代碼混亂
One particular inconsistency caught me as I had to spend half an hour to figure out why removing a partition has a different syntax then processing. It might be totally straightforward with people having a .NET background but different than how T-SQL conceptually work.
一個特別的不一致引起了我的注意,因為我不得不花半個小時來弄清楚為什么刪除分區的語法與處理語法不同。 對于具有.NET背景但與T-SQL在概念上不同的人,這可能是完全簡單的。
Tabular_Table.Partitions.Remove(Convert.ToString(Partition["Partition_Name"]));Tabular_Table.Partitions[Convert.ToString(Partition["Partition_Name"])].RequestRefresh(RefreshType.Full);
Conceptually
從概念上講
Source query for new partitions
源查詢新分區
How to assign the right query for each partition? Yes, we have the WHERE conditions in the ETL_Tabular_Partitions_Required table but the other part of the query is missing which has the date filtering to ensure there are no overlapping partitions. For that I use a trick (I am sure you can think of other ways, but I found this next one easy to implement and maintain): I have a pattern partition in the solution itself under source control. It has to be in line with the up-to-date view/table definitions otherwise the solution can’t be deployed as the query would be incorrect. I just need to make sure it always stays empty. For that a WHERE condition like 1=2 is sufficient enough (as long as the basic arithmetic laws don’t change). Its naming is “table name – pattern”
如何為每個分區分配正確的查詢? 是的,我們在ETL_Tabular_Partitions_Required表中具有WHERE條件,但缺少查詢的其他部分,該部分具有日期過濾功能以確保沒有重疊的分區。 為此,我使用了一個技巧( 我相信您可以想到其他方法,但是我發現下一個易于實現和維護 ):我在源代碼控制下的解決方案中有一個模式分區。 它必須與最新的視圖/表定義保持一致,否則該解決方案將無法部署,因為查詢將不正確。 我只需要確保它始終為空即可。 為此, 只要 1 = 2這樣的WHERE條件就足夠了( 只要基本算術定律不變 )。 它的名稱是“ 表名-模式 ”
Then I look for that partition (see the details in the code at the end of the section), extract its source query, strip off the WHERE condition and then when looping through the new partitions, I just append the WHERE clause from the ETL_Tabular_Partitions_Required table.
然后,我尋找該分區( 請參閱本節末尾的代碼中的詳細信息 ),提取其源查詢,剝離WHERE條件,然后在遍歷新分區時,只需從ETL_Tabular_Partitions_Required表中追加WHERE子句。
string Tabular_Table_Name = "your table name";
string Tabular_Partition_Pattern_Name = Tabular_Table_Name + " - pattern";
//connect to tabular model
var Tabular_Server = new Server();
string Tabular_ConnStr = "your connection string";Tabular_Server.Connect(Tabular_ConnStr);
Database Tabular_Db = Tabular_Server.Databases[Tabular_Database_Name];
Model Tabular_Model = Tabular_Db.Model;
Table Tabular_Table = Tabular_Model.Tables[Tabular_Table_Name];Partition Patter_Partition = Tabular_Table.Partitions.Find(Tabular_Partition_Pattern_Name);
Note: I use SQL queries not M ones in my source but here’s the code that helps you get both types from the tabular database’s partition using .NET once you have identified the proper partition that contains the pattern:
注意:我在源代碼中使用的不是SQL查詢,但下面的代碼可幫助您在確定包含模式的適當分區后使用.NET從表格數據庫分區中獲取兩種類型的代碼:
For SQL
對于SQL
string Partition_Pattern_Query_SQL=
((Microsoft.AnalysisServices.Tabular.QueryPartitionSource)
(Pattern_Partition.Source.Partition).Source).Query.ToString();
For M
對于M
string Partition_Pattern_Query_M =
((Microsoft.AnalysisServices.Tabular.CalculatedPartitionSource)
(Pattern_Partition.Source.Partition).Source).Query.ToString();
Script steps
腳本步驟
Now I have the first half of the SQL query, I have the building blocks for this last step of the partitioning process:
現在,我有了SQL查詢的前半部分,有了分區過程的最后一步的構建塊:
Don’t forget that after the loop the tabular model must be saved and that is when all the previously issued commands are actually executed at the same time:
不要忘記在循環之后必須保存表格模型,也就是說,實際上同時執行了所有先前發出的命令:
Tabular_Model.SaveChanges();
The code bits that you can customize to use in your own environment:
您可以自定義以在自己的環境中使用的代碼位:
PartitionActions.TOM.cs
分區動作.TOM.cs
So, by now you should have an understanding of how partitioning works in tabular Azure Analysis Services and not just how the processing can be automated but the creation / removal of the partitions based on configuration data (instead of just defining all the partitions beforehand until e.g. 2030 for all months).
因此,到目前為止,您應該已經了解分區在表格式Azure Analysis Services中的工作方式,不僅是如何自動化處理,而且還基于配置數據創建/刪除分區( 而不是僅預先定義所有分區,直到例如到2030年為止 )。
The scripts – as I said at the beginning – cannot be used just as they are due to the complexity of the Azure environment and that the solution includes more than just a bunch of SQL tables and queries: .NET scripts and Azure Analysis Services.
正如我一開始所說的那樣,由于Azure環境的復雜性,無法使用它們,因為該解決方案不僅僅包含一堆SQL表和查詢:.NET腳本和Azure Analysis Services。
I aimed to use generic and descriptive variable and column names, but it could easily happen that I missed the explanation of something that became obvious to me during the development of this solution. In that case please feel free to get in touch with me using the comments section or sending an email to mi_technical@vivaldi.net
我的目標是使用通用的和描述性的變量名和列名,但是很容易發生這種情況,因為我錯過了在開發此解決方案時對我來說顯而易見的解釋。 在這種情況下,請隨時使用評論部分與我聯系或發送電子郵件至mi_technical@vivaldi.net
Thanks for reading!
謝謝閱讀!
翻譯自: https://www.sqlshack.com/dynamic-partitioning-in-azure-analysis-services-tabular/
azure
版权声明:本站所有资料均为网友推荐收集整理而来,仅供学习和研究交流使用。

工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态










{kind=link}